Download as PDF, PPTX

















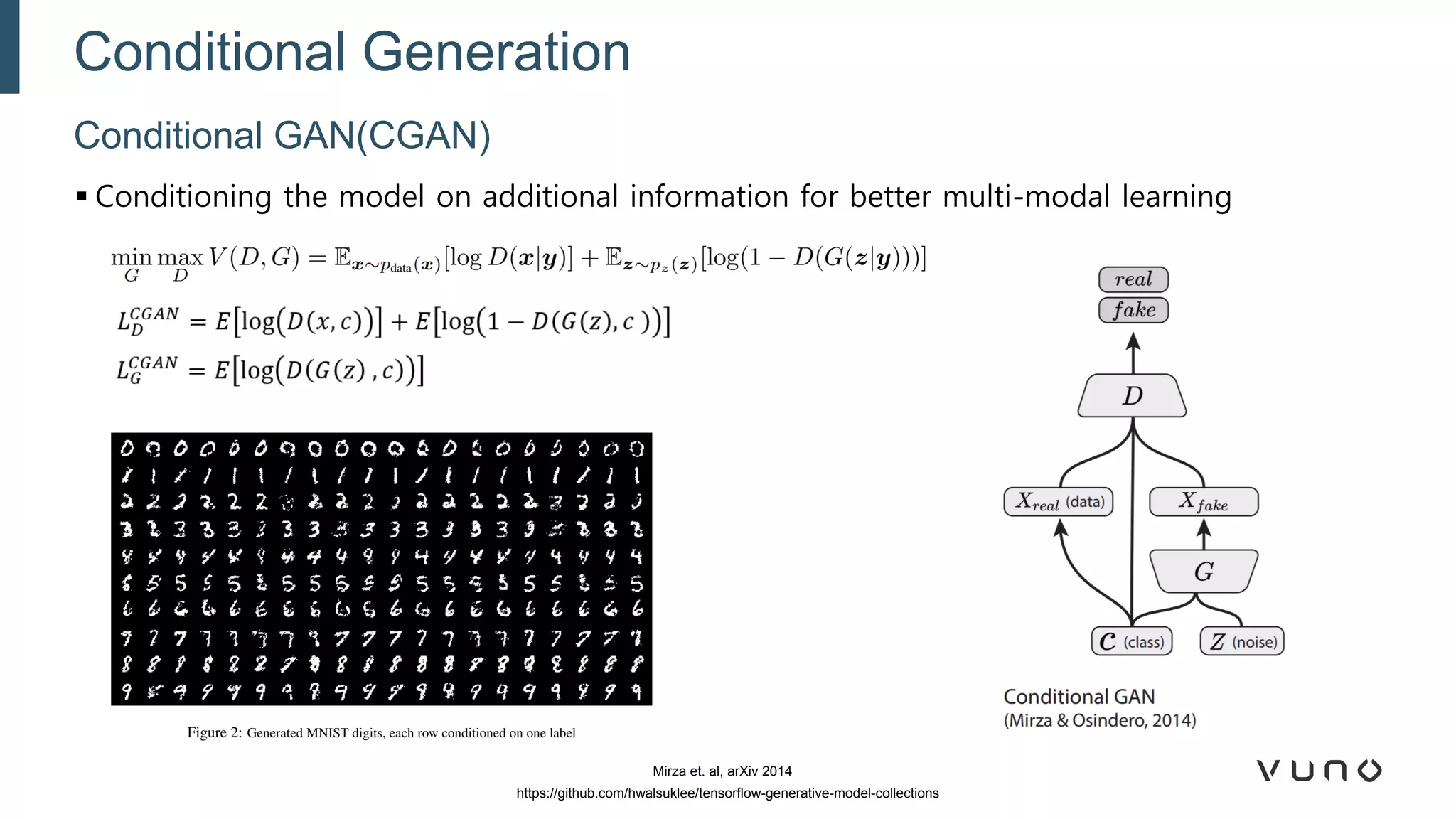
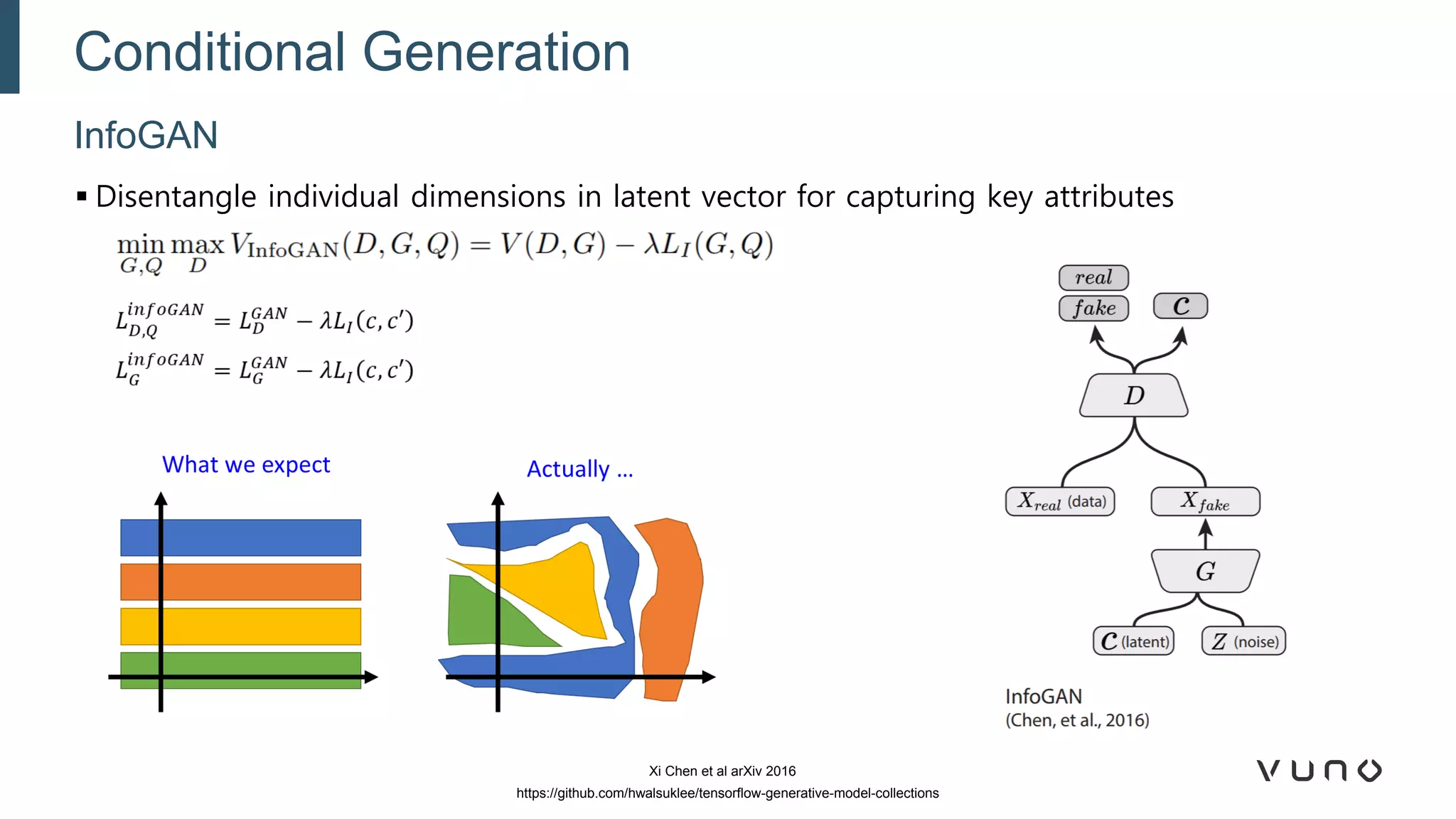



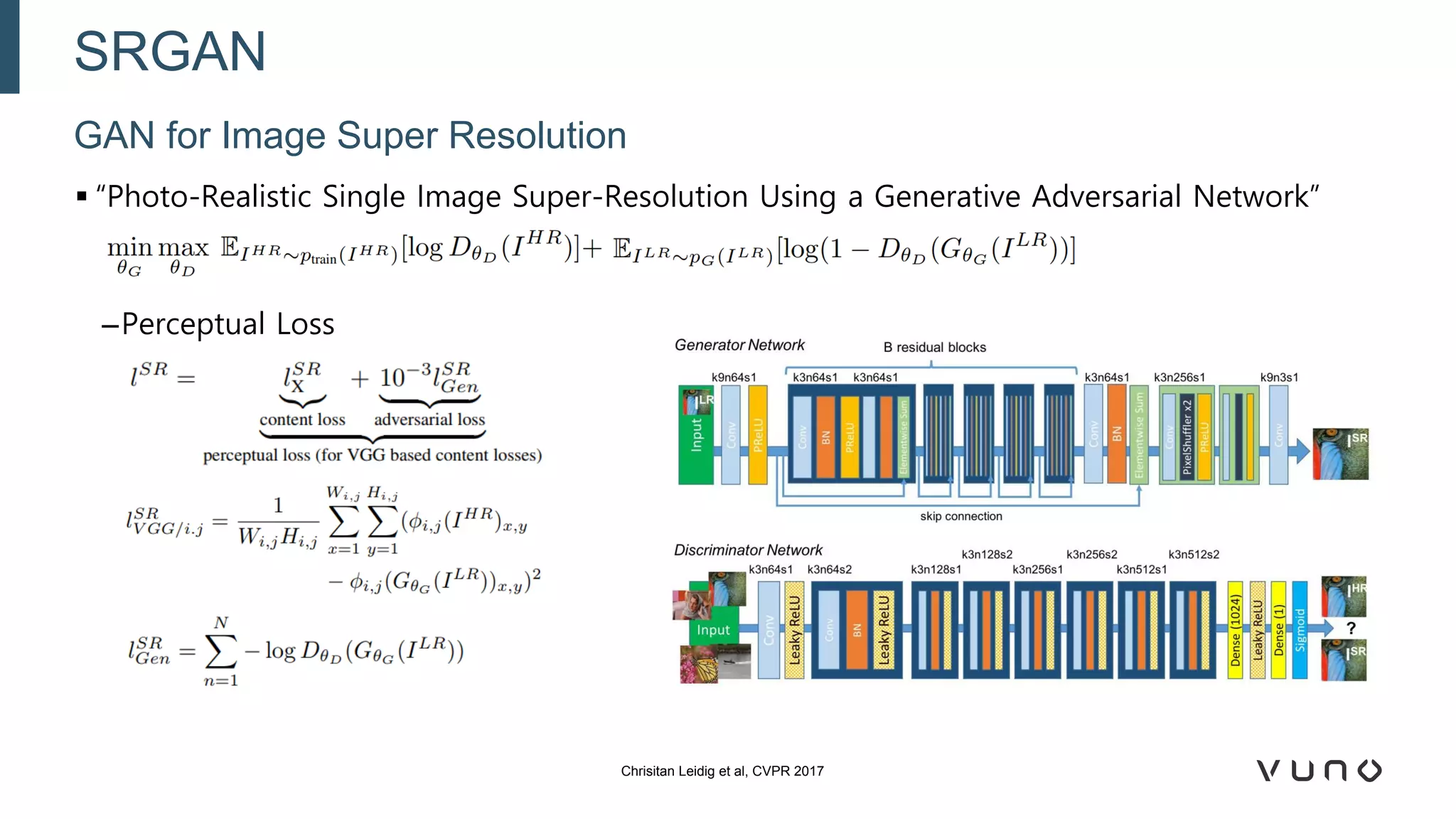





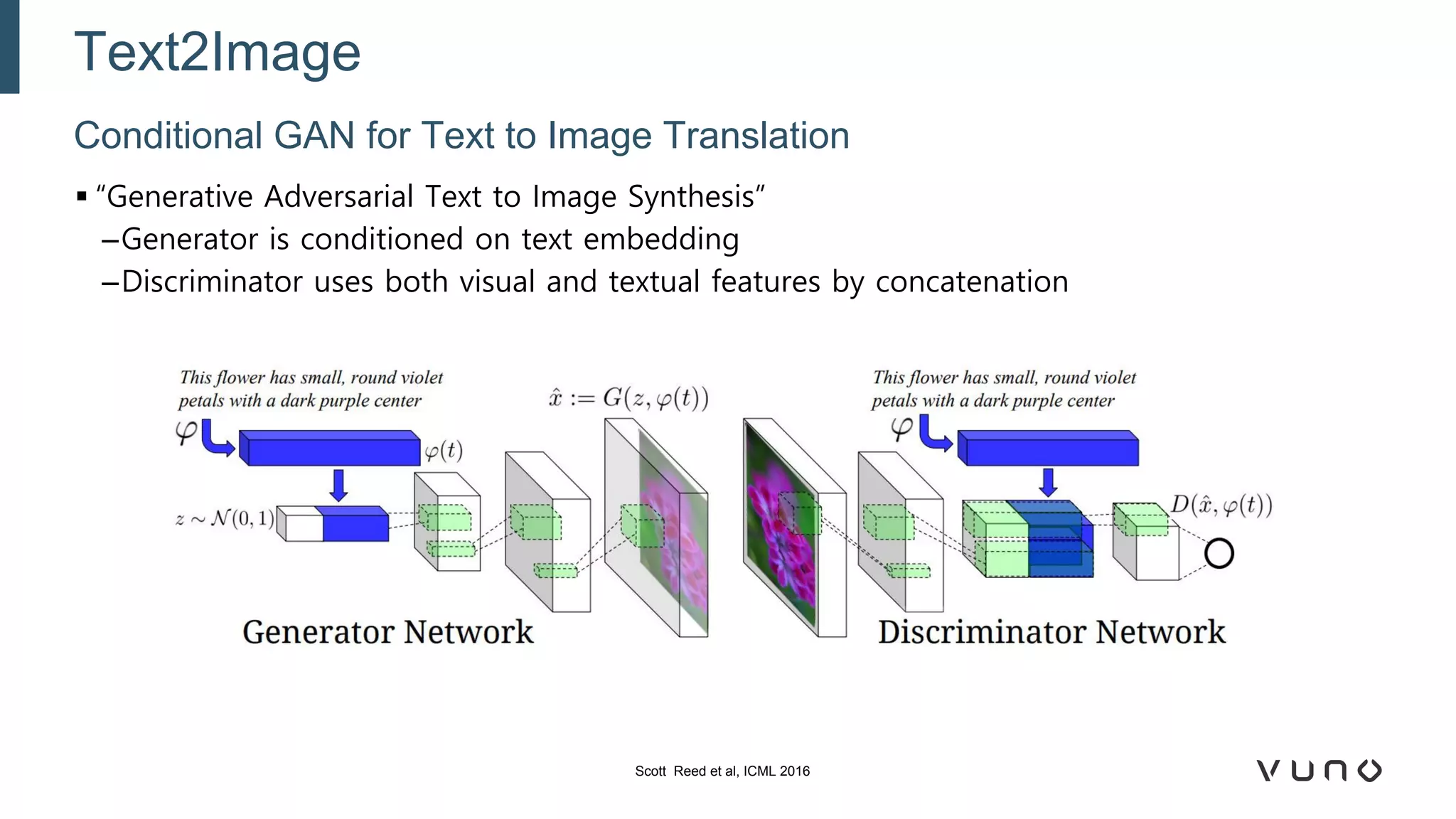

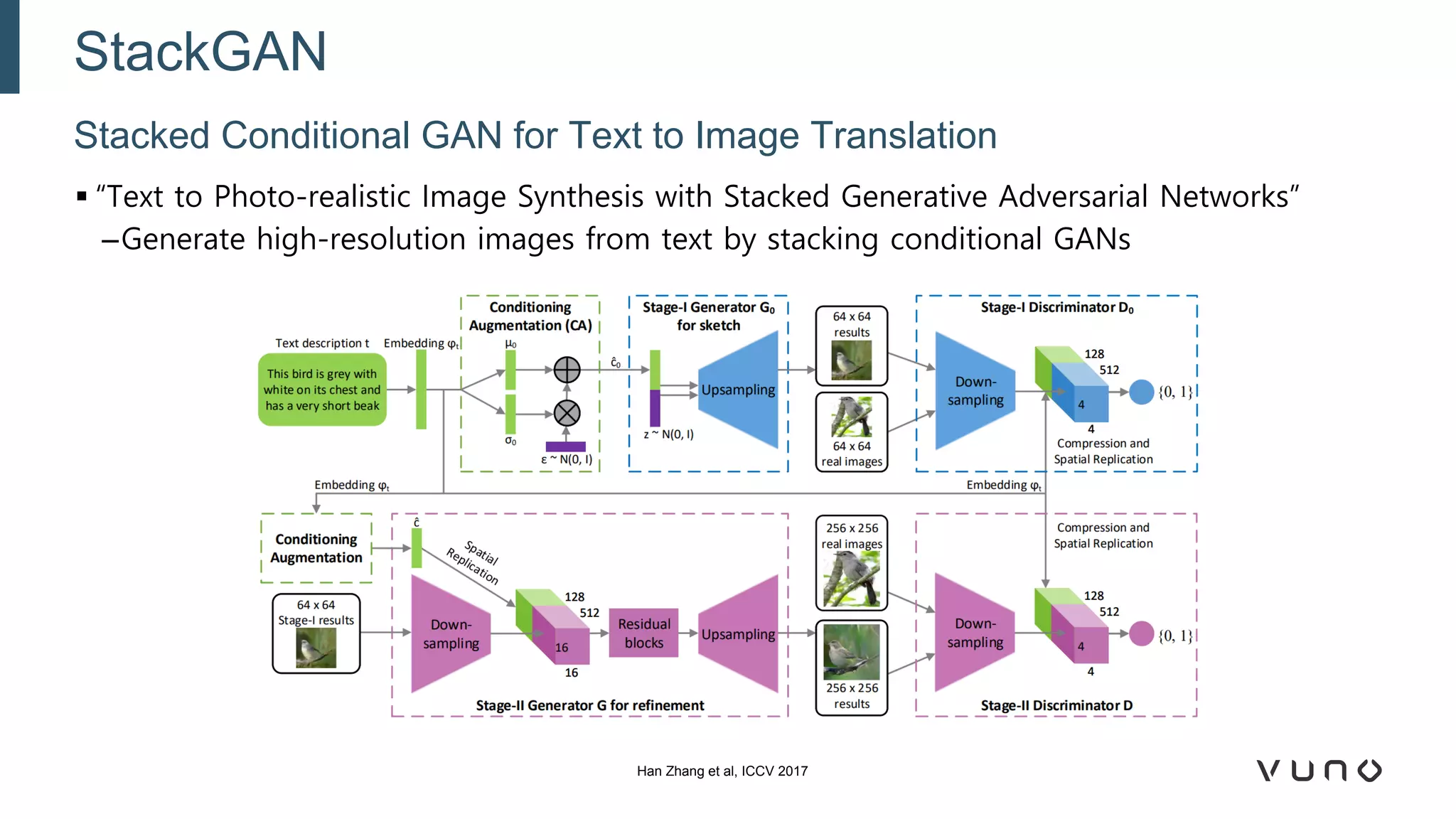


