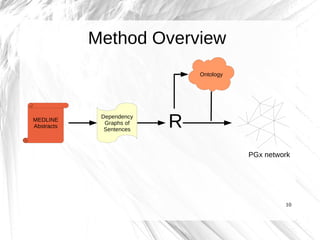
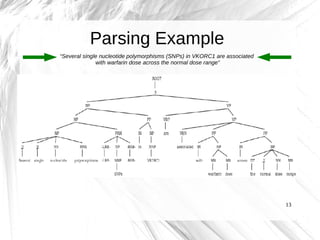
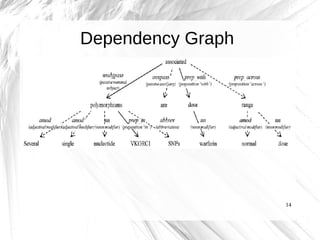
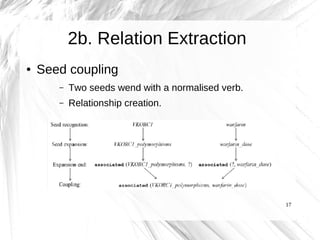
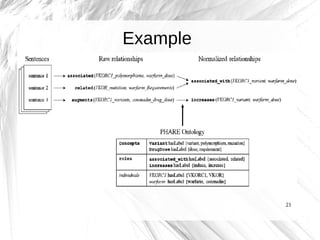
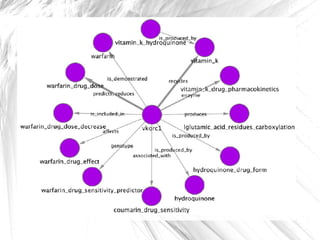
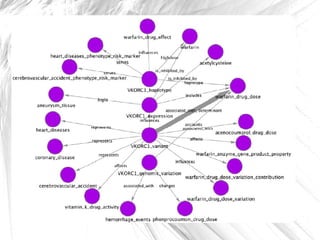
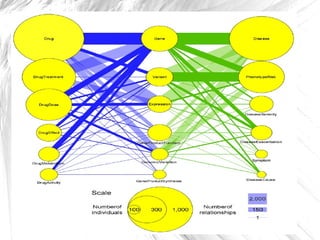
This document presents a method for automatically extracting relationships from biomedical literature and constructing a semantic network for pharmacogenomics knowledge. The method uses natural language processing techniques to parse sentences from abstracts, extract raw relationships between entities, and normalize relationships into an ontology. It was tested on over 17 million MEDLINE abstracts, extracting over 41,000 raw relationships. An ontology of 237 concepts and 76 roles was created to label the most frequent relationship types between genes, drugs and phenotypes. The results demonstrate an effective new approach for pharmacogenomics text mining and knowledge base construction.



























































![CTEV [ clubfoot] DR ARUN LAL ,DR MOHAMED ASHRAF travancore medical college k...](https://cdn.slidesharecdn.com/ss_thumbnails/ctevclubfootdrarunlaldrmohamedashraftravancoremedicalcollegekollamkeralaindia-260208063247-18fc466c-thumbnail.jpg?width=640&height=640&fit=bounds)





![PERI-PROSTHETIC FRACTURE NAIL-PLATE CONSTRUCT [NPC].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/drarunkumardrmohamedashrafperiprostheticfrasturenail-plateconstructnpc-260209164459-7e9d15a1-thumbnail.jpg?width=640&height=640&fit=bounds)







