Downloaded 42 times


















This document discusses integrating R with Hadoop. It begins with an introduction to R and its uses for statistical analysis and data visualization. It then discusses how R can be used with Hadoop to analyze large datasets stored in Hadoop and to execute R code using Hadoop. Examples of R packages that interface with Hadoop components like HDFS, HBase, and MapReduce are provided. Guidelines are given for when it makes sense to integrate R and Hadoop versus using them separately.
Overview of R, its integration with Hadoop, objectives, and contents of presentation.
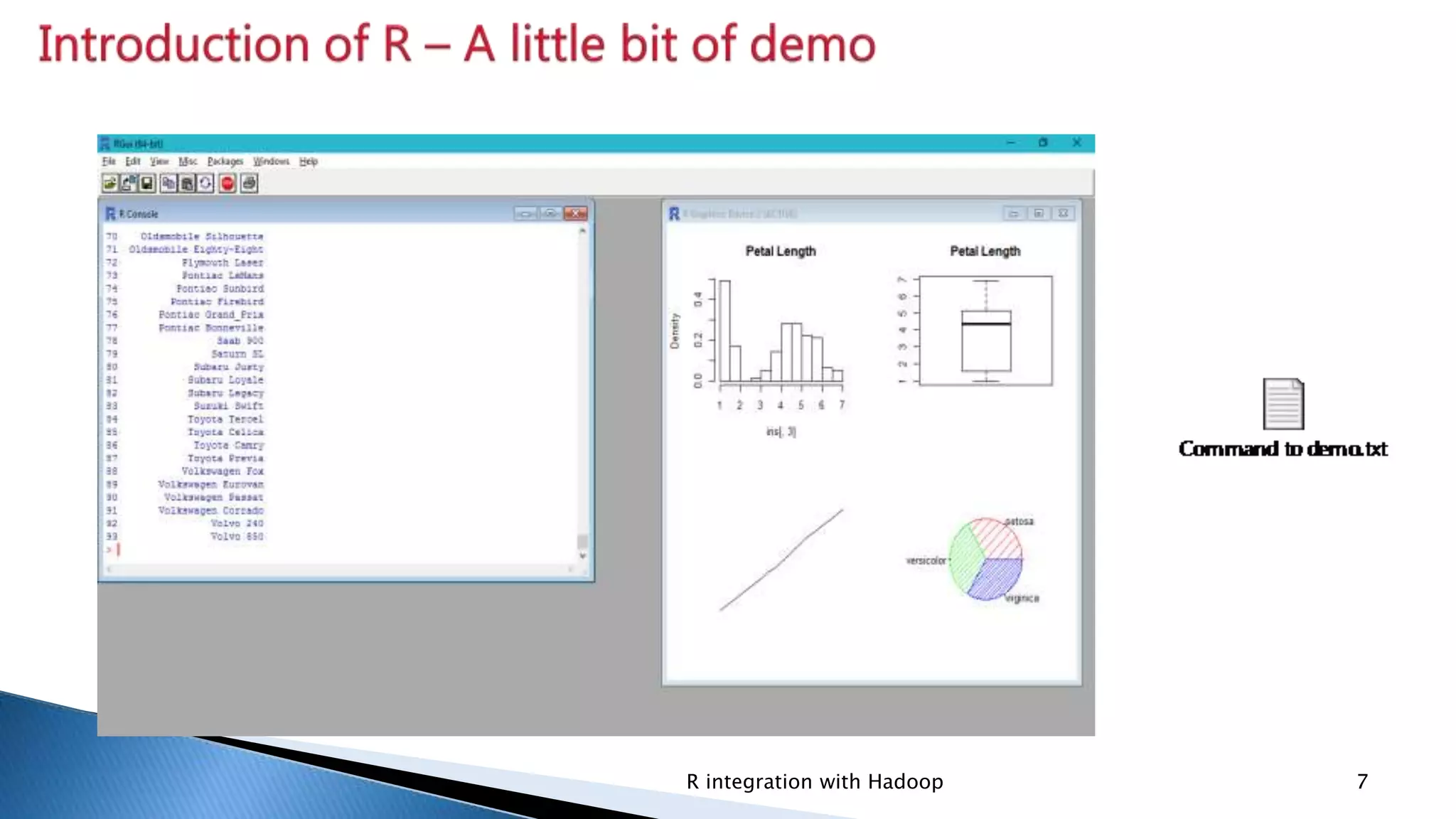
R as software for statistical data analysis; it is open source, highly extensible, but has a steep learning curve.
