Download as PDF, PPTX






![7/50
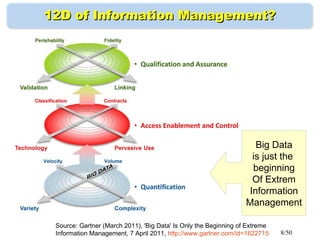
Gartner Big Data Model ?Gartner Big Data Model ?
Challenge of 'Big Data' is to manage Volum, Variety and Velocity.Challenge of 'Big Data' is to manage Volum, Variety and Velocity.
Volume
(amount of data)
Velocity
(speed of data in/out)
Variety
(data types, sources)
Batch Job
Realtime
TB
EB
Unstructured
Semi-structured
Structured
PB
Source :
[1] Laney, Douglas. "3D Data Management: Controlling
Data Volume, Velocity and Variety" (6 February 2001)
[2] Gartner Says Solving 'Big Data' Challenge Involves
More Than Just Managing Volumes of Data, June 2011](https://image.slidesharecdn.com/13-07-08crawlzillapersonalsearchengine-130707151909-phpapp02/85/RMLL-2013-Build-Your-Personal-Search-Engine-using-Crawlzilla-7-320.jpg)


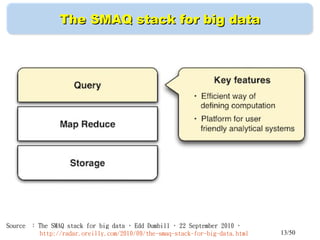

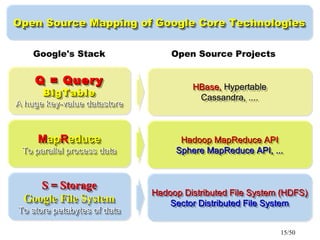


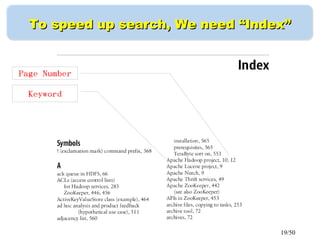








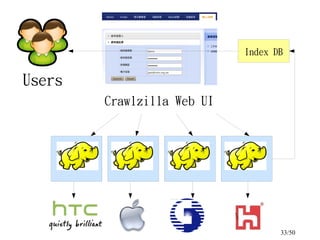
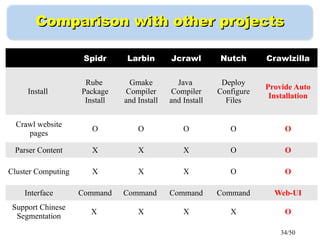
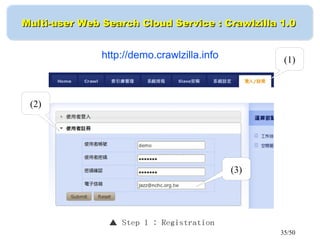
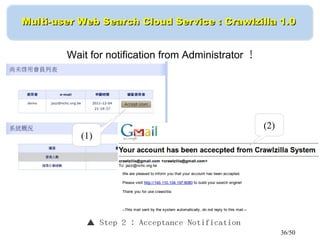




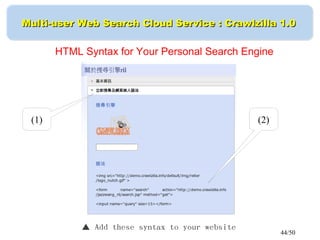
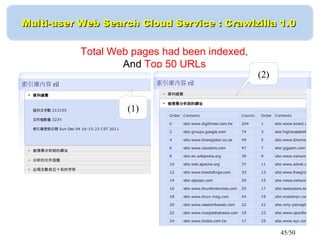
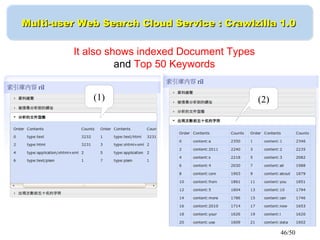
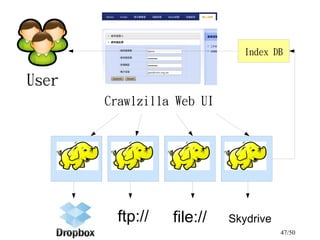




This document discusses building a personal search engine using Crawlzilla. It begins with introductions from Jazz Wang, a speaker from NCHC Taiwan who is a co-founder of Hadoop.TW. It then provides an overview of Crawlzilla, a cluster-based web crawler and search engine that supports Chinese word segmentation and multiple users/indexes. The document demonstrates how to use Crawlzilla through a multi-step process of registering for an account, receiving an acceptance notification, and then logging in to access the search functionality.






















































































