Downloaded 11 times




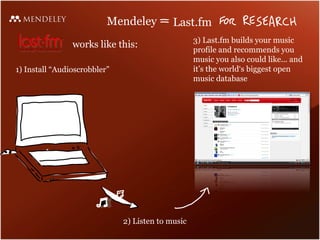

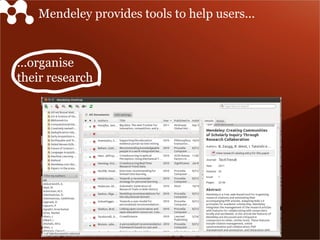
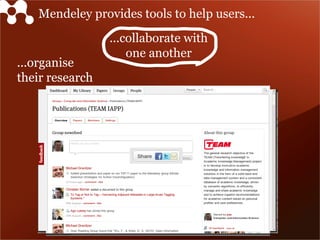

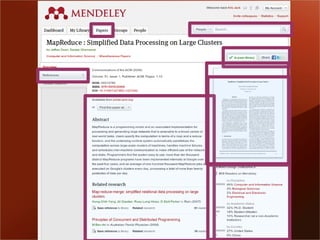




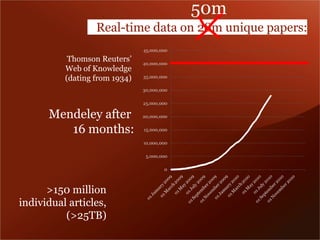






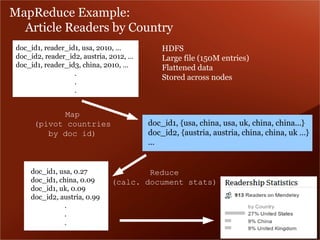


















The document discusses Mendeley's evolution as a large data technology startup focused on transforming research processes, highlighting the challenges faced with scalability due to increased user and article volume. It details their adoption of Hadoop and AWS for effective data storage and processing, emphasizing the importance of planning for scalability and the costs associated with managing large data systems. Mendeley aims to efficiently provide research recommendations and search capabilities while managing a significant scientific database.
















































