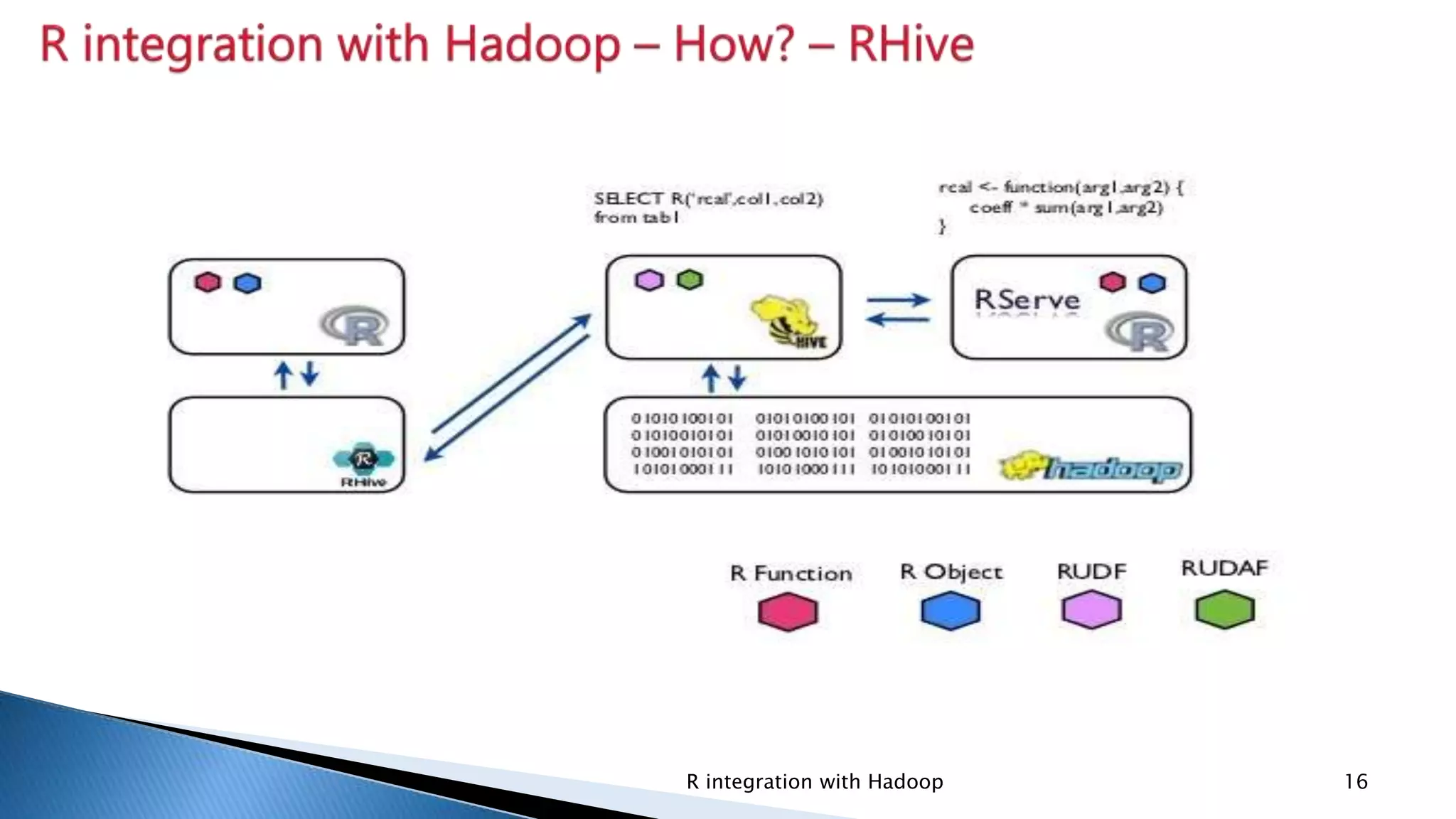
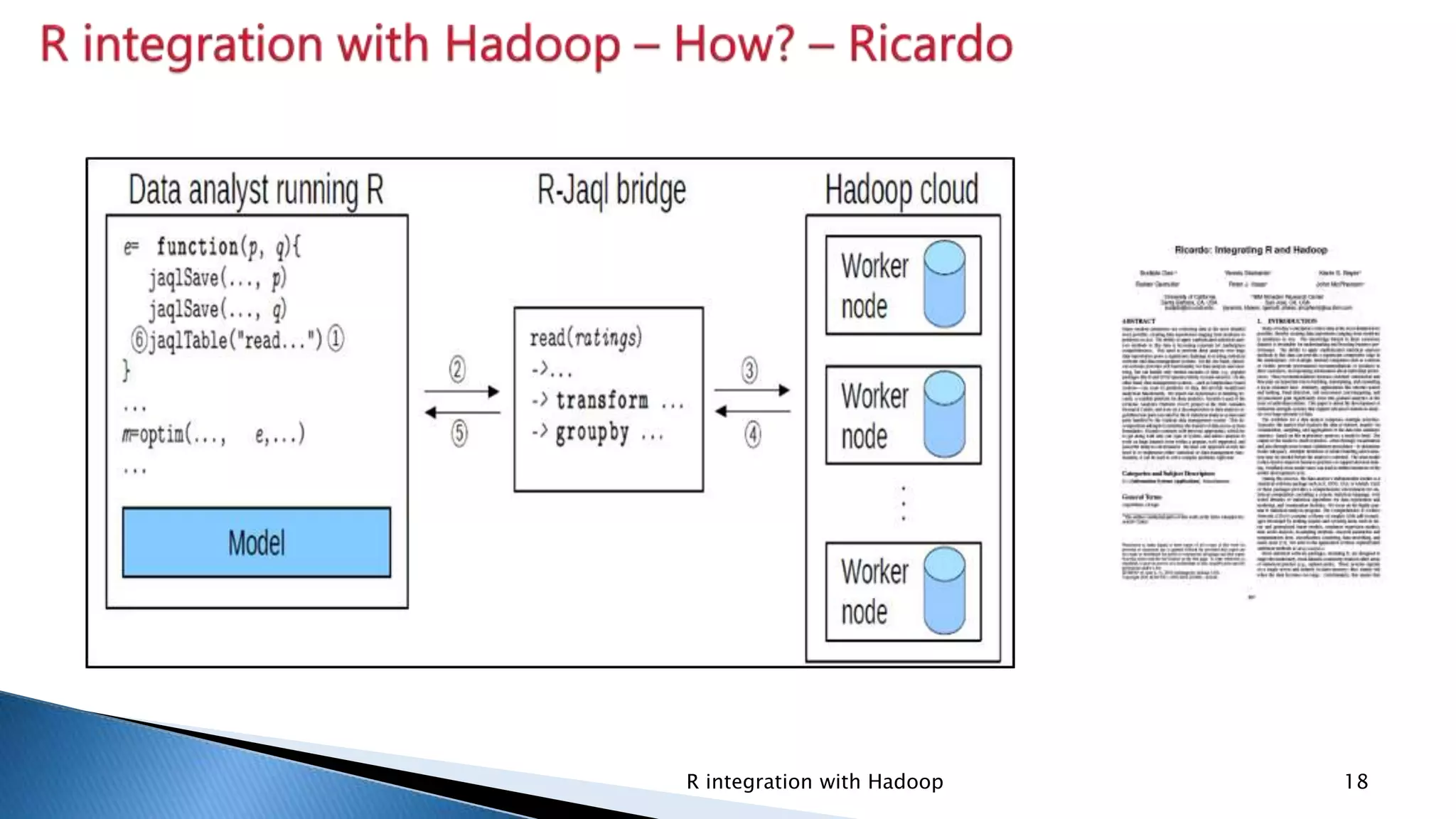
Explains how to utilize R with Hadoop for execution and discusses when to integrate based on strengths and scenarios.
