Downloaded 57 times

















![K-means
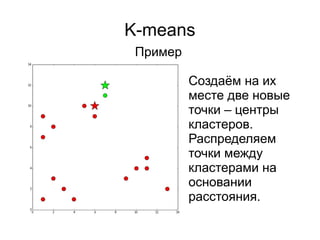
● Случайные точки в границах [min; max]
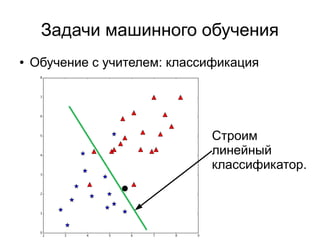
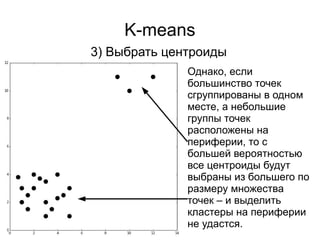
3) Выбрать центроиды
При данном подходе могут
быть выбраны центроиды в
“пустынных” областях
пространства и им
придётся проделать
лишний путь в процессе
минимизации значения
функции стоимости.](https://image.slidesharecdn.com/zhdanovk-means-150929054815-lva1-app6892/85/Bitworks-Software-41-320.jpg)
![K-means
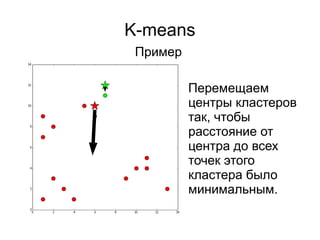
● Случайные точки в границах [min; max]
● Случайные точки из множества точек
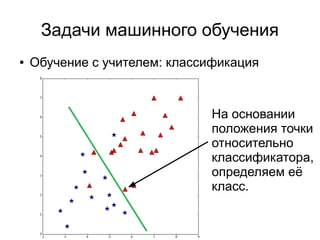
3) Выбрать центроиды
Подход, который был использован нами при
рассмотрении первого примера. Выбираем с равной
вероятностью несколько точек из набора исходных,
дублируем их и используем дубликаты в качестве
центроидов.](https://image.slidesharecdn.com/zhdanovk-means-150929054815-lva1-app6892/85/Bitworks-Software-42-320.jpg)
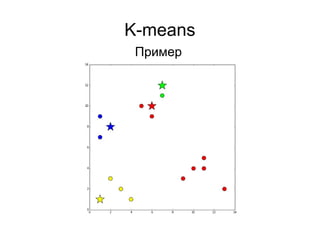
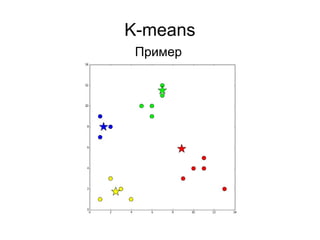
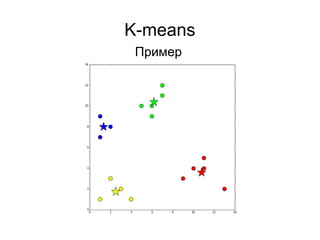
![K-means
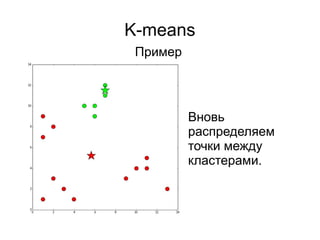
● Случайные точки в границах [min; max]
● Случайные точки из множества точек
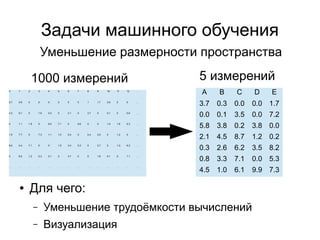
● Взвешенный случаный выбор точек из
множества (k-means++):
– Выбрать одну случайно
– Вычислить вероятности для всех остальных
точек на основании расстояния до выбранных
– Выбрать следующую, учитывая вероятности
– Пересчитать вероятности
3) Выбрать центроиды](https://image.slidesharecdn.com/zhdanovk-means-150929054815-lva1-app6892/85/Bitworks-Software-44-320.jpg)








