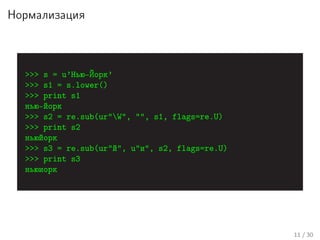
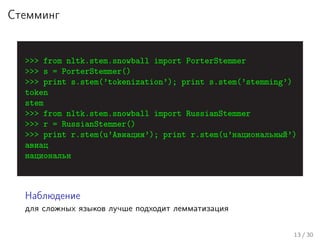
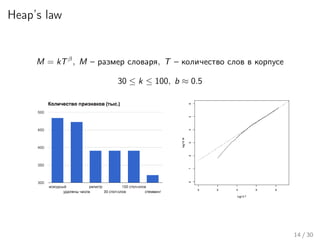
Лекция Николая Анохина посвящена классификации текстов с использованием алгоритма наивного байеса и обработке текстовых данных. Рассматриваются ключевые этапы обработки, такие как токенизация, нормализация, стемминг и лемматизация, а также обсуждаются модели представления документов и принципы работы наивного байеса. В конце лекции подводятся итоги и обсуждаются всевозможные применения алгоритма в задачах определения языка текста.








![Разбиение на токены
>>> from nltk.tokenize import RegexpTokenizer
>>> tokenizer = RegexpTokenizer(’w+|[^ws]+’)
>>> s = u’Трисия любила Нью-Йорк, поскольку любовь
... к Нью-Йорку могла положительно повлиять на ее карьеру.’
>>> for t in tokenizer.tokenize(s)[:7]: print t + " ::",
...
Трисия :: любила :: Нью :: - :: Йорк :: , :: поскольку ::
8 / 30](https://image.slidesharecdn.com/lecture5-150417051106-conversion-gate01/85/5-Naive-Bayes-9-320.jpg)
![Стоп-слова
Def.
Наиболее частые слова в языке, не содержащие никакой
информации о содержании текста
>>> from nltk.corpus import stopwords
>>> for sw in stopwords.words(’russian’)[1:20]: print sw,
...
в во не что он на я с со как а то все она так его но да ты
Проблема: “To be or not to be"
9 / 30](https://image.slidesharecdn.com/lecture5-150417051106-conversion-gate01/85/5-Naive-Bayes-10-320.jpg)