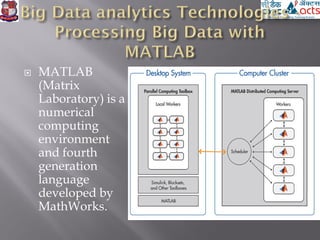
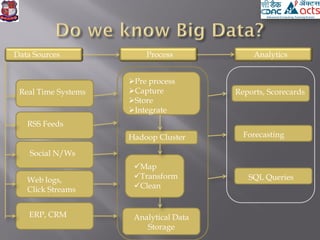
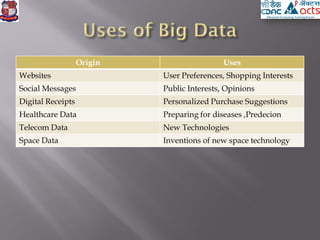
This document provides an overview of big data concepts including definitions of big data, sources of big data, and uses of big data analytics. It discusses technologies used for big data including Hadoop, MapReduce, Hive, Mahout, MATLAB, and Revolution R. It also addresses challenges around big data such as lack of standardization and extracting meaningful insights from large datasets.











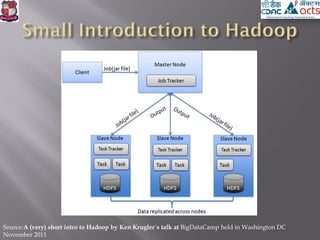
![ The Apache Hadoop software library is a
framework that allows for the distributed
processing of large data sets across clusters of
computers using simple programming
models.[from http://hadoop.apache.org/]
IBM, Yahoo, Microsoft have their own products
and technology for Big Data.
Hadoop project is started by Yahoo research.](https://image.slidesharecdn.com/bigdataanalytics1-131005020429-phpapp01/85/Big-data-analytics-1-14-320.jpg)