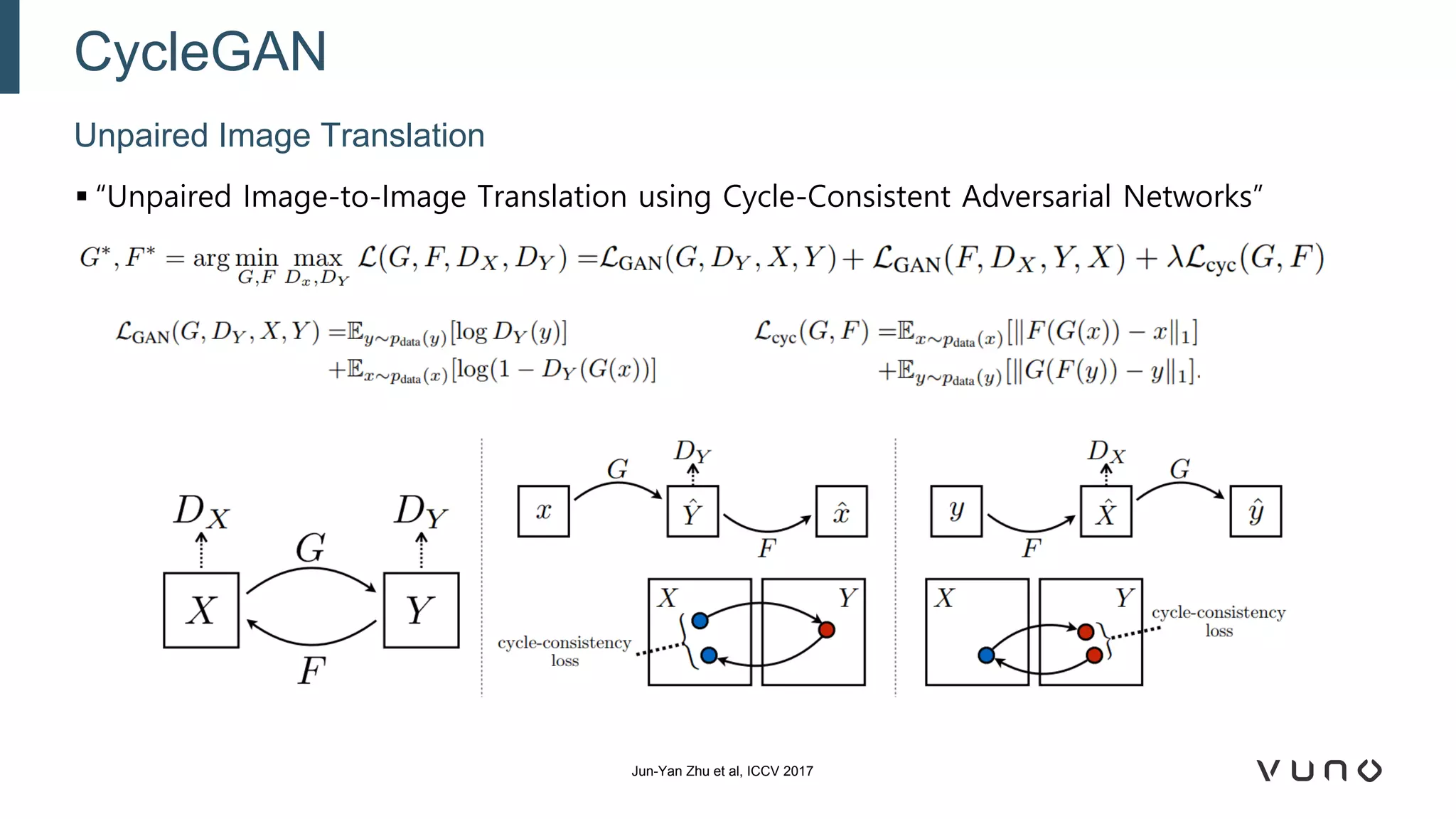


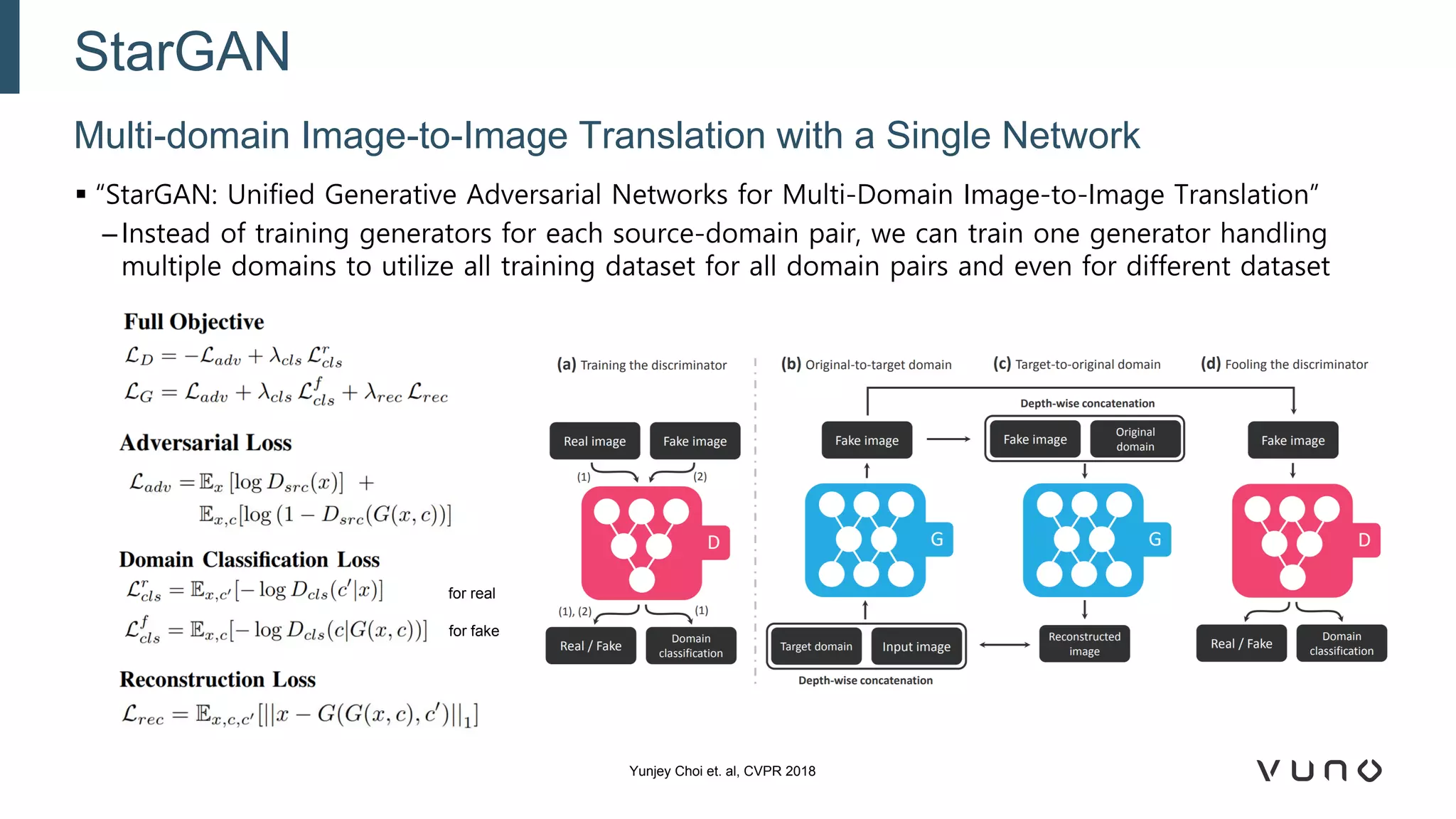
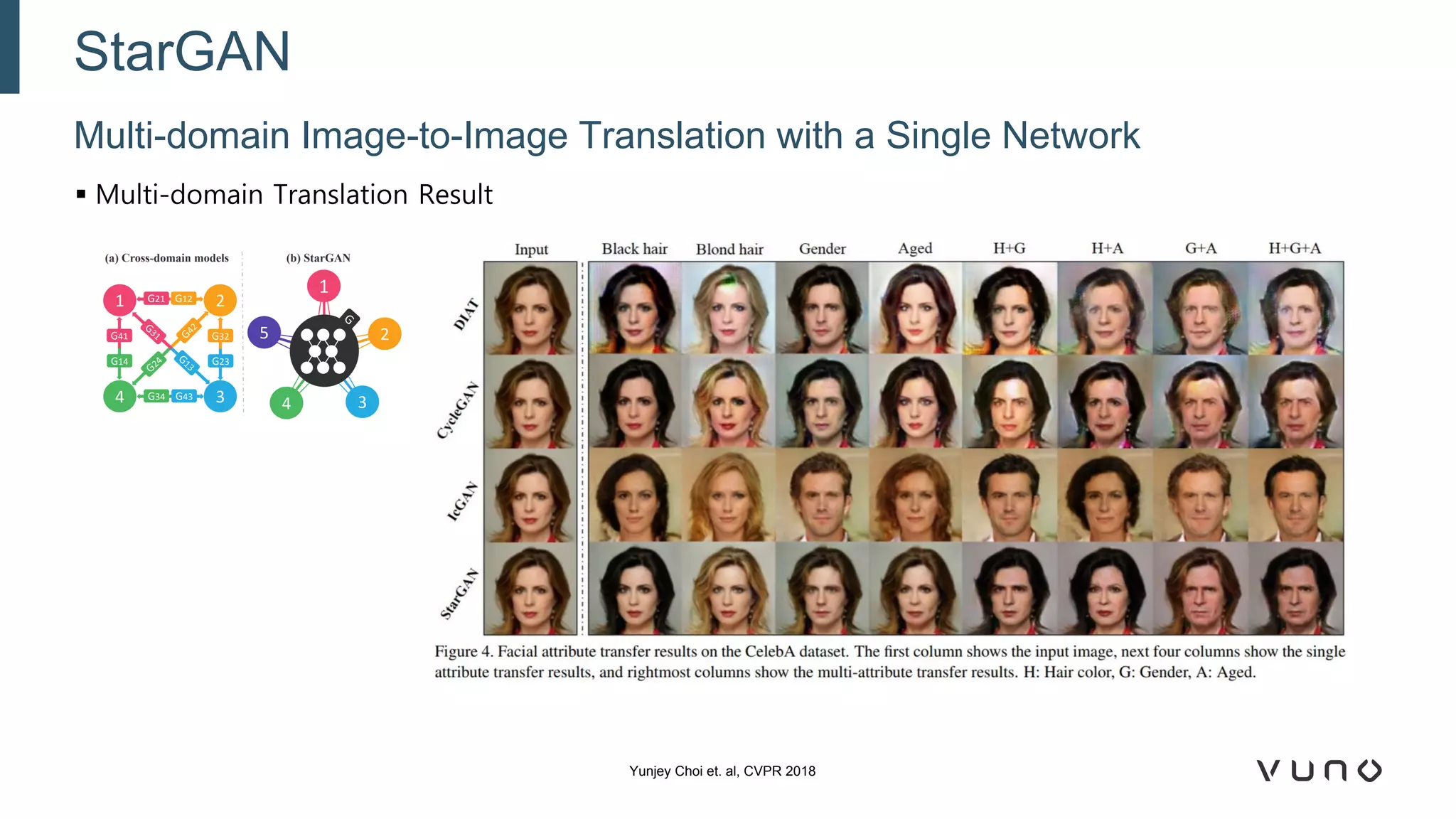
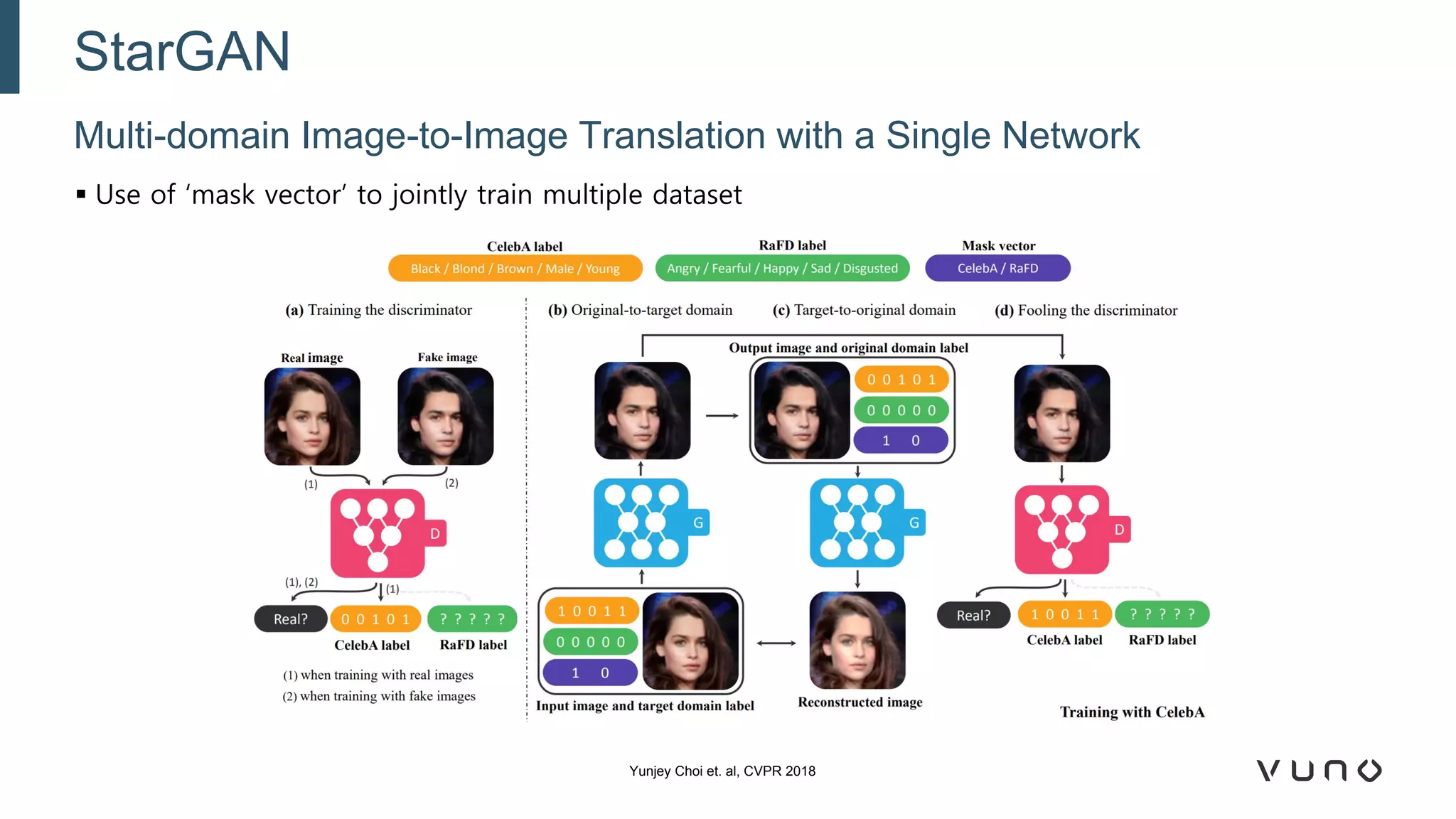
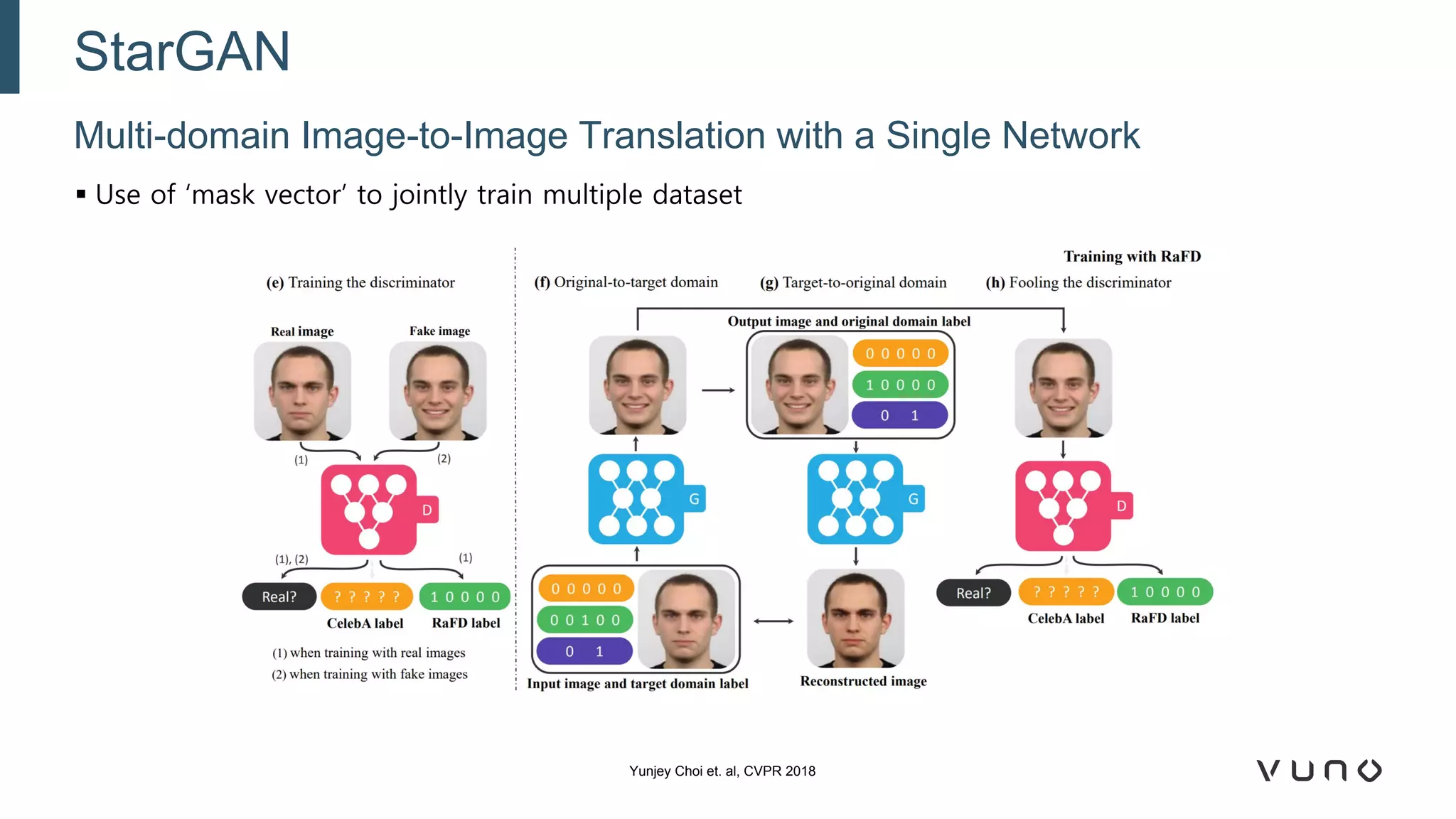

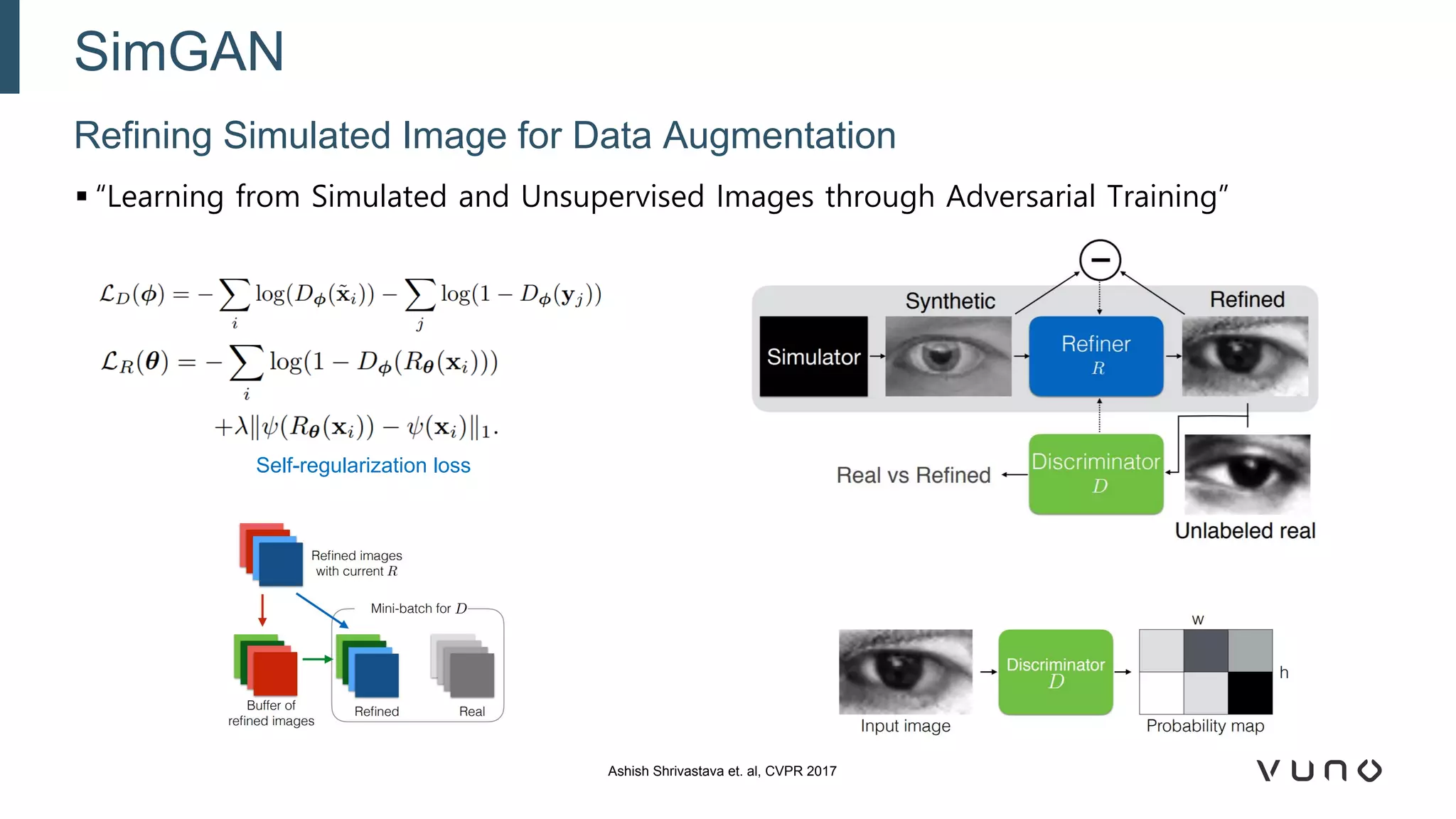