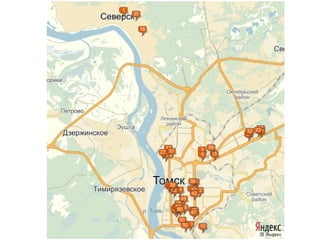

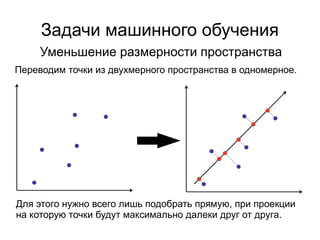
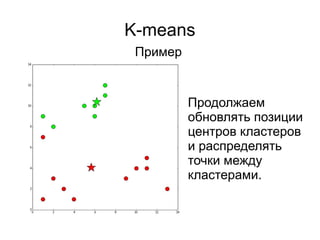
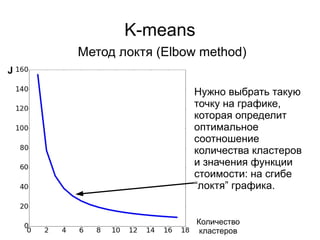
![Метод локтя
Количество кластеров – степени двойки
Рассмотрим подробнее
отрезок [6, 16], так как
именно в этих границах
наблюдается резкое
уменьшение скорости
изменения значения
функции стоимости.](https://image.slidesharecdn.com/zhdanovk-means-150929054815-lva1-app6892/85/Bitworks-Software-62-320.jpg)
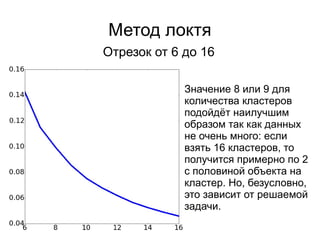
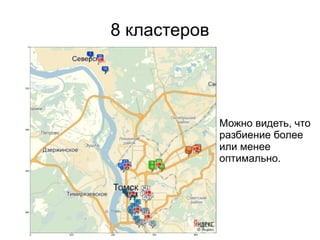
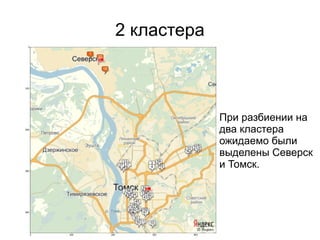





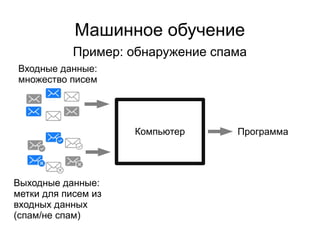
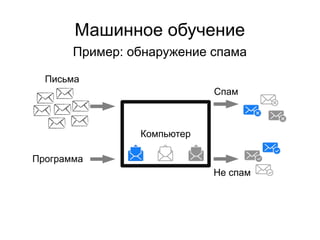
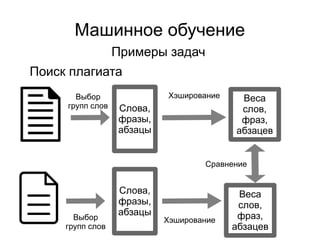
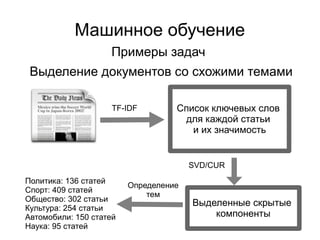
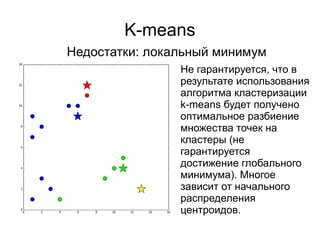
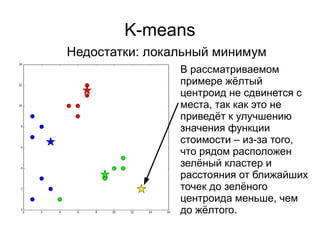
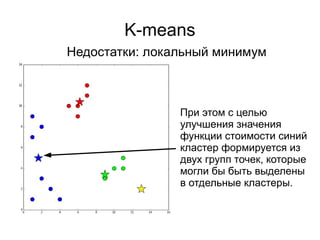
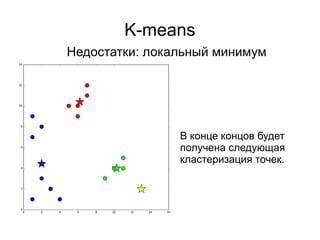
Документ представляет введение в машинное обучение с акцентом на кластеризацию, в частности, метод k-means. Обсуждаются примеры применения машинного обучения, включая обнаружение спама, рекомендательные системы и задачи регрессии и классификации. Также рассматриваются недостатки метода k-means и предлагаются советы по его использованию, такие как выбор количества кластеров и нормализация данных.











































![Machine learning with Python / Олег Шидловский / Doist [Python Meetup 27.03.15]](https://cdn.slidesharecdn.com/ss_thumbnails/1pythonmeetupmachinelearning-150423015403-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)































