

























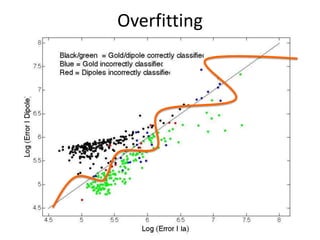




The document outlines key principles and methodologies for teaching and learning in the fields of big data and machine learning, emphasizing creativity, collaboration, and the importance of personal connections. It covers foundational concepts in machine learning, including classification and regression problems, feature extraction, and algorithm application, along with practical steps and pitfalls in data science. The document also references machine learning competitions as a practical application to research and improve model accuracy.























![[Webinar] How Big Data and Machine Learning Are Transforming ITSM](https://cdn.slidesharecdn.com/ss_thumbnails/webinarhowbigdataandmachinelearningaretransformingitsm-160602174503-thumbnail.jpg?width=640&height=640&fit=bounds)































































