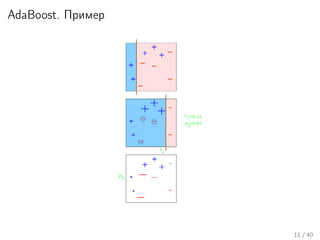
Документ представляет лекцию о алгоритмических композициях, в частности методах бустинга и градиентного бустинга, объясняя их принципы и применение. Лекция охватывает задачи обучения на основе данных, различные методы, включая adaboost и их возможность предотвращения переобучения, а также эффекты дисциплинарных подходов к обработке данных. Кроме того, документ содержит практические задания и варианты реализации алгоритмов машинного обучения.









![AdaBoost(Freund & Shapire 1995)
1. Инициализировать веса объектов wj = 1/N, j = 1, 2, . . . , N.
2. Для всех i от 1 до T:
(a) Построить классификатор ai (x), используя веса wj
(b) Вычислить
erri =
N
j=1 wj I(yj = ai (xj ))
N
j=1 wj
(c) Вычислить
bi = log
1 − erri
erri
(d) Присвоить wj → wj · exp[bi · I(yj = ai (xj ))], j = 1, . . . , N.
3. h(x) = sign
T
i=1 bi ai (x)
9 / 40](https://image.slidesharecdn.com/lecture10-150417074717-conversion-gate02/85/10-10-320.jpg)