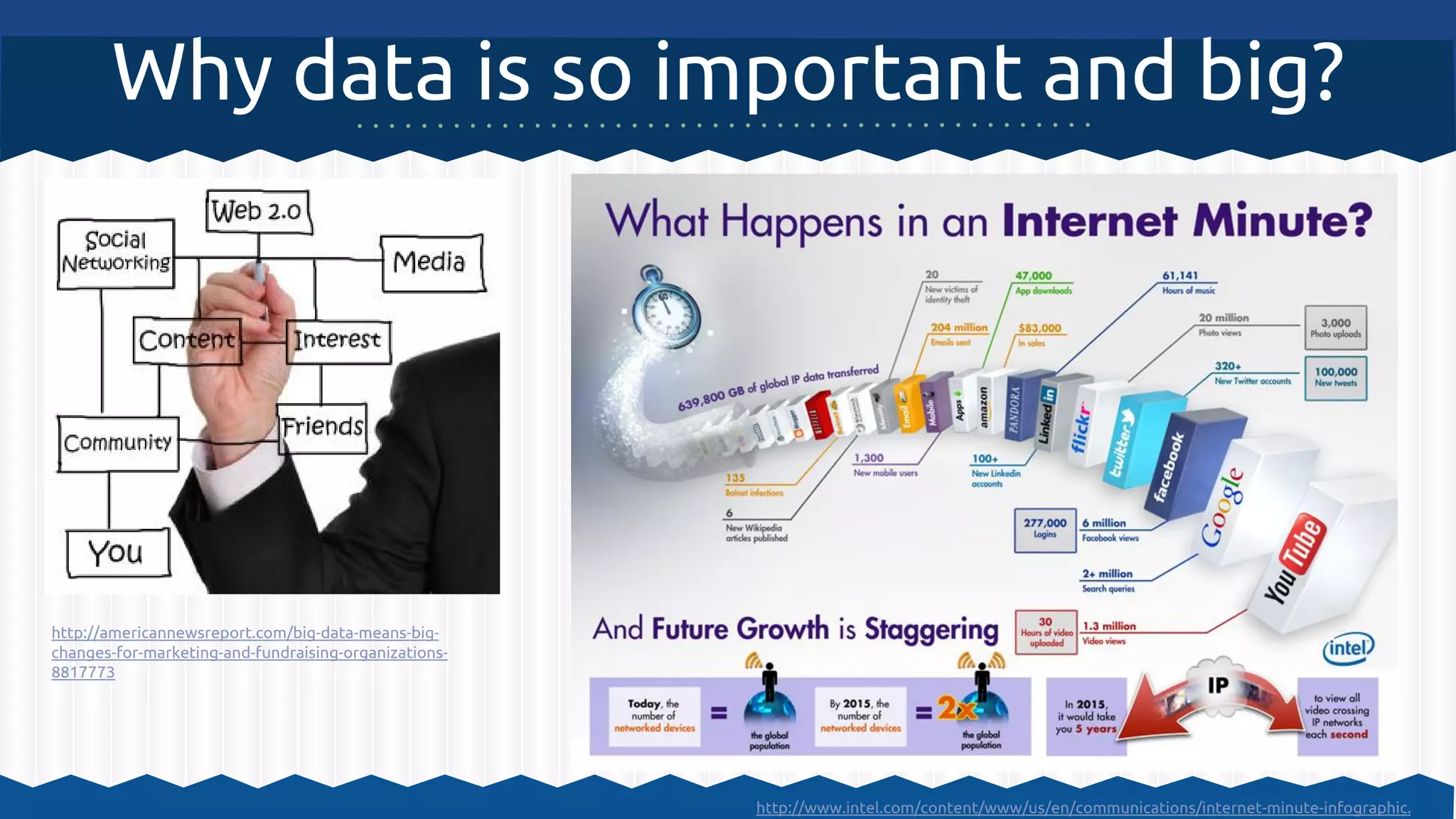
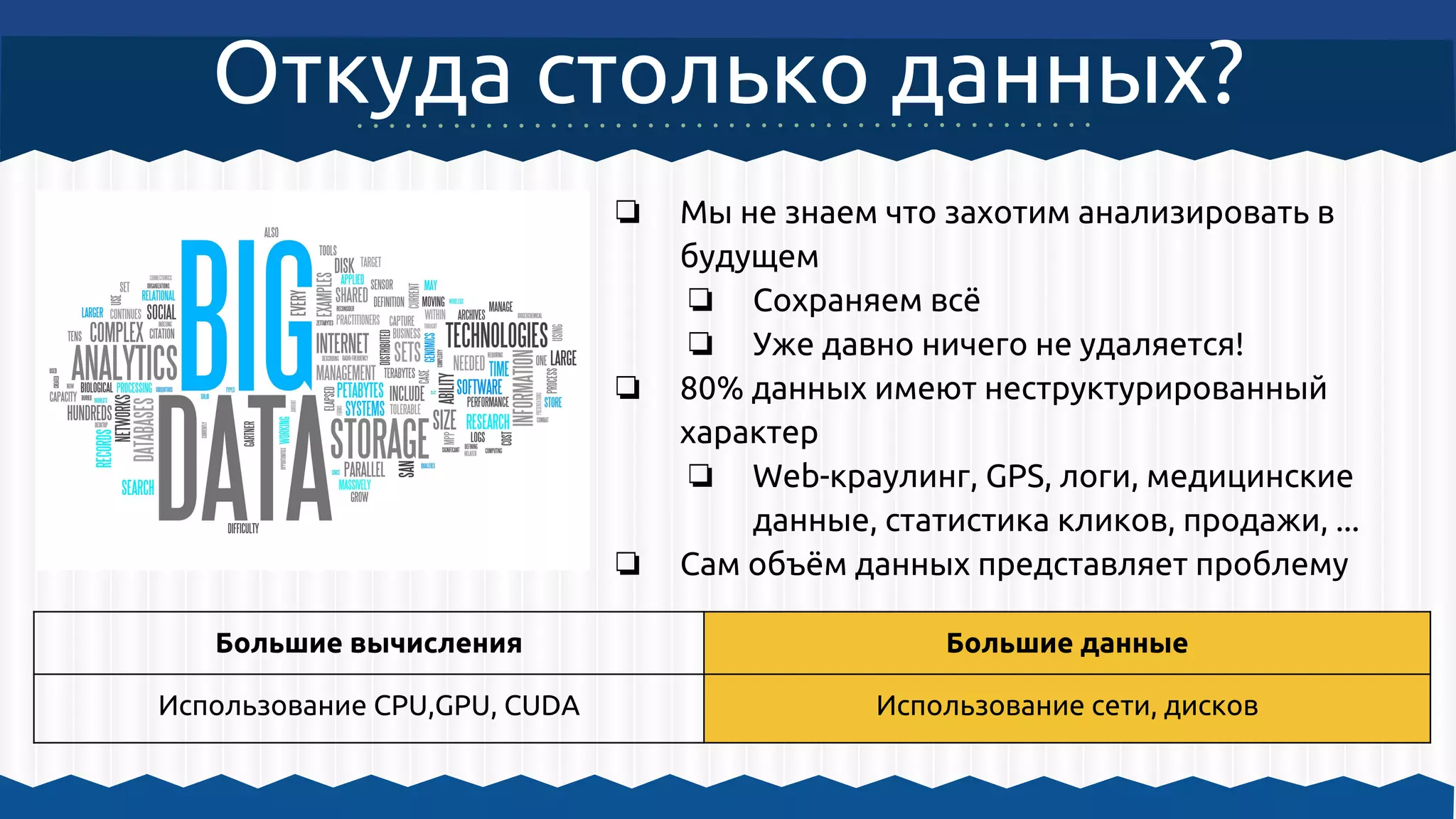
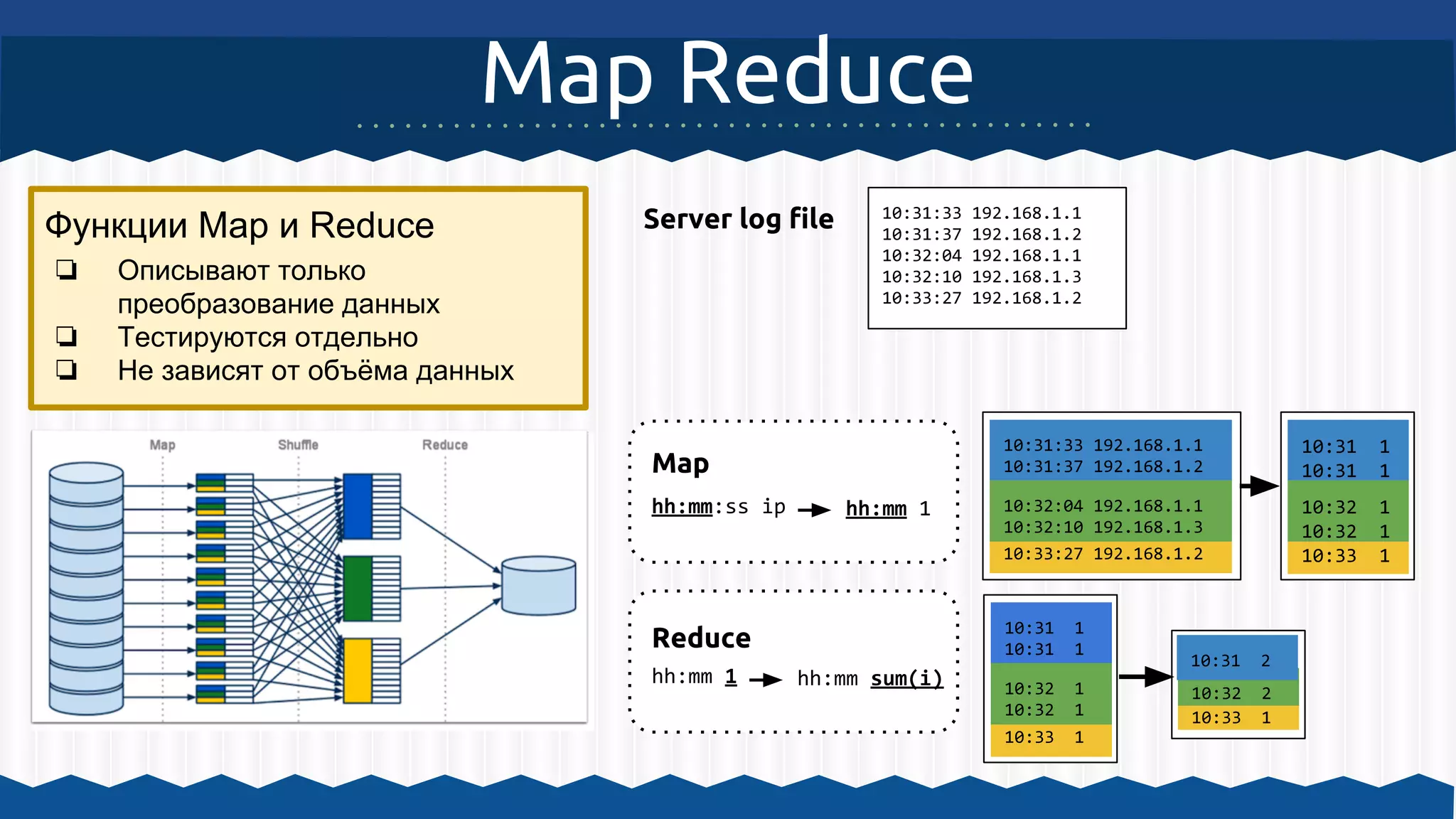
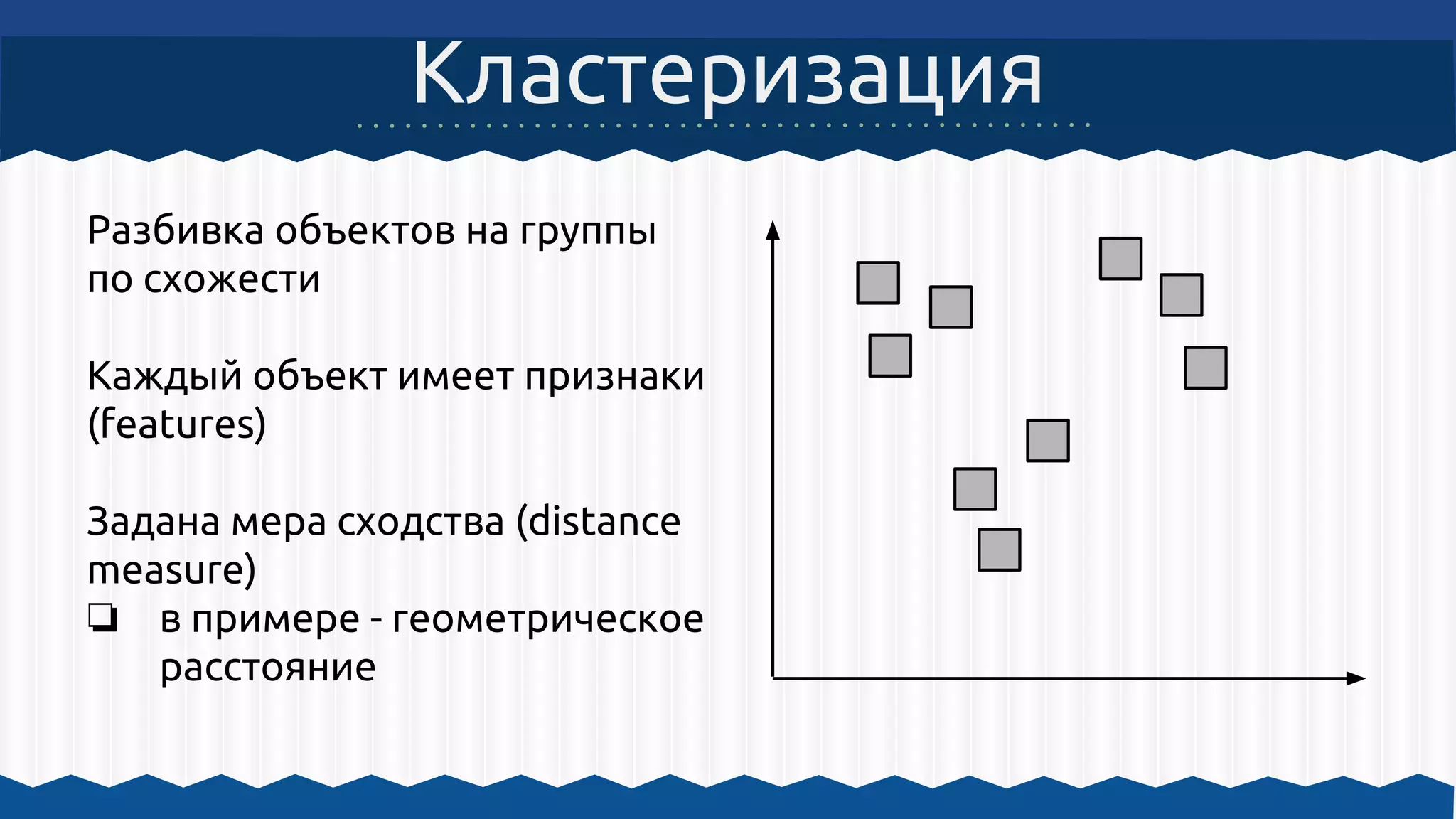
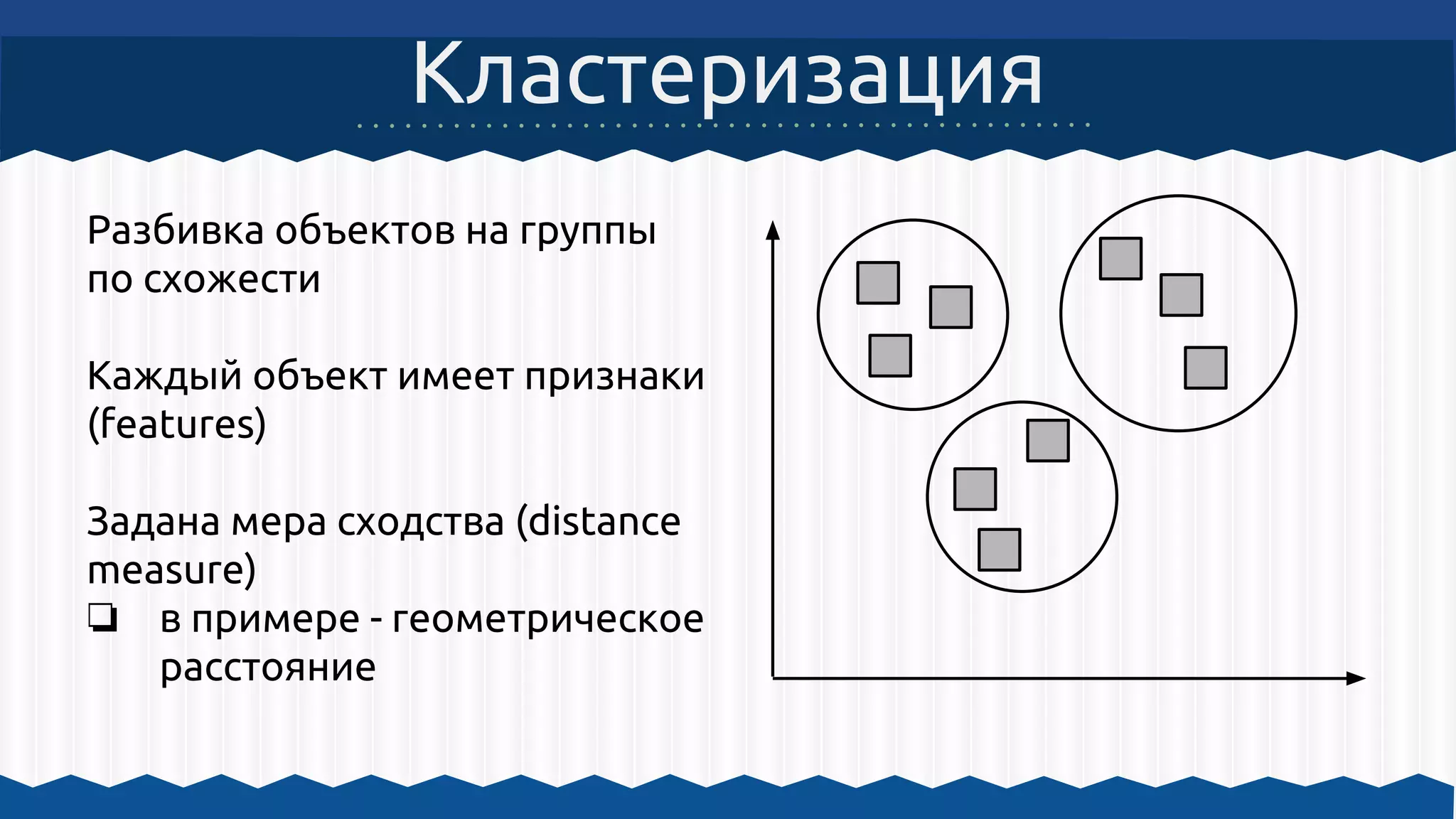
