Download as PDF, PPTX




![НОРМАЛИЗАЦИЯ ДАННЫХ
• Единица измерения может влиять на результат. Описание
атрибута в меньших единицах измерения (например, в см
вместо метров) приводит к большему диапазону
значений и, следовательно, придает данному атрибуту
больший “вес”
• Нормализация (стандартизация) данных предназначена
для устранения зависимости от выбора единицы
измерения и заключается в преобразовании диапазонов
значений всех атрибутов к стандартным интервалам
[-1, 1] или [0, 1]
• Нормализация данных направлена на придание всем
атрибутам одинакового “веса”.](https://image.slidesharecdn.com/7-141108112721-conversion-gate02/85/Data-Mining-lecture-7-2014-4-320.jpg)

![НОРМАЛИЗАЦИЯ ДАННЫХ
MIN-MAX НОРМАЛИЗАЦИЯ
min-max нормализация заключается в применении к
диапазону значений атрибута x линейного преобразования,
которое отображает [min(x), max(x)] в [A, B]
x′i =τ xi ( ) = xi −min(x)
max(x)−min(x)
⋅(B − A)+ A
x ∈[min(x), max(x)]⇒τ (x)∈[A, B]
• min-max нормализация сохраняет все зависимости и порядок
оригинальных значений атрибута
• Если данные содержат доминирующие аномалии (аутлаеры),
тогда такое преобразование сильно “сожмет” основную массу
значений к очень маленькому интервалу!](https://image.slidesharecdn.com/7-141108112721-conversion-gate02/85/Data-Mining-lecture-7-2014-6-320.jpg)
![НОРМАЛИЗАЦИЯ ДАННЫХ
ПРИМЕР: MIN-MAX НОРМАЛИЗАЦИЯ
Пусть атрибут зарплата принимает следующие
значения (грн): 3000, 3600, 4700, 5000, 5200, 5200,
5600, 6000, 6300, 7000, 7000, 11000
Преобразуем диапазон значений данного атрибута x
к интервалу [0, 1] при помощи min-max нормализации
min(x) = 3000, max(x) = 11000⇒ x ∈[3000,11000]
A = 0, B = 1⇒ x′ =τ (x)∈[0,1]
x′i =τ xi ( ) = xi − 3000
8000
x′3 =τ x3 ( ) =τ (4700) = (4700 − 3000)
8000
= 0.2125](https://image.slidesharecdn.com/7-141108112721-conversion-gate02/85/Data-Mining-lecture-7-2014-7-320.jpg)
![НОРМАЛИЗАЦИЯ ДАННЫХ
Z-НОРМАЛИЗАЦИЯ
z-нормализация (zero-mean normalization) основывается
на приведении распределения исходного атрибута x к
центрированному распределению со стандартным
отклонением, равным 1
x′i =τ xi ( ) = xi − x
σ x
M[x′] = x′ = 1
N
xi − x
σ i=1 x
NΣ
= 1
σ x
1
N
xi
NΣ
i=1
− x
⎛
⎝ ⎜
⎞
⎠ ⎟
= 0
D[x′] = M (x′)2 ⎡⎣⎤⎦
− (M[x′])2 == M (x′)2 ⎡⎣
⎤⎦
= M
⎡ 2
x − x
σ x
⎛
⎝ ⎜
⎞
⎠ ⎟
⎣ ⎢⎢
⎤
⎦ ⎥⎥
= 1
σ x
2 M (x − x )2 ⎡⎣
⎤⎦
= D[x]
σ x
2 = 1
• Метод полезен когда максимум (минимум) неизвестны или
когда данные содержат доминирующие аномалии (аутлаеры)](https://image.slidesharecdn.com/7-141108112721-conversion-gate02/85/Data-Mining-lecture-7-2014-8-320.jpg)


![НОРМАЛИЗАЦИЯ ДАННЫХ
МАСШТАБИРОВАНИЕ
Масштабирование заключается в изменении
длины вектора значений атрибута путем
умножения на константу
x′i =τ xi ( ) = λ ⋅ xi λ ≠ 0,λ = const
Длина вектора x уменьшается при λ <1
и увеличивается,
если
λ >1
• Популярные константы на практике
λ = 1
x
⇒ x′ =τ (x) = x
x
⇒ x′ = 1
λ = 10− p , p = min
k
xi
:max
10k i=1..N
xi
10k
⎛
⎝ ⎜
⎞
⎠ ⎟
≤1
⎧⎨⎩
⎫⎬⎭
⇒ x′ =τ (x) = x
10p ⇒ x′ ∈[−1,1]
•
•](https://image.slidesharecdn.com/7-141108112721-conversion-gate02/85/Data-Mining-lecture-7-2014-11-320.jpg)
![НОРМАЛИЗАЦИЯ ДАННЫХ
ПРИМЕР: МАСШТАБИРОВАНИЕ
Пусть атрибут зарплата принимает следующие
значения (грн): 3000, 3600, 4700, 5000, 5200, 5200,
5600, 6000, 6300, 7000, 7000, 11000
Необходимо провести масштабирование
атрибута, чтобы значения были в [-1, 1]
τ xi ( ) = xi
105
xi ( )
105 = 0.11 <1⇒ p = 5
x′3 =τ x3 ( ) =τ (4700) = 4700
105 = 0.047
λ = 10− p , max
i=1..N
xi ( ) = 11000⇒
max
i=1..N](https://image.slidesharecdn.com/7-141108112721-conversion-gate02/85/Data-Mining-lecture-7-2014-12-320.jpg)

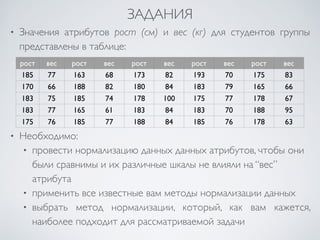

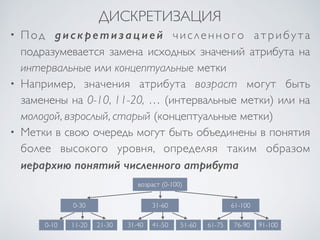











Документ посвящен подготовке данных для интеллектуального анализа данных, включая методы нормализации и дискретизации. Рассматриваются различные подходы, такие как min-max и z-нормализация, а также методы построения иерархий понятий. Включены примеры и задания на применение изученных методов в практике.























































































