Download as PDF, PPTX




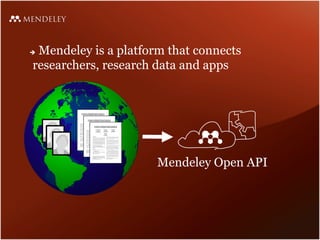
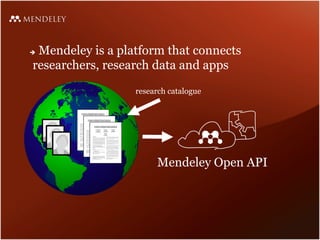
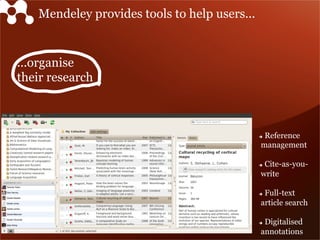
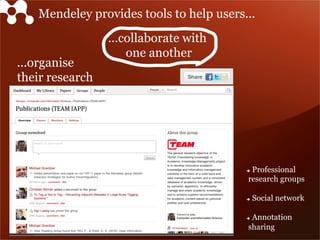

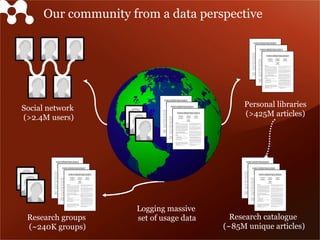





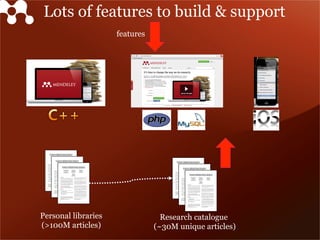

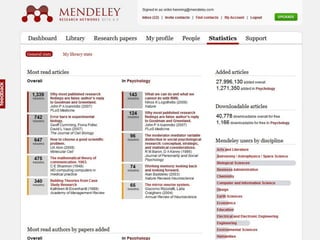


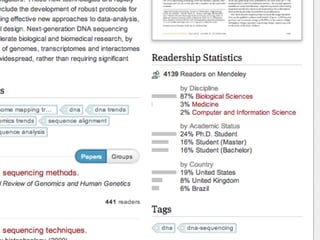











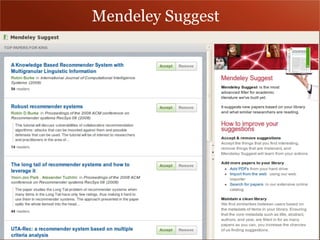


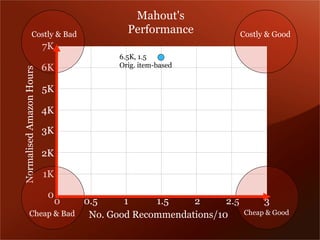
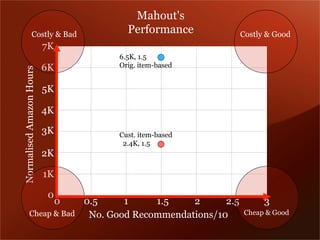
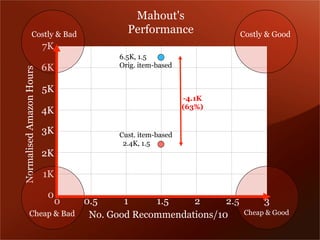
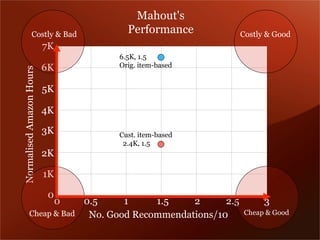
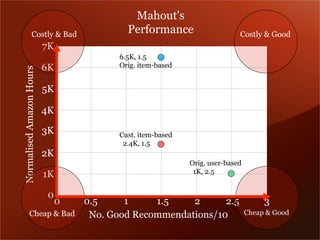
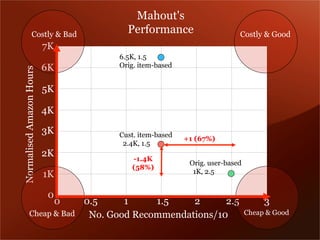
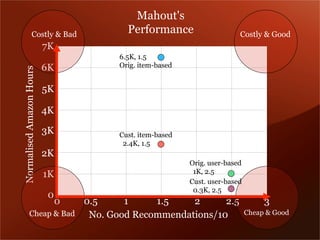
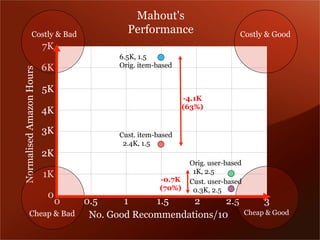
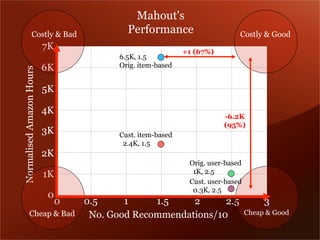

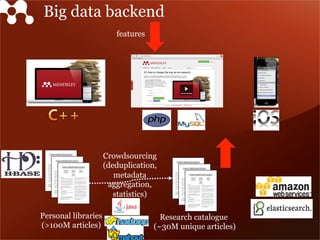

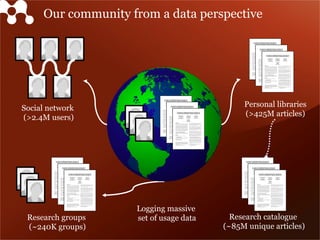

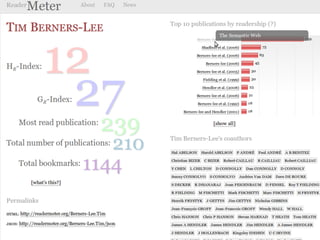

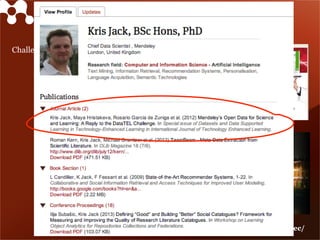








Mendeley is a comprehensive platform that connects researchers with tools for reference management, collaboration, and discovery of research. The presentation discusses Mendeley’s challenges in scaling its backend system to manage a growing research catalogue and the transition to using Hadoop for improved performance. Additionally, it emphasizes Mendeley's commitment to openness and collaboration with academia for building applications on its platform.



































































