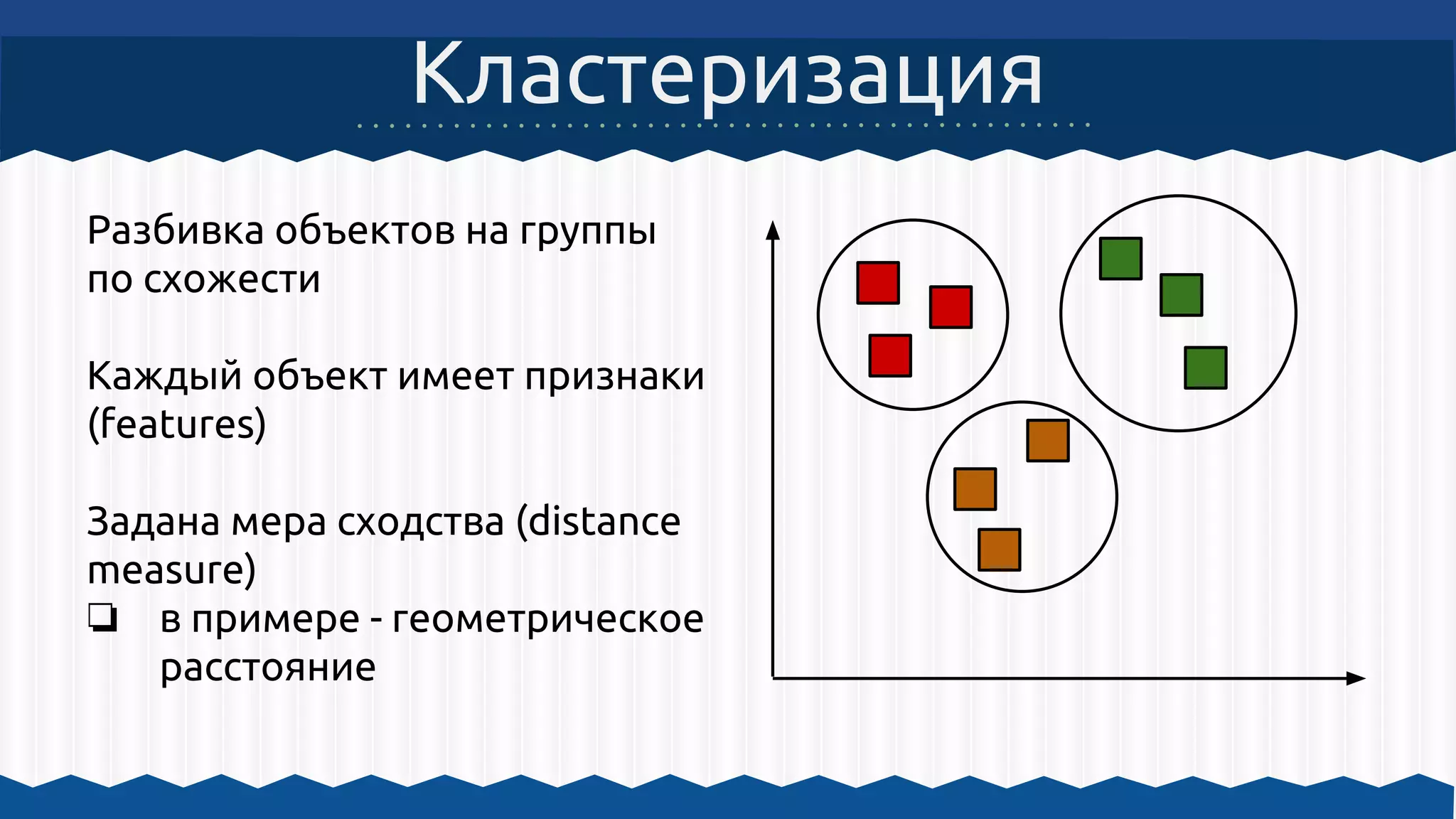
Документ описывает использование Apache Hadoop и Apache Mahout для обработки больших данных и машинного обучения, включая примеры кластеризации и архитектурные решения. Он охватывает