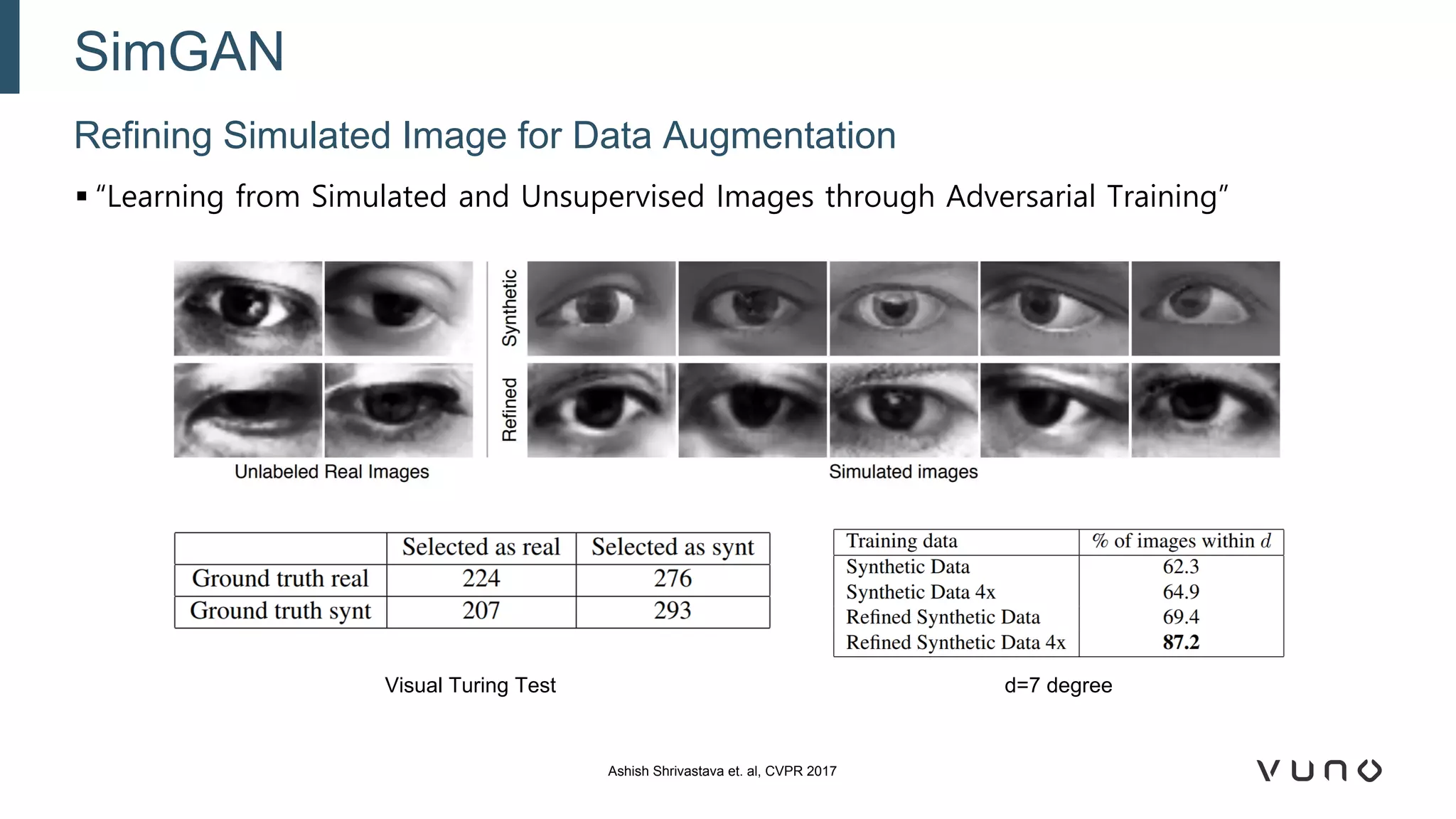


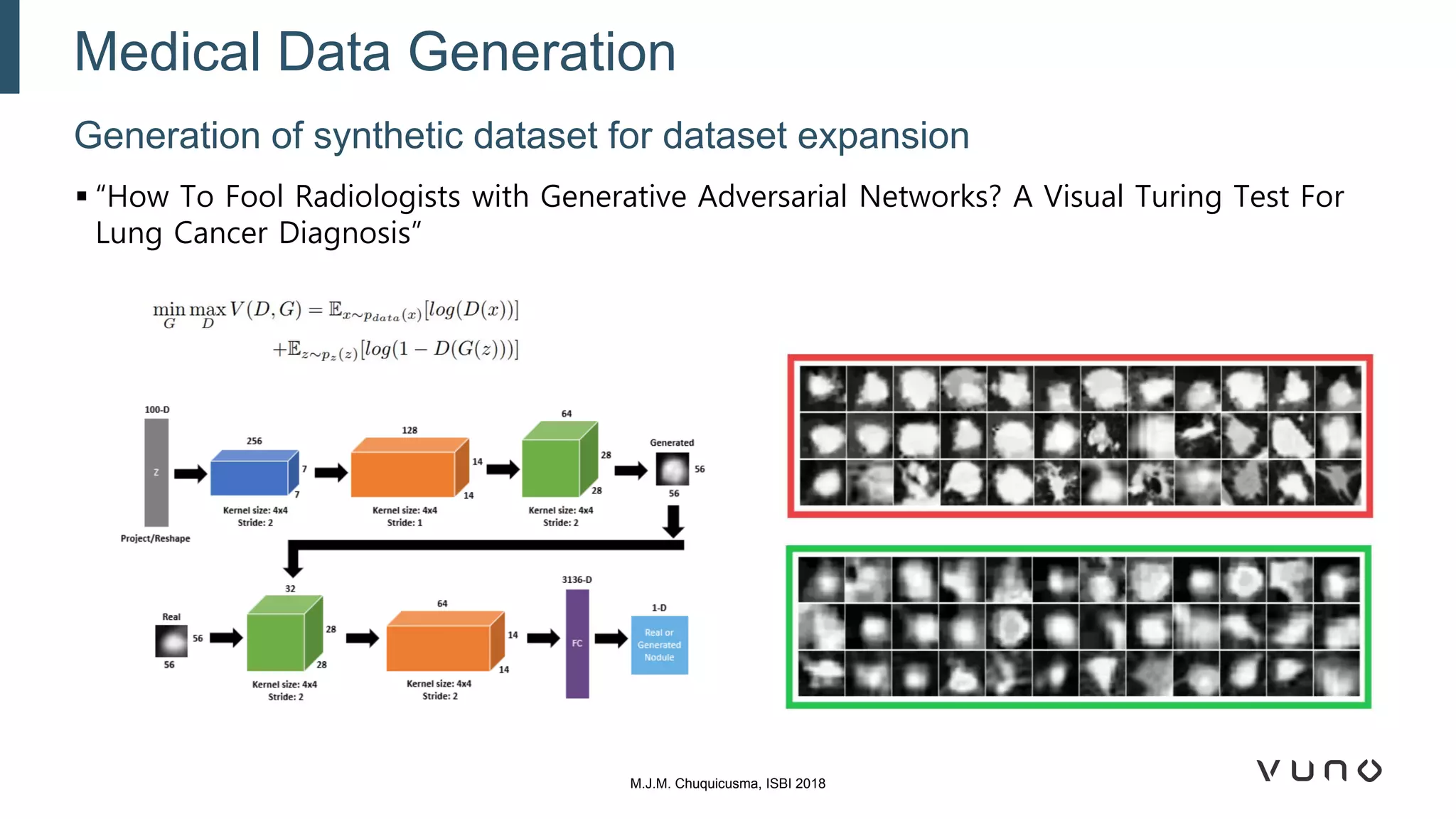
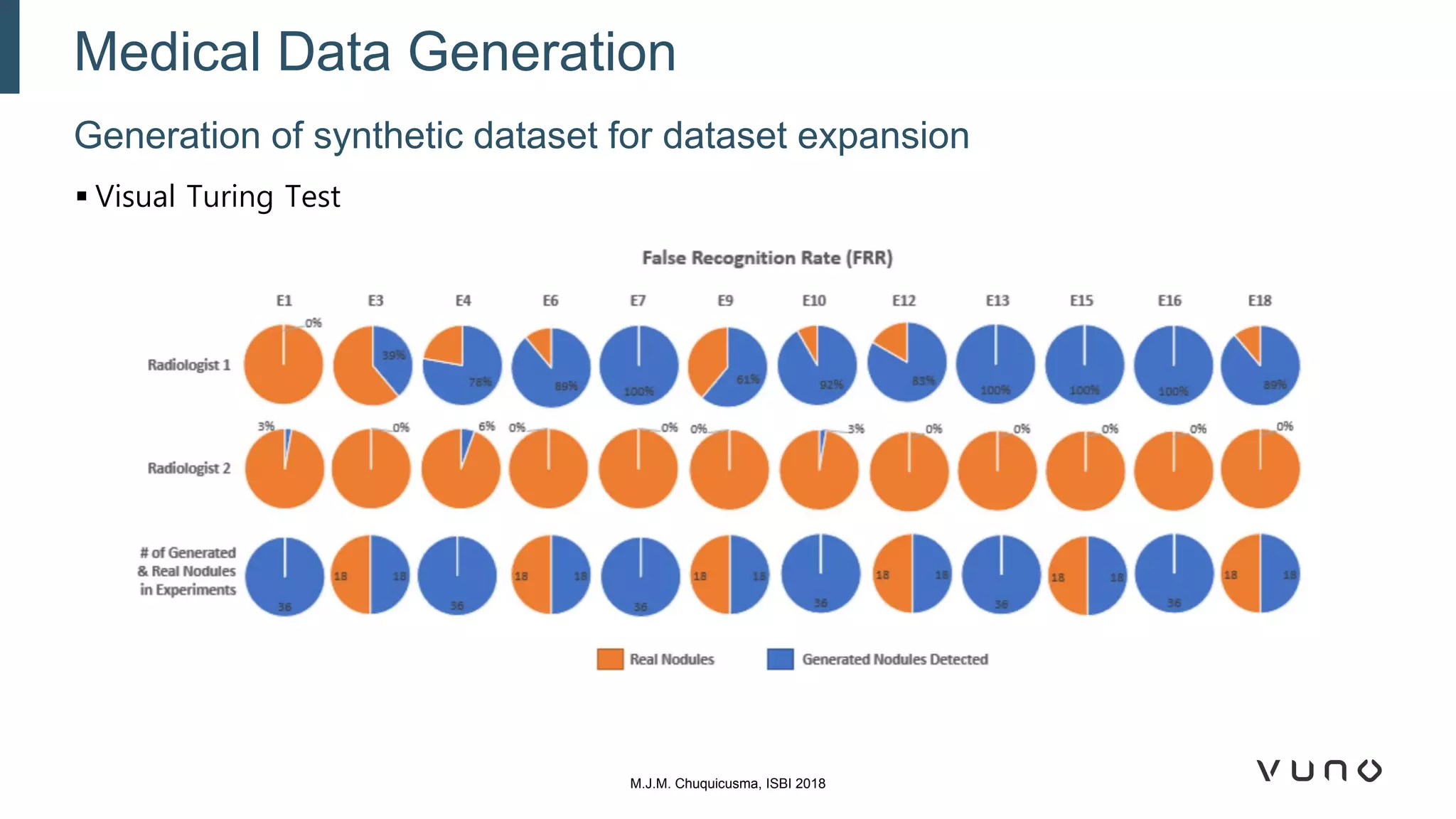
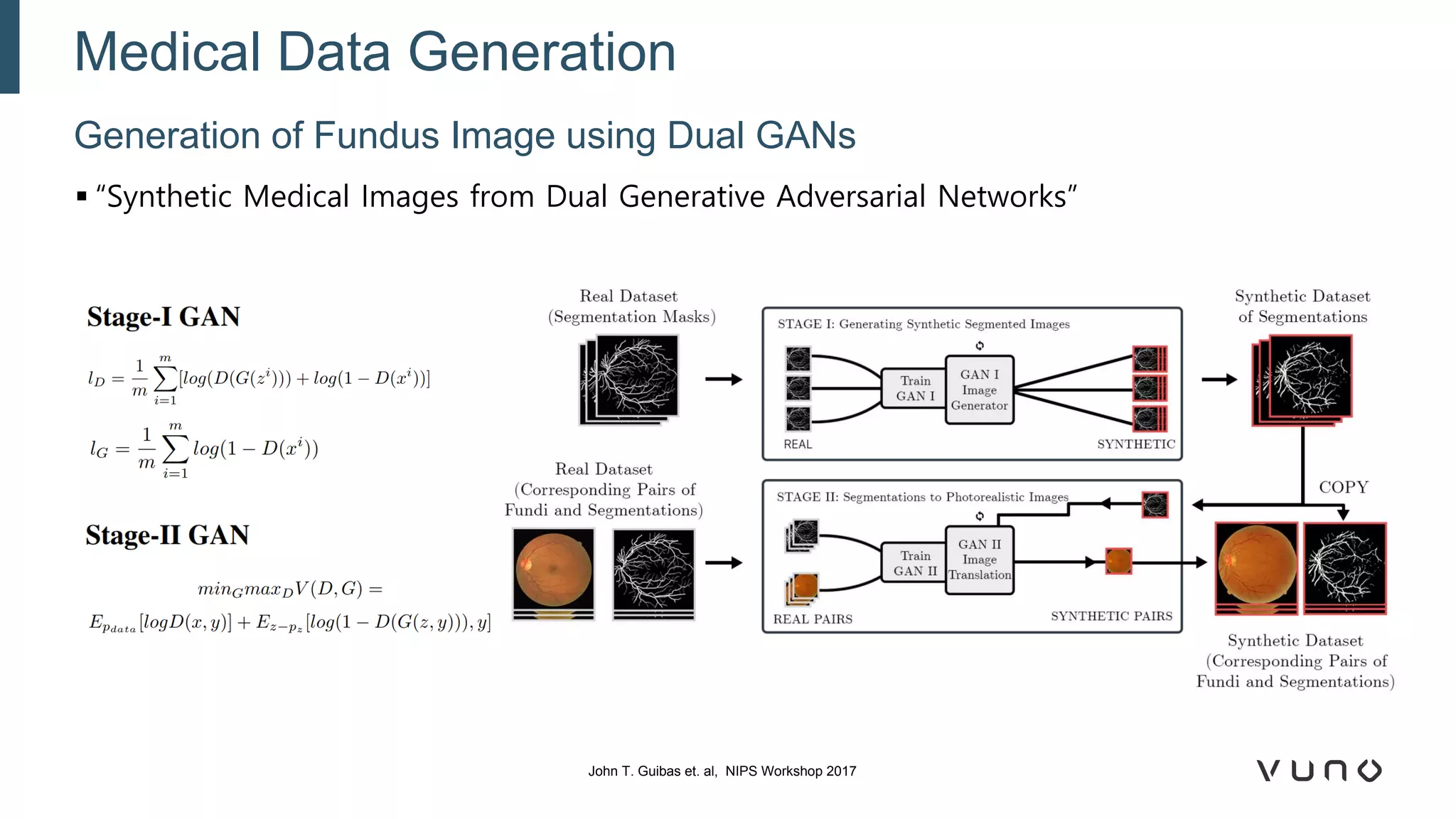
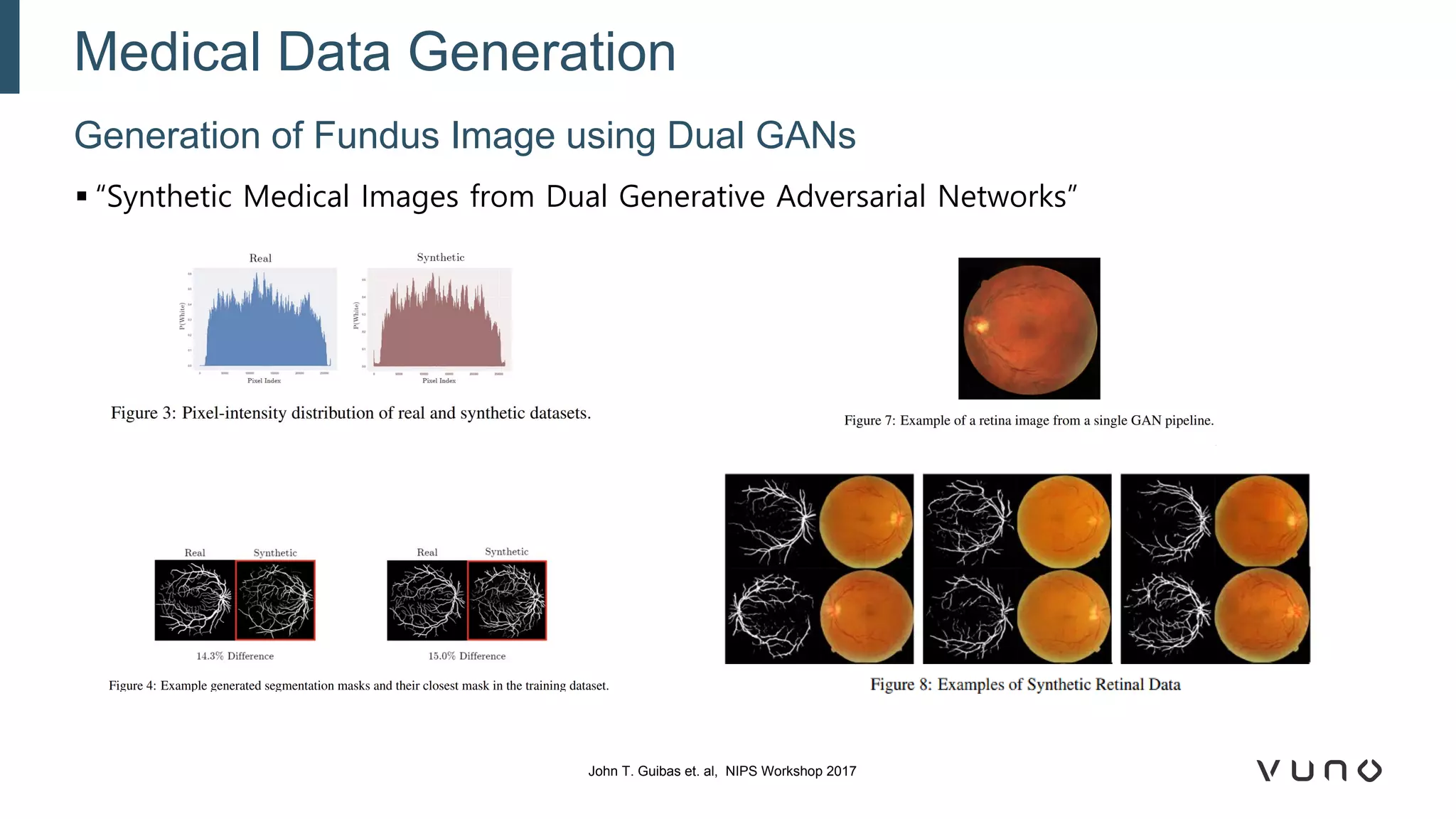
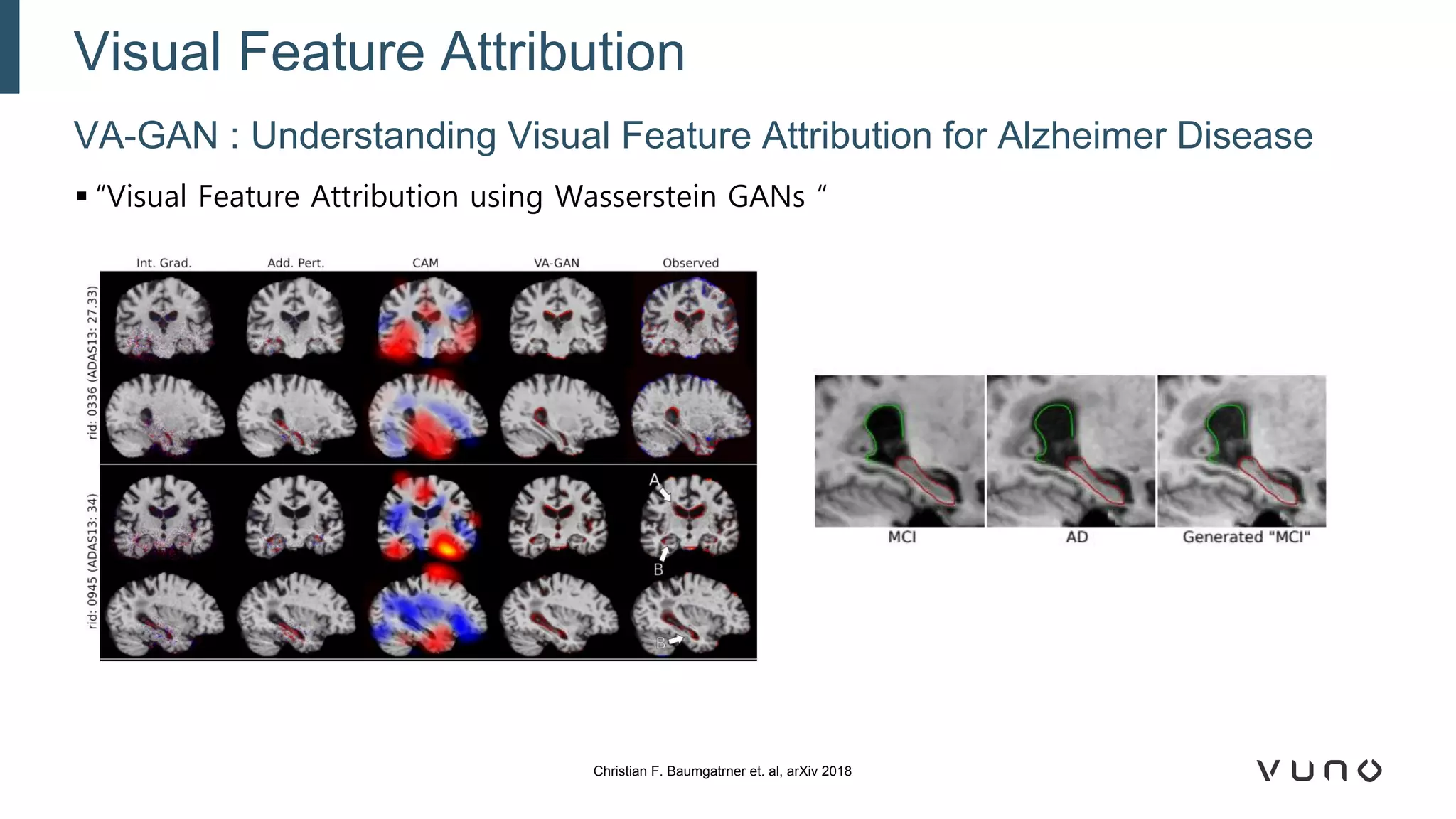
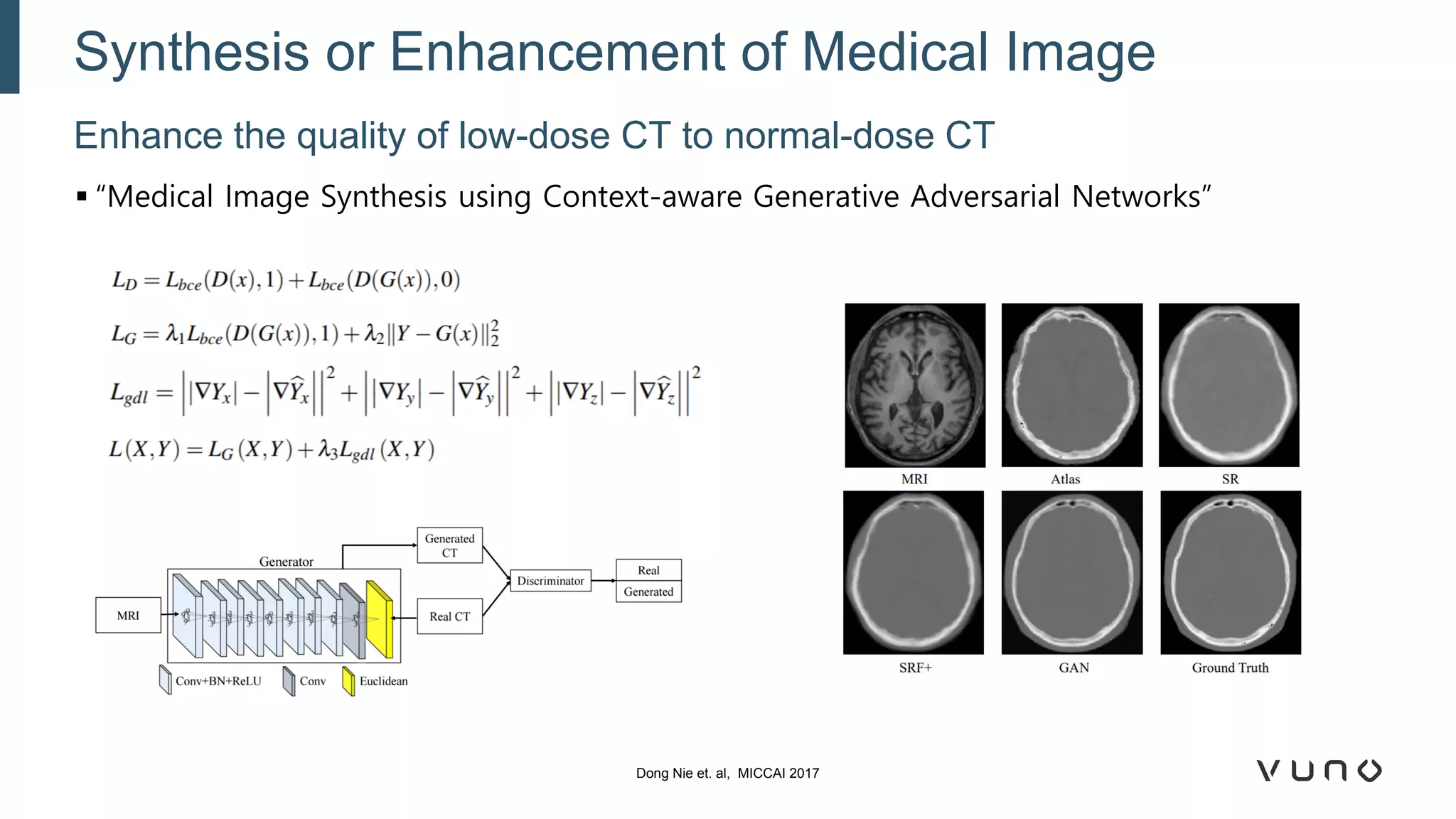
