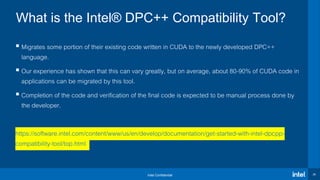
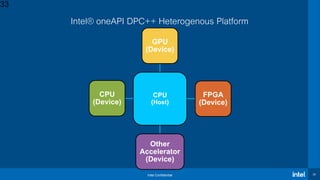
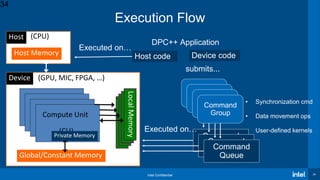
Download to read offline








{
return (std::abs(a) < std::abs(b));
}
);
}
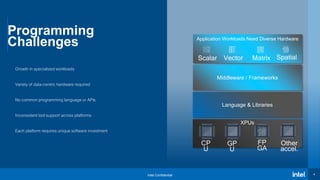
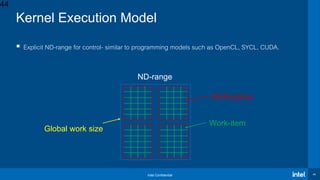
• A convenient way of defining an
anonymous function object right at
the location where it is invoked or
passed as an argument to a function
• Lambda functions can be used to
define kernels in SYCL
• The kernel lambda MUST use copy
for all its captures (i.e., [=])
Capture clause
Parameter list
Lambda body
10](https://image.slidesharecdn.com/oneapidpcvirtualworkshop-9thdec20-201210090944/85/OneAPI-dpc-Virtual-Workshop-9th-Dec-20-10-320.jpg)

 {
16](https://image.slidesharecdn.com/oneapidpcvirtualworkshop-9thdec20-201210090944/85/OneAPI-dpc-Virtual-Workshop-9th-Dec-20-16-320.jpg)

 {
C[i] = A[i] + B[i];});
18
Each iteration (work-
item) will have a
separate index id (i)](https://image.slidesharecdn.com/oneapidpcvirtualworkshop-9thdec20-201210090944/85/OneAPI-dpc-Virtual-Workshop-9th-Dec-20-18-320.jpg)
![Intel Confidential 19
int main() {
float A[N], B[N], C[N];
{ buffer bufA (A, range(N));
buffer bufB (B, range(N));
buffer bufC (C, range(N));
queue myQueue;
myQueue.submit([&](handler& cgh) {
auto A = bufA.get_access(cgh, read_only);
auto B = bufB.get_access(cgh, read_only);
auto C = bufC.get_access(cgh);
cgh.parallel_for<class vector_add>(N, [=](auto i){
C[i] = A[i] + B[i];});
});
}
for (int i = 0; i < 5; i++){
cout << "C[" << i << "] = " << C[i] <<std::endl;
}
return 0;
}
DPC++ “Hello World”: Vector Addition Entire Code
19](https://image.slidesharecdn.com/oneapidpcvirtualworkshop-9thdec20-201210090944/85/OneAPI-dpc-Virtual-Workshop-9th-Dec-20-19-320.jpg)
![Intel Confidential 20
int main() {
float A[N], B[N], C[N];
{ buffer bufA (A, range(N));
buffer bufB (B, range(N));
buffer bufC (C, range(N));
queue myQueue;
myQueue.submit([&](handler& cgh) {
auto A = bufA.get_access(cgh, read_only);
auto B = bufB.get_access(cgh, read_only);
auto C = bufC.get_access(cgh);
cgh.parallel_for<class vector_add>(N, [=](auto i) {
C[i] = A[i] + B[i];});
});
}
for (int i = 0; i < 5; i++){
cout << "C[" << i << "] = " << C[i] <<std::endl;}
return 0;
}
Host code
Anatomy of a DPC++ Application
20
Host code](https://image.slidesharecdn.com/oneapidpcvirtualworkshop-9thdec20-201210090944/85/OneAPI-dpc-Virtual-Workshop-9th-Dec-20-20-320.jpg)
![Intel Confidential 21
int main() {
float A[N], B[N], C[N];
{ buffer bufA (A, range(N));
buffer bufB (B, range(N));
buffer bufC (C, range(N));
queue myQueue;
myQueue.submit([&](handler& cgh) {
auto A = bufA.get_access(cgh, read_only);
auto B = bufB.get_access(cgh, read_only);
auto C = bufC.get_access(cgh);
cgh.parallel_for<class vector_add>(N, [=](auto i) {
C[i] = A[i] + B[i];});
});
}
for (int i = 0; i < 5; i++){
cout << "C[" << i << "] = " << C[i] <<std::endl;
}
return 0;
}
Accelerator
device code
Anatomy of a DPC++ Application
21
Host code
Host code](https://image.slidesharecdn.com/oneapidpcvirtualworkshop-9thdec20-201210090944/85/OneAPI-dpc-Virtual-Workshop-9th-Dec-20-21-320.jpg)
![Intel Confidential 22
int main() {
float A[N], B[N], C[N];
{ buffer bufA (A, range(N));
buffer bufB (B, range(N));
buffer bufC (C, range(N));
queue myQueue;
myQueue.submit([&](handler& cgh) {
auto A = bufA.get_access(cgh, read_only);
auto B = bufB.get_access(cgh, read_only);
auto C = bufC.get_access(cgh);
cgh.parallel_for<class vector_add>(N, [=](auto i) {
C[i] = A[i] + B[i];});
});
}
for (int i = 0; i < 5; i++){
cout << "C[" << i << "] = " << C[i] <<std::endl;
}
return 0;
}
22
DPC++ basics
Write-buffer is now out-of-scope, so
kernel completes, and host pointer
has consistent view of output.](https://image.slidesharecdn.com/oneapidpcvirtualworkshop-9thdec20-201210090944/85/OneAPI-dpc-Virtual-Workshop-9th-Dec-20-22-320.jpg)
![Intel Confidential 23
int main() {
float A[N], B[N], C[N];
{ buffer bufA (A, range(N));
buffer bufB (B, range(N));
buffer bufC (C, range(N));
queue myQueue;
myQueue.submit([&](handler& cgh) {
auto A = bufA.get_access(cgh, read_only);
auto B = bufB.get_access(cgh, read_only);
auto C = bufC.get_access(cgh);
cgh.parallel_for<class vector_add>(N, [=](auto i) {
C[i] = A[i] + B[i];});
});
}
for (int i = 0; i < 5; i++){
cout << "C[" << i << "] = " << C[i] <<std::endl;
}
return 0;
}
23
DPC++ basics](https://image.slidesharecdn.com/oneapidpcvirtualworkshop-9thdec20-201210090944/85/OneAPI-dpc-Virtual-Workshop-9th-Dec-20-23-320.jpg)