инструкции по настройке среды для работы с Hadoop, а также принципы функционирования MapReduce и алгоритмы машинного обучения, встроенные в Mahout. Основное внимание уделяется важности масштабируемости, отказоустойчивости и гибкости инфраструктуры для обработки неструктурированных данных.











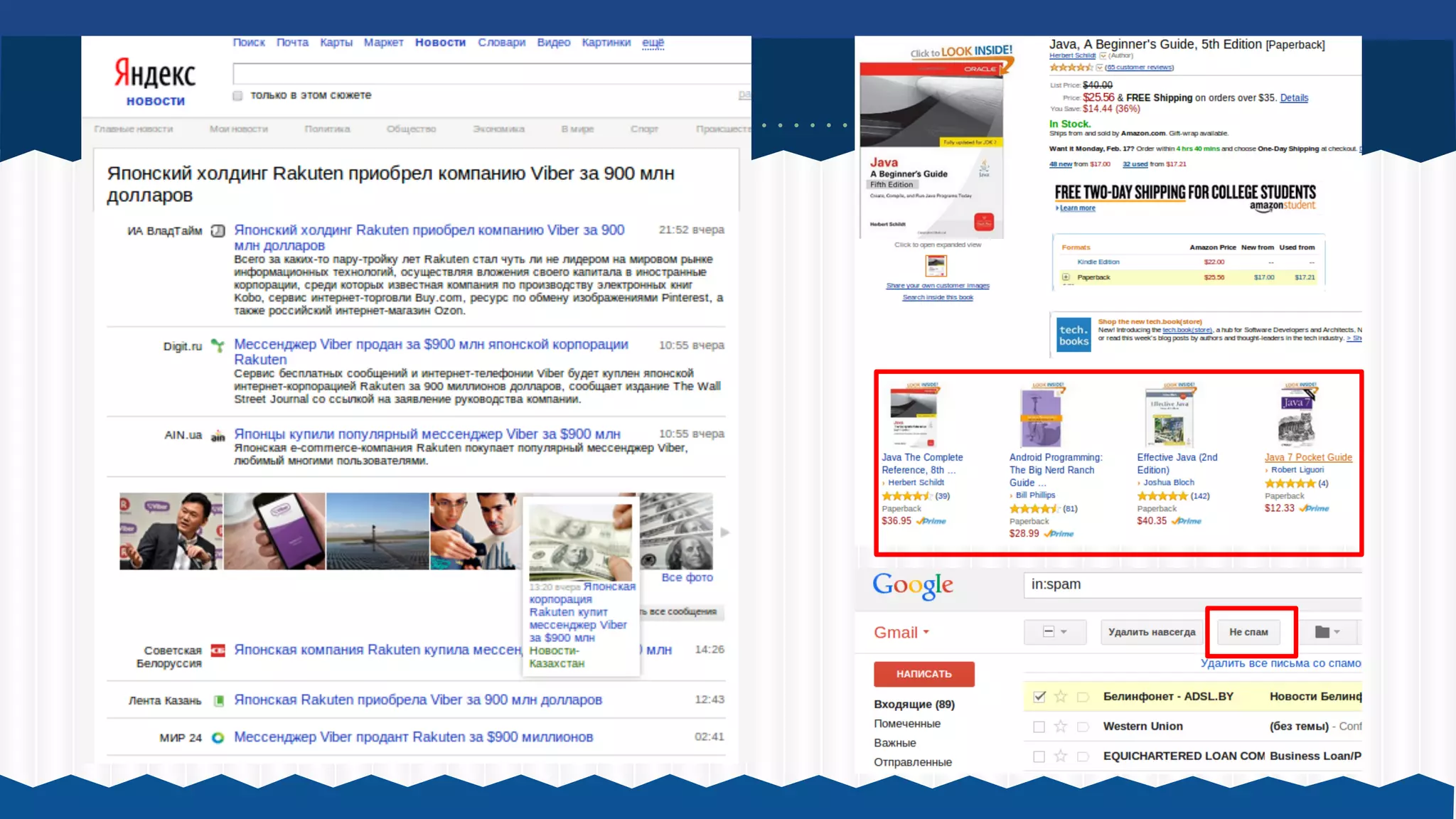
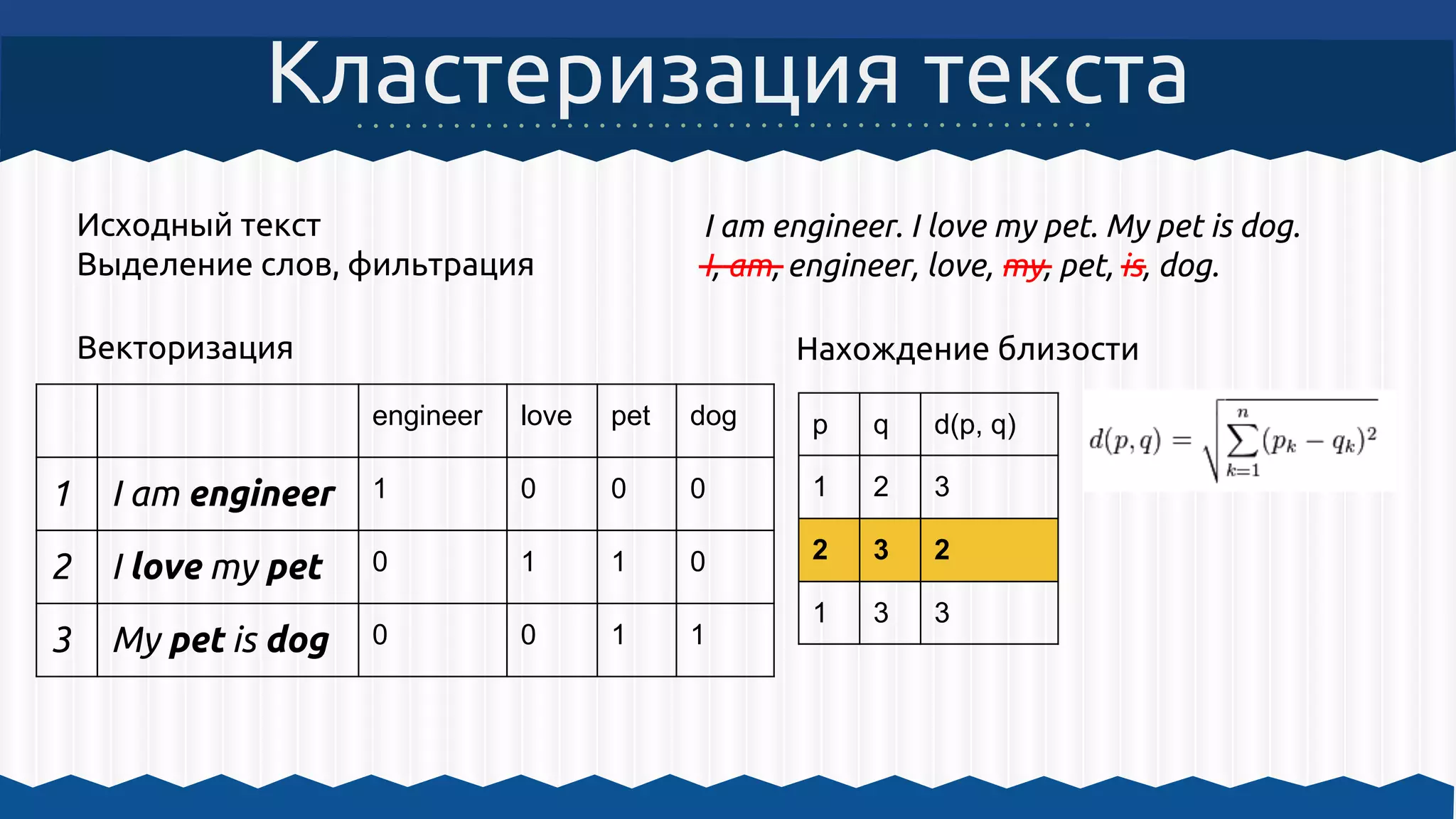




![Кластеризация stackoverflow
XML Text