Various scenarios to use R with Hadoop, including data analysis, modeling, machine learning algorithms, and preprocessing.
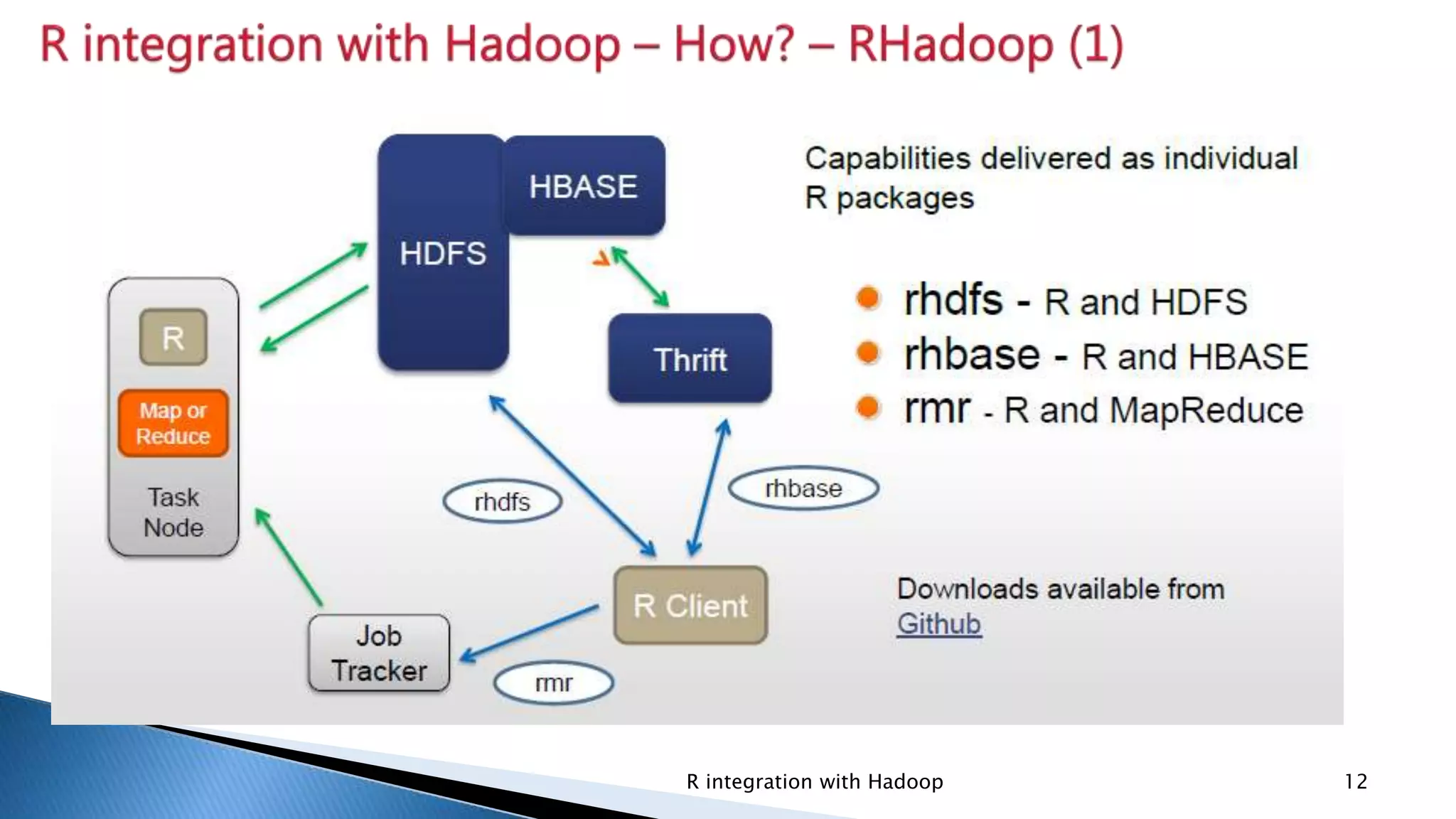
