Downloaded 58 times





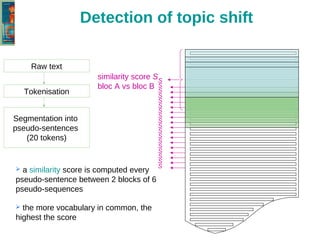
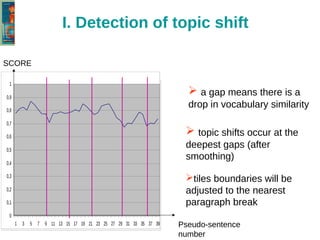

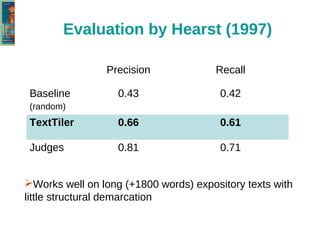


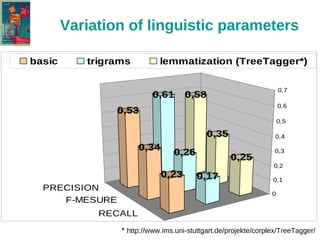
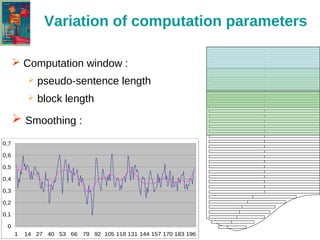
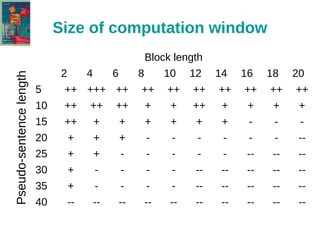







The document discusses the text-tiling algorithm developed by Marti Hearst, which segments expository texts into coherent multi-paragraph units based on subtopic structure. It details experimentation conducted by master's students at Université Toulouse Le Mirail, focusing on different linguistic and computational parameters to evaluate the algorithm's effectiveness, highlighting issues with topic shift detection and inter-annotator agreement. The findings suggest that optimal parameters for the algorithm vary with the text characteristics, and the document concludes with a proposal for adaptive text-tiling techniques.























![Algorithm Design and Problem Solving [Autosaved].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/algorithmdesignandproblemsolvingautosaved-230525024624-6a6fb3b2-thumbnail.jpg?width=640&height=640&fit=bounds)










