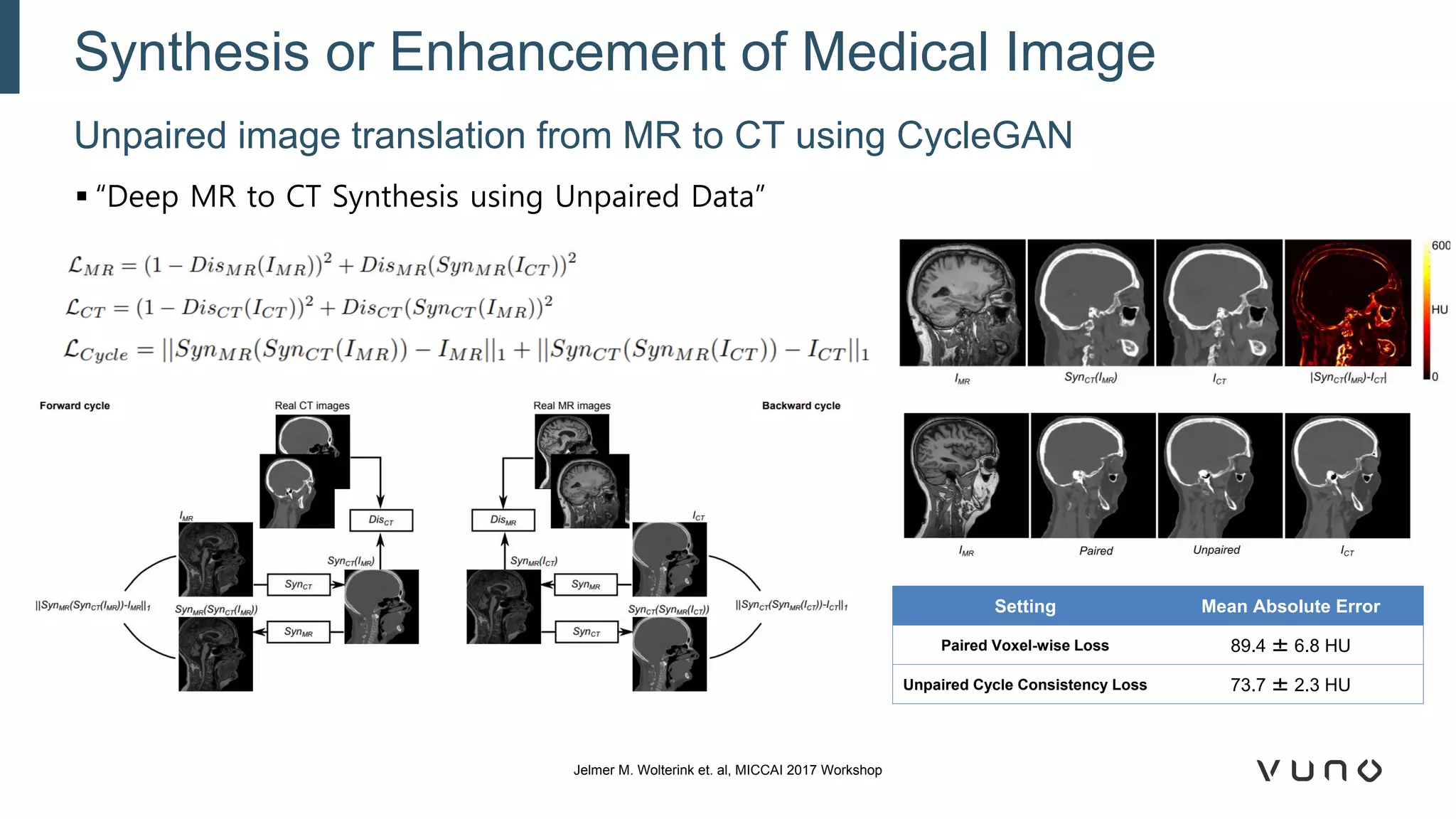
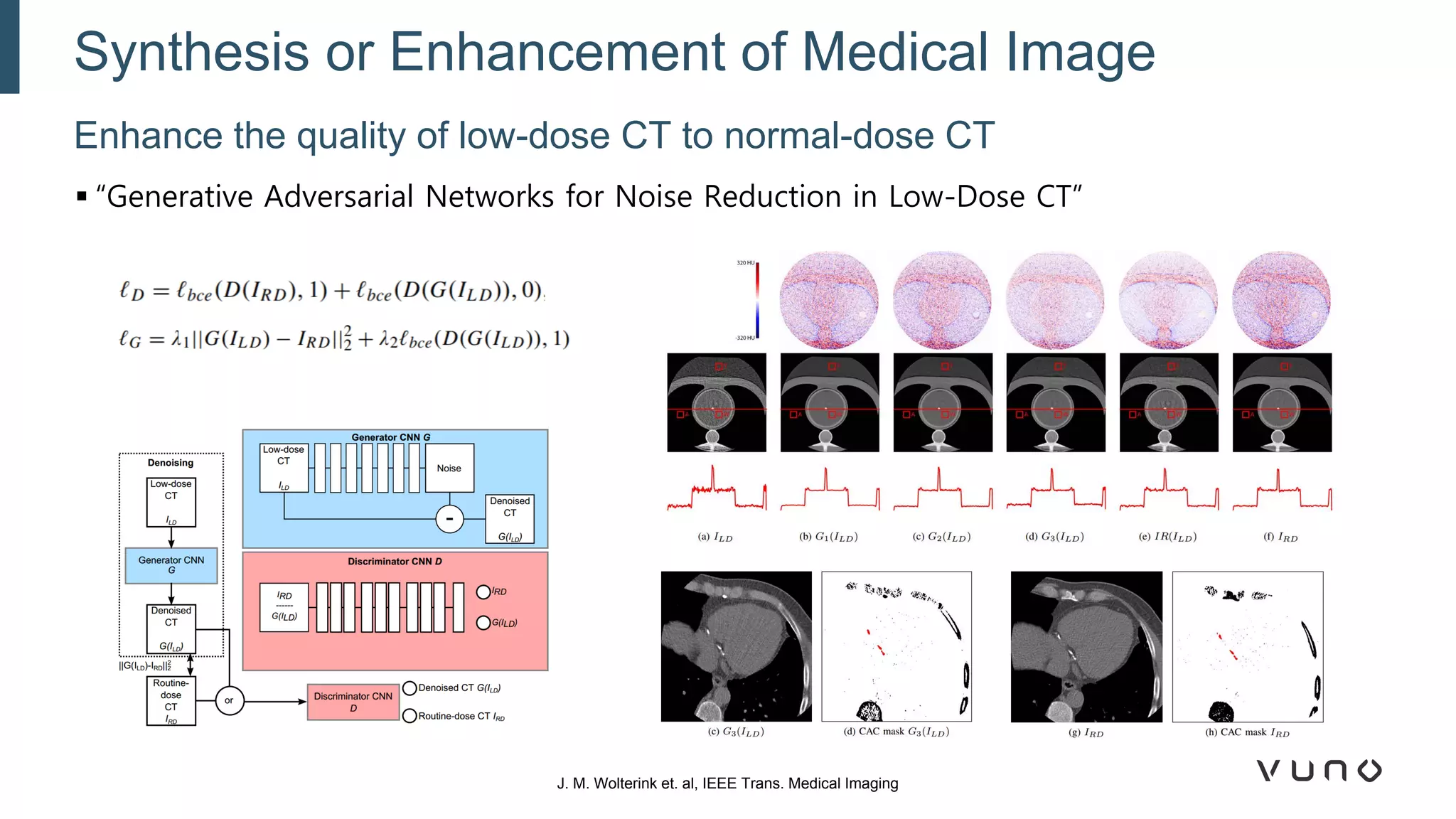

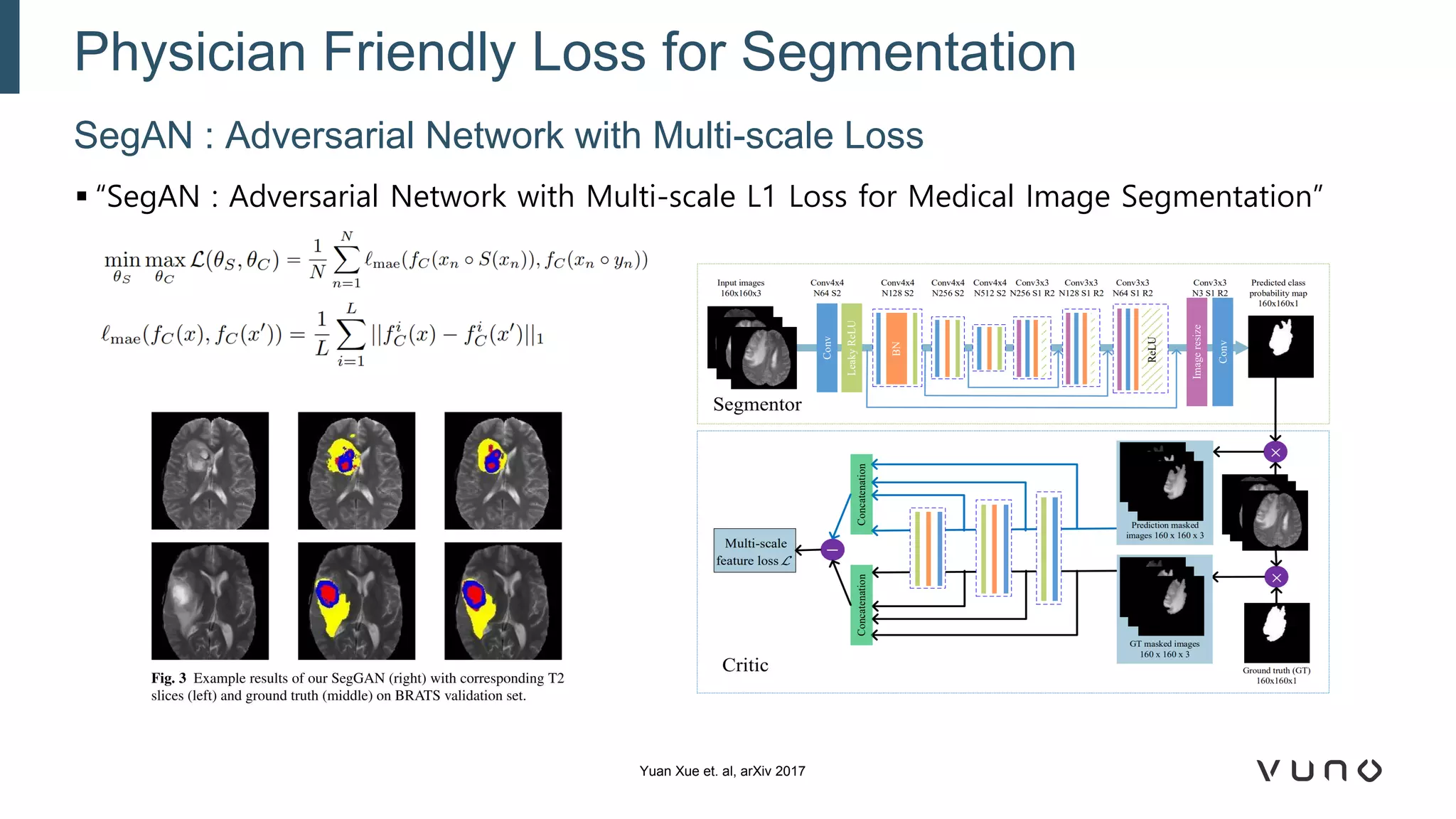
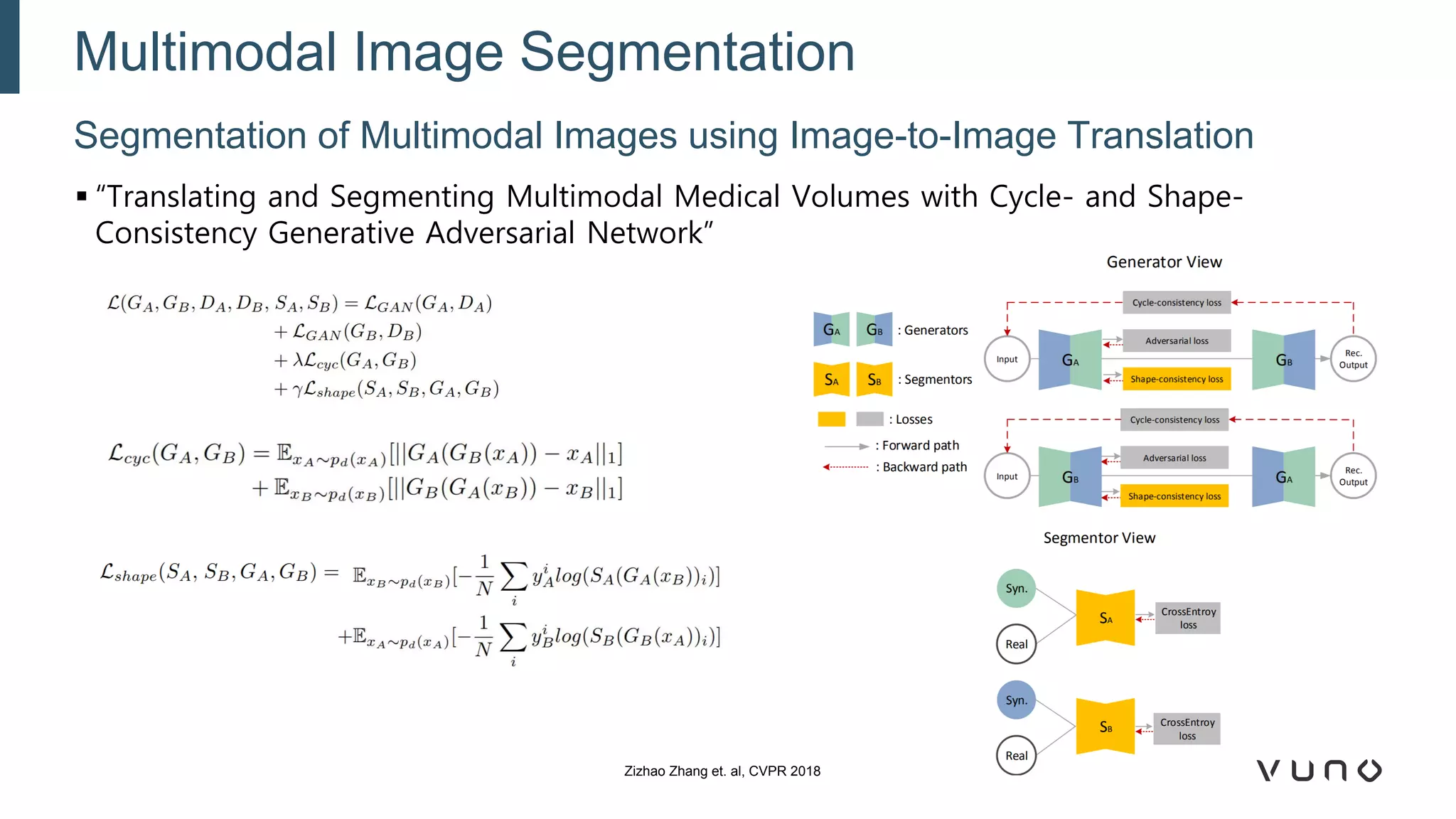
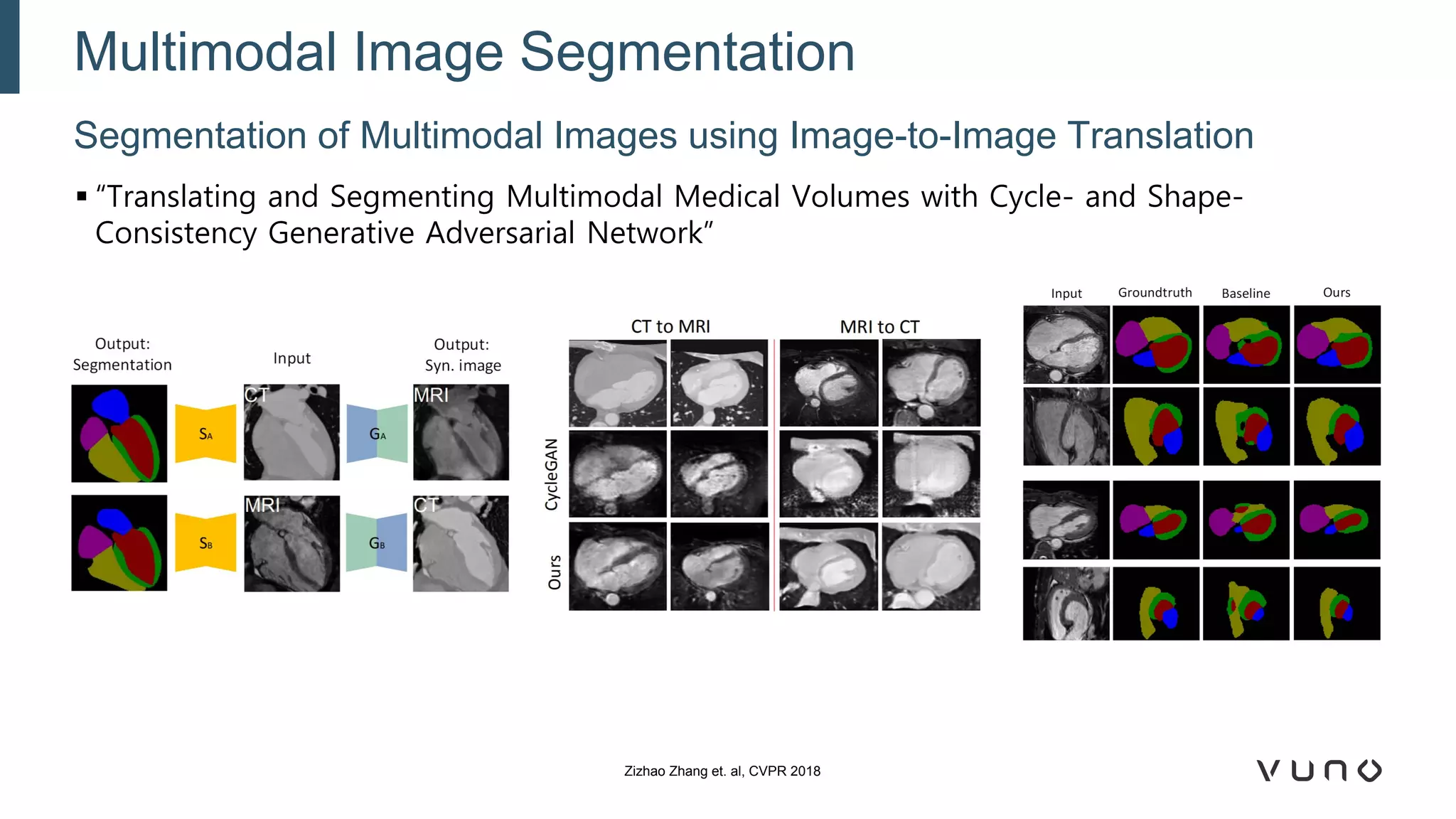



Generative adversarial networks (GANs) are a class of machine learning frameworks where two neural networks compete against each other. One network generates synthetic data while the other evaluates it as real or fake. GANs have been applied to medical imaging tasks like generating additional patient data, translating between image modalities, enhancing image quality, and segmenting anatomical structures. Recent advances include conditioning GANs on text or labels to control image attributes, unpaired image-to-image translation using cycle consistency, and training a single GAN to handle multiple image domains. GANs show promise for improving diagnostic models by providing more training data and enabling new applications like noise reduction and accelerated acquisition.







![[IJCAI 2023 - Poster] SemiGNN-PPI: Self-Ensembling Multi-Graph Neural Network...](https://cdn.slidesharecdn.com/ss_thumbnails/semignnppiposterfinal-zzyv2-230818024445-6f69bd9e-thumbnail.jpg?width=640&height=640&fit=bounds)



























