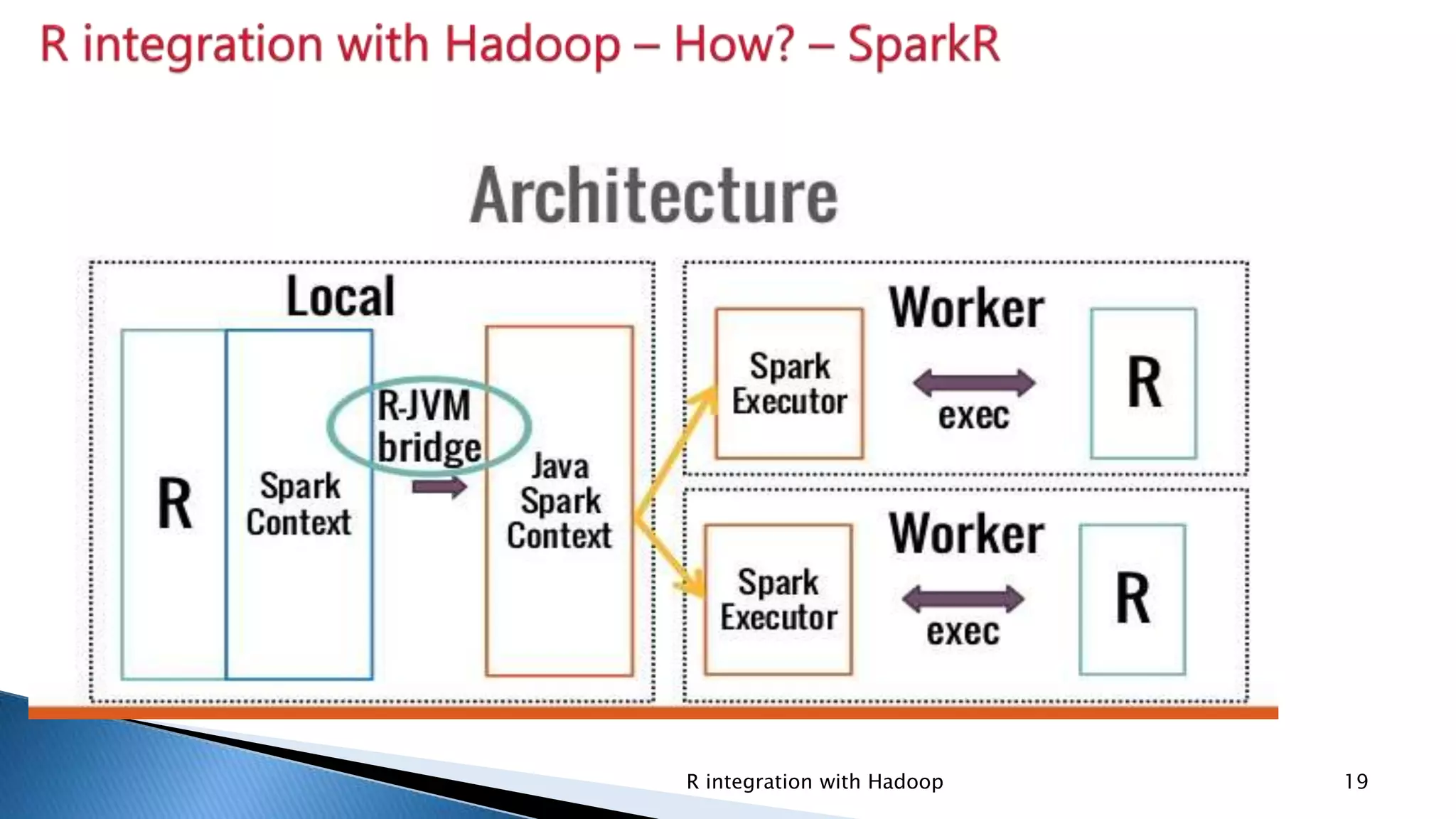
