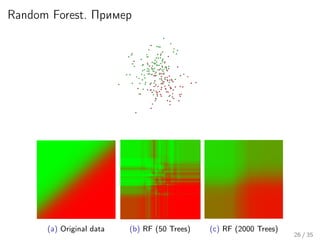
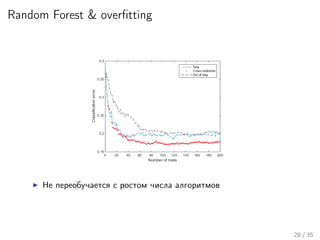
Лекция охватывает алгоритмические композиции и оценку различных методов, таких как случайные леса, нейронные сети и ансамбли деревьев решений. Обсуждаются стратегии, такие как бустинг и мета-алгоритмы, с применением к задачам, включая Netflix challenge. Также рассматриваются проблемы недообучения и переобучения, а также важные аспекты, такие как смещение и разброс в контексте работы алгоритмов.

















![The bias-variance Decomposition
Задача регресии
y = f (x) +
∼ N(0, σ )
Ищем h(x) аппроксимирующую f (x) Таким образом, мы можем
оценить ожидание среднеквадратичной ошибки для некоторой
точки x0
Err(x0) = E[(y − h(x0))2
]
Это можно переписать в виде
Err(x0) = (E[h(x0)] − f (x0))2
+ E[h(x0) − E(h(x0))]2
+ σ2
Err(x0) = Bias2
+ Variance + Noise(Irreducible Error)
17 / 35](https://image.slidesharecdn.com/lecture9-150417051127-conversion-gate01/85/9-18-320.jpg)





![Bias-Variance for Bagging & RSM
Модель простого голосования
h(x) =
1
T
T
i=1
a(x)
Смещение и разброс
Bias2
= (E[h(x0)] − f (x0))2
= (E[a(x0)] − f (x0))2
Variance = E[h(x0) − E(h(x0))]2
=
=
1
T
T
i=1
E[ai (x0) − E[ai (x0)]]2
+
+
1
T
i=j
E[(ai (x0) − E[ai (x0)])(aj (x0) − E[aj (x0)])] =
=
1
T
T
i=1
E[ai (x0) − E[ai (x0)]]2
+
1
T
i=j
cov(ai (x0), aj (x0))
23 / 35](https://image.slidesharecdn.com/lecture9-150417051127-conversion-gate01/85/9-24-320.jpg)