Download as PDF, PPTX






![1. Clues for Instructional Compounds
Identification
Presence of instructions :
Morpho-lexical patterns
You should pre-heat the oven
shall Adv* base form verb
Have to Adv* base form verb
You have to pre-heat the oven
## Op? adv* base form verb
Do not pre-heat the oven
it be adv* (necessary|compulsory) that It is better that you pre-heat
the oven
Compound boudaries :
Morpho-lexical patterns
## to Adv* base form verb .* ,
(##|Conj) (if|then|after )
[To cook the cake, pre-heat the oven]
[and then start peeling …
[If you want to cook the cake, preHTML tags (typo-disposition) : heat the oven.] [If you don’t want to
cook …
<p> </p> <li> </li>
<li> [ Pre-heat the oven … ]</li>](https://image.slidesharecdn.com/instructionstitlesidentification-131201185341-phpapp01/85/Text-Processing-for-Procedural-Question-Answering-8-320.jpg)



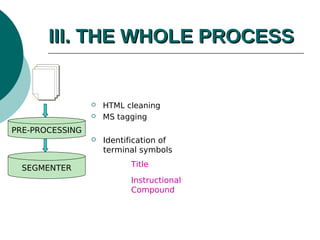


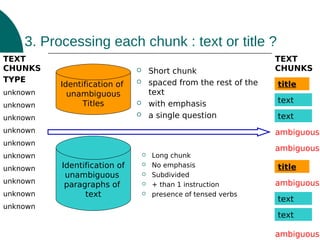

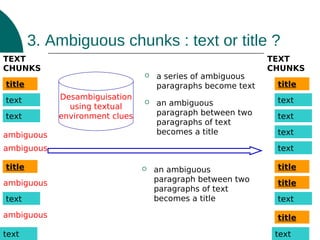





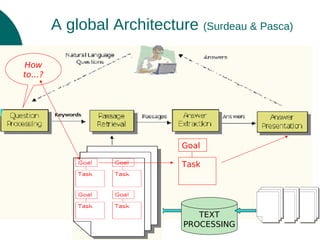
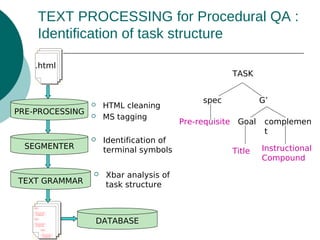
The document discusses a presentation on text processing for procedural question answering, highlighting the identification of instructional compounds and titles through a series of methods and observations. It outlines the global architecture of the processing system, including HTML cleaning and the use of various linguistic and visual clues for accurate title identification. Main issues addressed include overcoming noise from web pages and refining the hierarchy between tasks and their sub-tasks.


















































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)