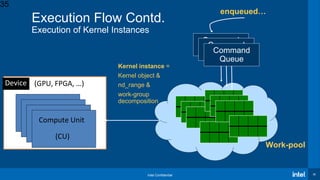




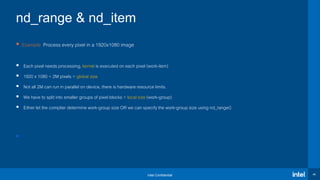
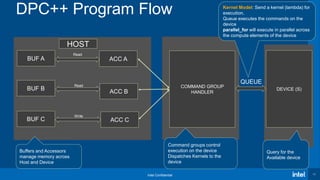
{
// CODE THAT RUNS ON DEVICE
})
h.parallel_for(range<2>(1920,1080), [=](id<2>
item){
// CODE THAT RUNS ON DEVICE
});
nd_range & nd_item
global
size
local size
(work-group
size)](https://image.slidesharecdn.com/oneapidpcvirtualworkshop-9thdec20-201210090944/85/OneAPI-dpc-Virtual-Workshop-9th-Dec-20-46-320.jpg)



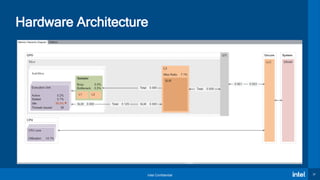
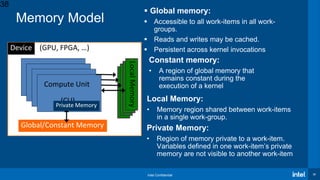
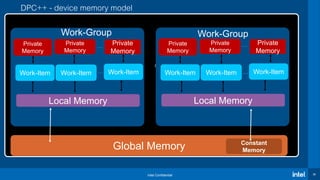
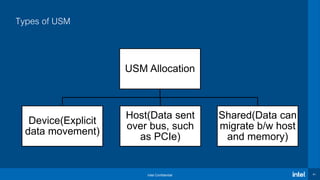
The document presents an overview of the Intel® oneAPI and DPC++ programming model aimed at simplifying development for heterogeneous architectures while enhancing performance through data parallelism. It includes a 'Hello World' example, highlights the DPC++ compatibility tool for migrating CUDA code, and explains kernel execution models alongside device memory management. Additionally, it emphasizes the open-source nature of DPC++ and encourages community participation in its development.

































![[Harvard CS264] 07 - GPU Cluster Programming (MPI & ZeroMQ)](https://cdn.slidesharecdn.com/ss_thumbnails/cs264201107-mpi0mq-110308182928-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)





















































