Лекция охватывает задачи кластеризации, включая смесь нормальных распределений и методы EM и k-means. Обсуждаются принципы и этапы кластеризации, такие как определение похожести объектов, оценка качества моделей и необходимость разметки данных. Также рассматриваются различные алгоритмы и модификации кластера, критерии качества и проблемы, возникающие из-за высокой размерности данных.







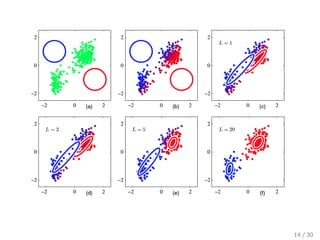
![Многомерное нормальное распределение
N(x|µ, Σ) =
1
(2π)D/2
1
|Σ|1/2
exp −
1
2
(x − µ)T
Σ−1
(x − µ)
Параметры
D-мерный вектор средних D × D-мерная матрица ковариации
µ = xp(x)dx Σ = E[(x − µ)(x − µ)T
]
(a) D = 2 (b) (c) Σ = diag(σi ) (d) Σ = σI
7 / 30](https://image.slidesharecdn.com/lecture2-150417051104-conversion-gate02/85/2-8-320.jpg)






![EM-алгоритм
Дано. Известно распределение P(X, Z|θ), где x – наблюдаемые
переменные, а z – скрытые.
Найти. θ, максимизирующее P(X|θ).
E вычислить P(Z|X, θold
) при фиксированном θold
M вычислить θnew
= arg maxθ Q(θ, θold
), где
Q(θ, θold
) = EZ[ln p(X, Z|θ)] =
Z
p(Z|X, θold
) ln p(X, Z|θ))
Улучшение: ввести априорное распределение p(θ)
15 / 30](https://image.slidesharecdn.com/lecture2-150417051104-conversion-gate02/85/2-16-320.jpg)
![K-means
Пусть Σk = I, тогда
p(x|µk , Σk ) =
1
√
2π
exp(−
1
2
x − µk
2
)
Рассмотрим стремление → 0
γ(znk ) =
πk exp(− 1
2 xn − µk
2
)
j πj exp(− 1
2 xn − µj
2)
→ rnk =
1, для k = arg minj xn − µj
2
0, иначе
Функция правдоподобия
EZ[ln p(X, Z|µ, Σ, π)] → −
N
n=1
K
k=1
rnk xn − µk
2
+ const
Вектор средних
µk = n rnk xn
n rnk
16 / 30](https://image.slidesharecdn.com/lecture2-150417051104-conversion-gate02/85/2-17-320.jpg)







































































