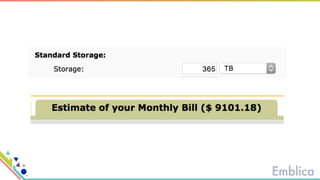
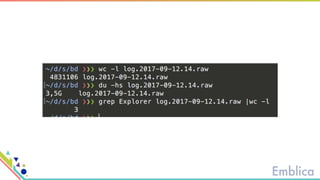
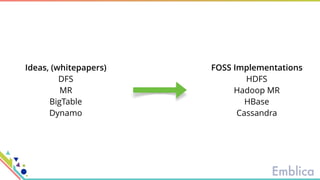
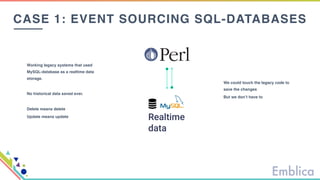
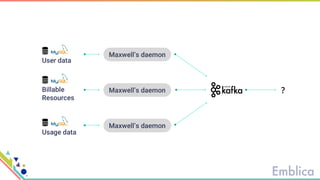
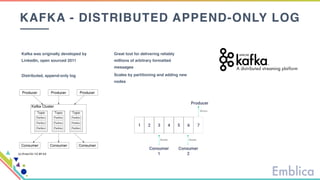
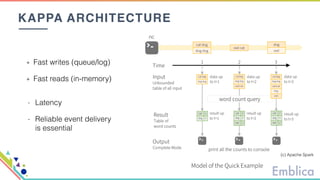
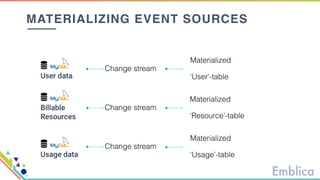
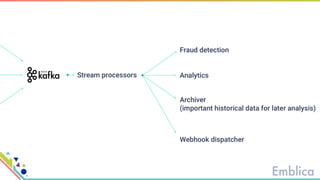
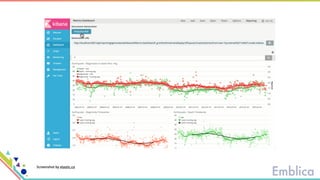
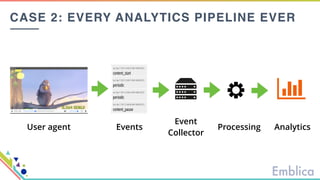
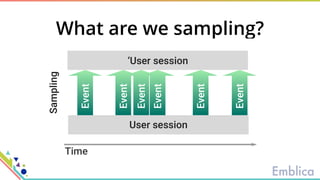
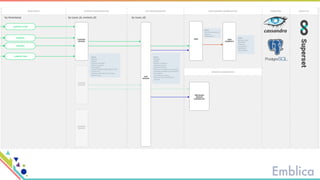
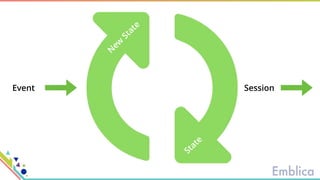
This document discusses open source tools for big data. It begins with an introduction to Emblica, a small company of 5 people focused on data engineering, DevOps, and machine learning. It then discusses what constitutes "big data" in terms of volume, velocity, and variety. While the scale may not be as large as Facebook's data, open source big data tools can still be useful for datasets as small as gigabytes. Examples of big data include activity data, sensor data, and unstructured data. The document then outlines the history of open source data processing tools and frameworks like Google File System (GFS), Hadoop, Spark, Kafka, and Kappa architecture. It provides two use cases utilizing these tools: