Downloaded 879 times















![References
[1] IEEE, Data Mining with Big Data, January 2014
[2] McKinsy Global Institute, Big Data: The next frontier for innovation, competition and
productivity- May 2011
[3] Xindong Wu, Xinguan Zhu, Gong-Qing Wu, Wei Ding, 2013, Data Mining with Big Data
[4] Ahmed and Karypis 2012, Rezwan Ahmed, George Karpis, Algorithms for mining the evolution
of conserved relational states in dynamic network
[5] Wu X. 2000, Building Intelligent Learning Database Systems, AI Magazine
[6] Oracle, June 2013,Unstructured Data Management with Oracle Database 12c
[7] Valery A.Petrushin, Jia-Yu Pan, Cees G.M.Snoek, 2010,Tenth International Workshop on
Multimedia Data Mining
[8] Big data[Online].Available:www.en.wikipedia.org/wiki/Big_data
[9] Big data [Online]. Available: www.webopedia.com/TERM /B/ big_data.html
[10]IBM big data and information management [Online]. Available: www-
01.ibm.com/software/data/bigdata
[11] Big data [Online]. Available: www.adainbigdata.com
[12] Big Data Explained [Online]. Available: www.mongodb.com/big-data-explained
[13] Big data [Online]. Available: www.sas.com/en_us/insights/big-data/what-is-big-data.html
[14] Big Data Mining Tools[Online]. Available: www.albertbifet.com/big-data-mining-tools](https://image.slidesharecdn.com/bigdatamining-140605124655-phpapp02/85/Big-data-mining-16-320.jpg)



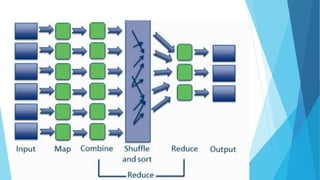
This document discusses big data mining. It defines big data as large volumes of structured and unstructured data that are difficult to process using traditional methods due to their size. It describes the characteristics of big data including volume, variety, velocity, variability, and complexity. It also discusses challenges of big data such as data location, volume, hardware resources, and privacy. Popular tools for big data mining include Hadoop, Apache S4, Storm, Apache Mahout, and MOA. Hadoop is an open source software framework that allows distributed processing of large datasets across clusters of computers. Common algorithms for big data mining operate at the model and knowledge levels to discover patterns and correlations across distributed data sources.



































































