





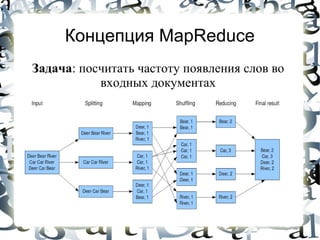
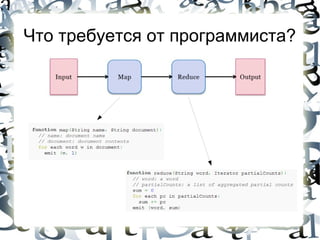
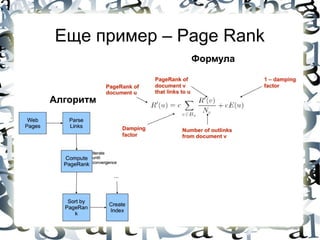




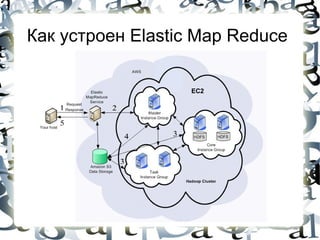

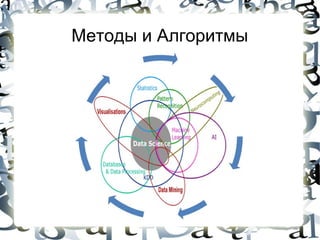
![Machine Learning
ДАННЫЕ ЗАДАЧА
Объект 1: [x11, x12, x13, x14, ..., x1n], y1 предпологая что yi = f(xij) необходимо
определить f
Объект 2: [x21, x22, x23, x24, ..., x2n], yn
............................................................. при этом предусматривается что f
пренадлежит определенному классу
Объект M: [xm1, xm2, xm3, xm4, ..., xmn], ym функций
xij – feature оптимальная функция подбирается
yi – class (или label)
путем минимизации определенной
Features и label могут быть разных типов ошибки
(бинарный, числовой, перечесляемый)
Пример:
- линейная функция yi = Ʃaj*xij +
b
- decision tree](https://image.slidesharecdn.com/stanfymapreduce-130109061511-phpapp01/85/BigData-Data-Science-16-320.jpg)

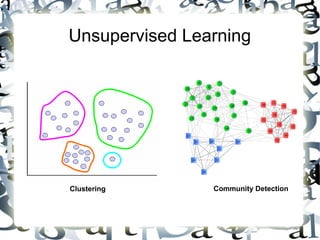





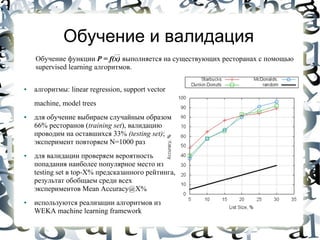



Документ обсуждает концепции больших данных и data science, определяя большие данные как информацию, которая превышает возможности традиционных систем обработки данных. В нем представлены методы и инструменты для анализа больших данных, включая алгоритмы машинного обучения и технологии, такие как MapReduce и Hadoop. Авторы подчеркивают важность правильного выбора методов и инструментов для достижения эффективности в работе с данными.







