[0, 1, 0, 1, 1, 0]
[1, 0, 0, 1, 1, 1]
1. Выделение
текста из XML
2. Обработка текста
3. Векторизация
4. Кластеризация 5. Отображение
результатов
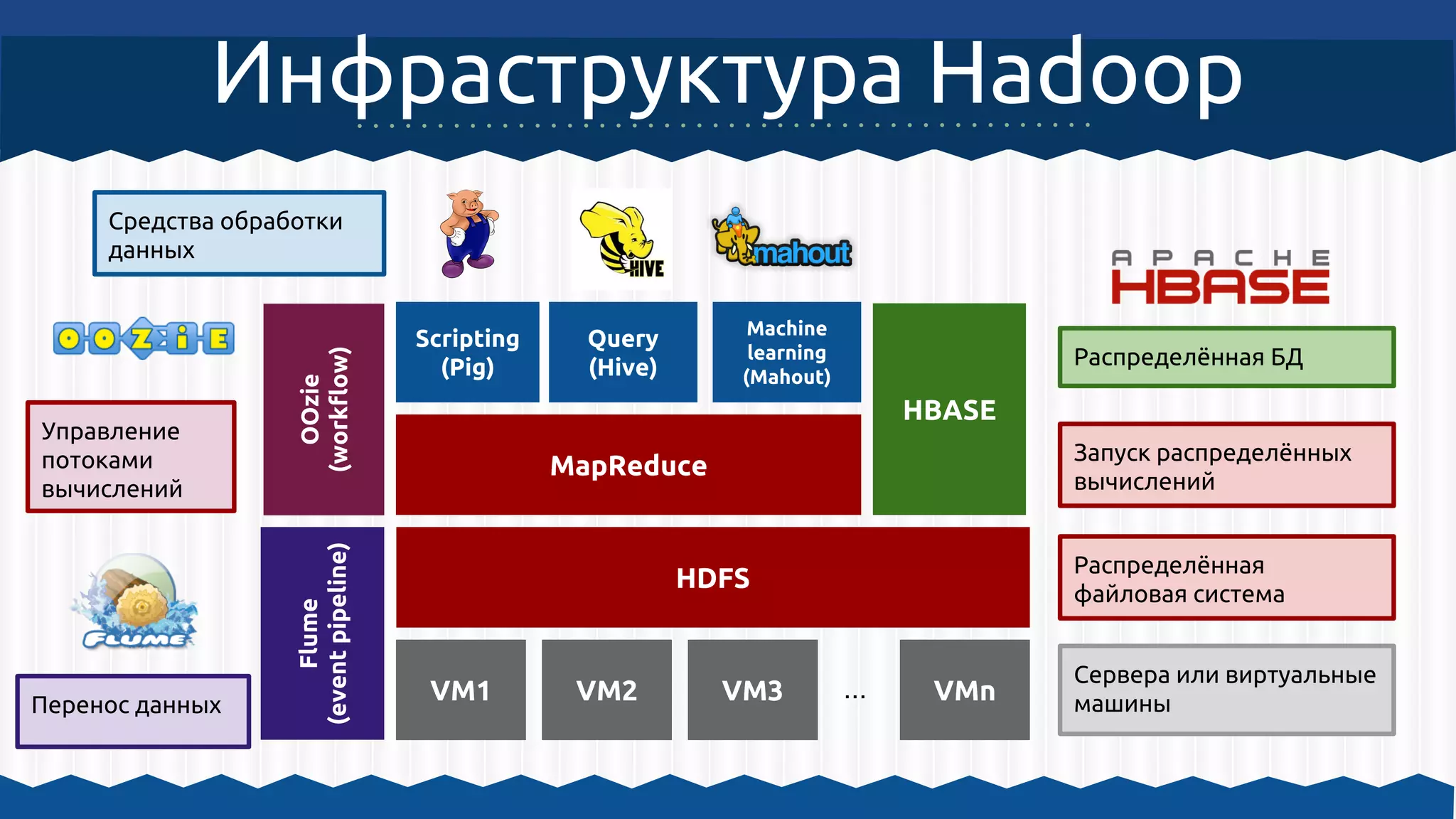
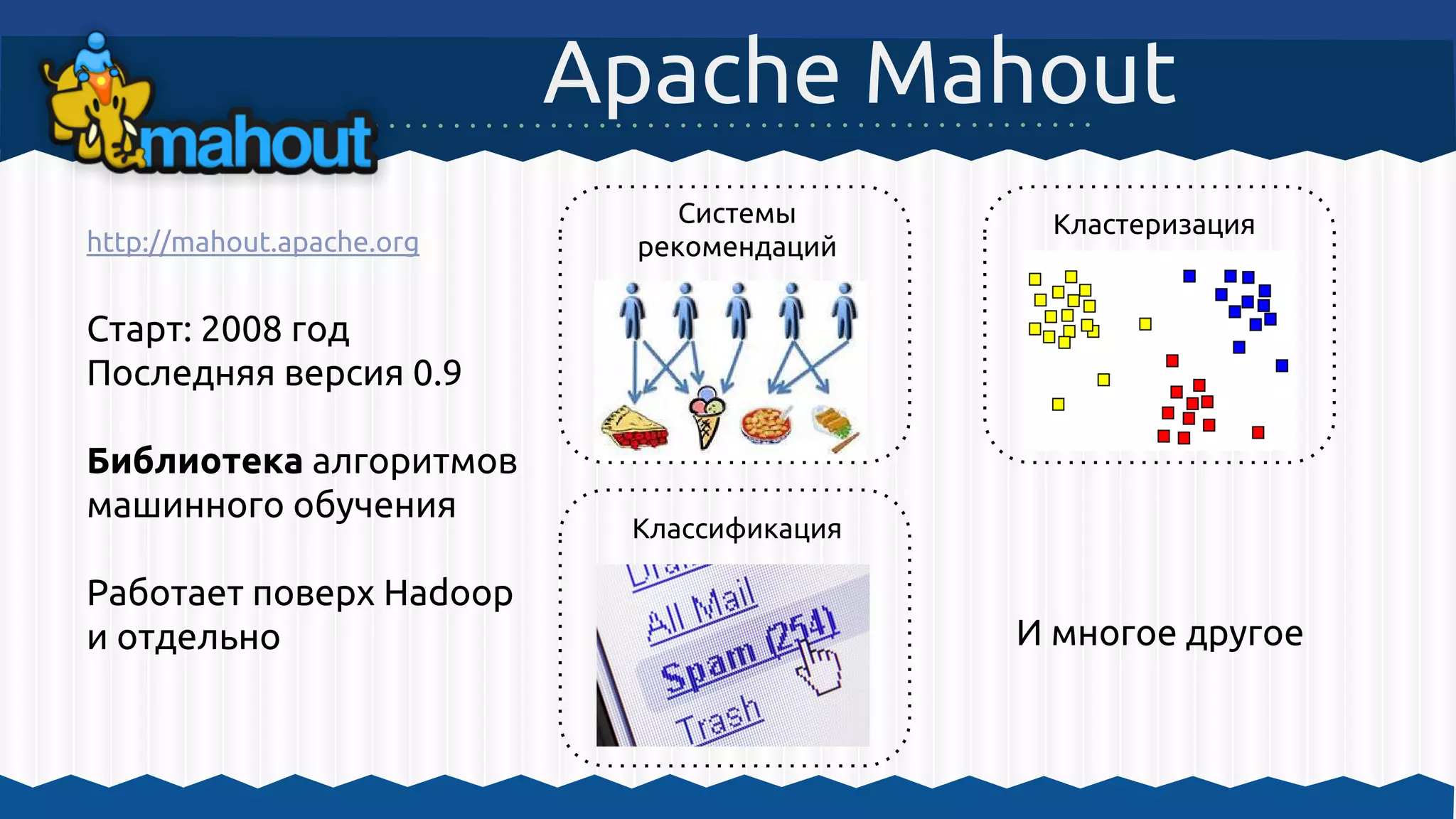
1. Hadoop MapReduce
2. Mahout + Lucene (фильтр слов, начальная форма, ...)
3. Mahout, алгоритм TF-IDF
4. Mahout, алгоритм К-средних
5. Hadoop MapReduce, HTML, JavaScript, Database](https://image.slidesharecdn.com/mapreducehadoopmahout-140516092115-phpapp02/75/Solit-2014-MapReduce-hadoop-mahout-31-2048.jpg)
































![Machine learning with Python / Олег Шидловский / Doist [Python Meetup 27.03.15]](https://cdn.slidesharecdn.com/ss_thumbnails/1pythonmeetupmachinelearning-150423015403-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)
























