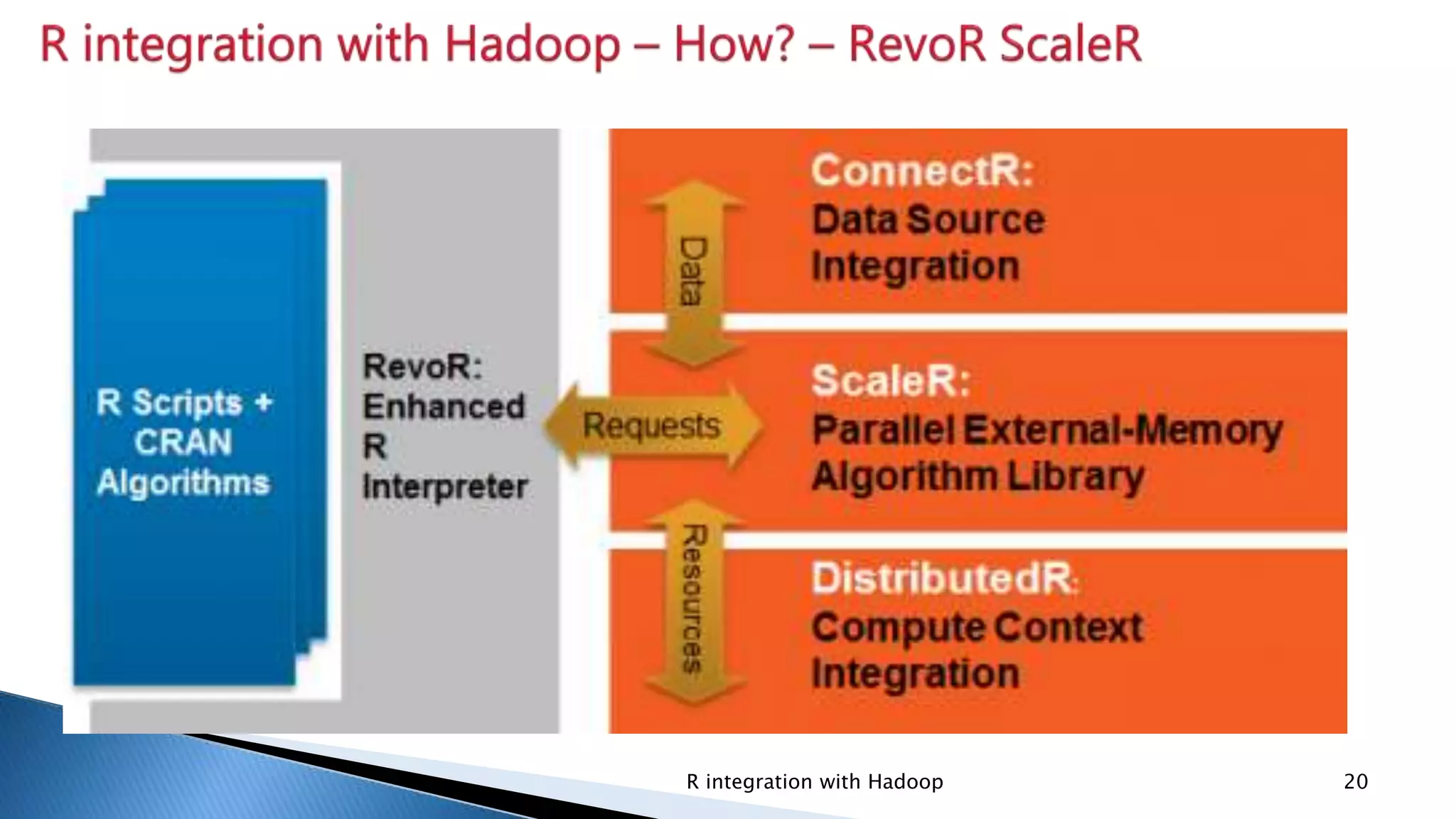
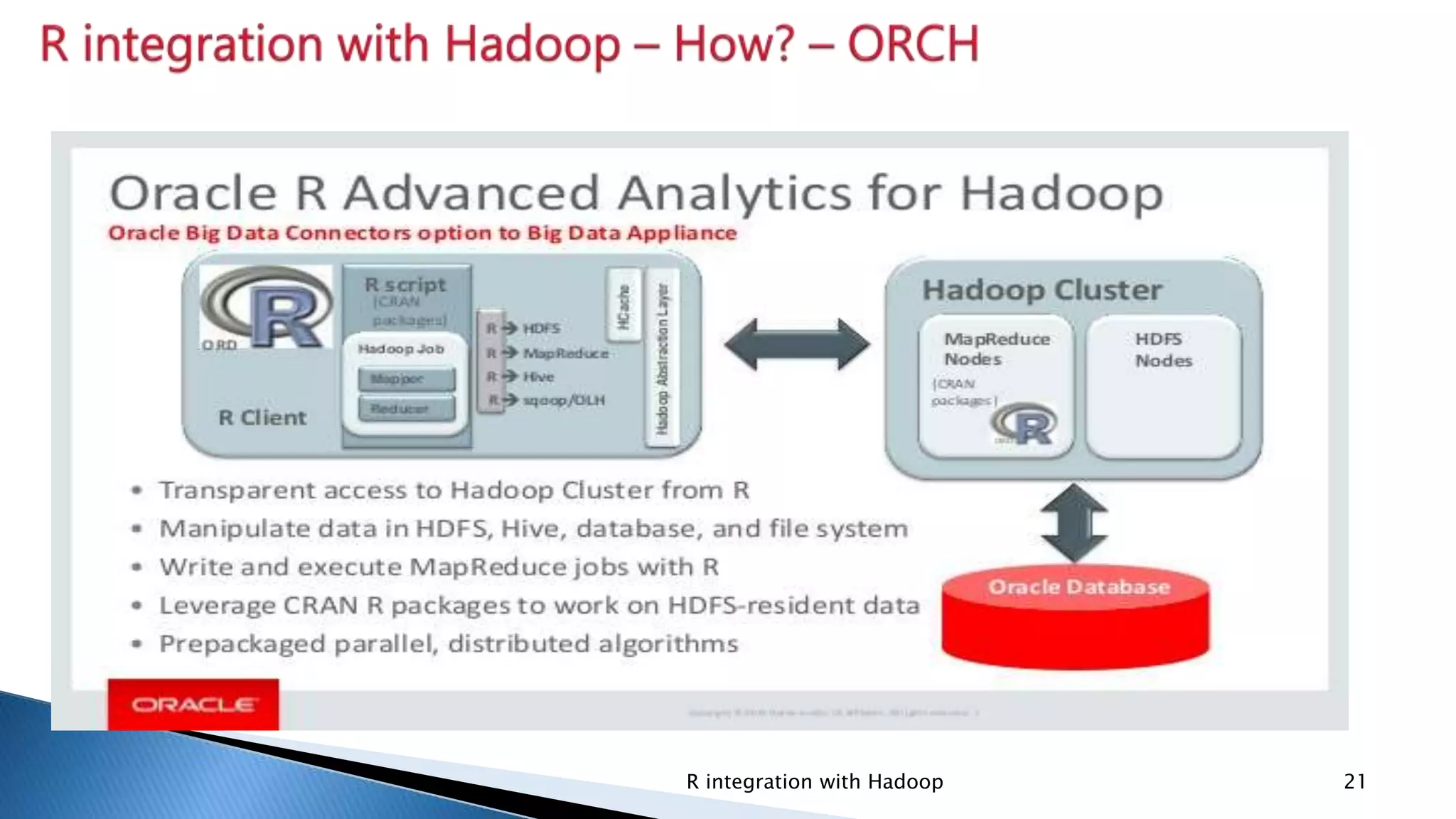
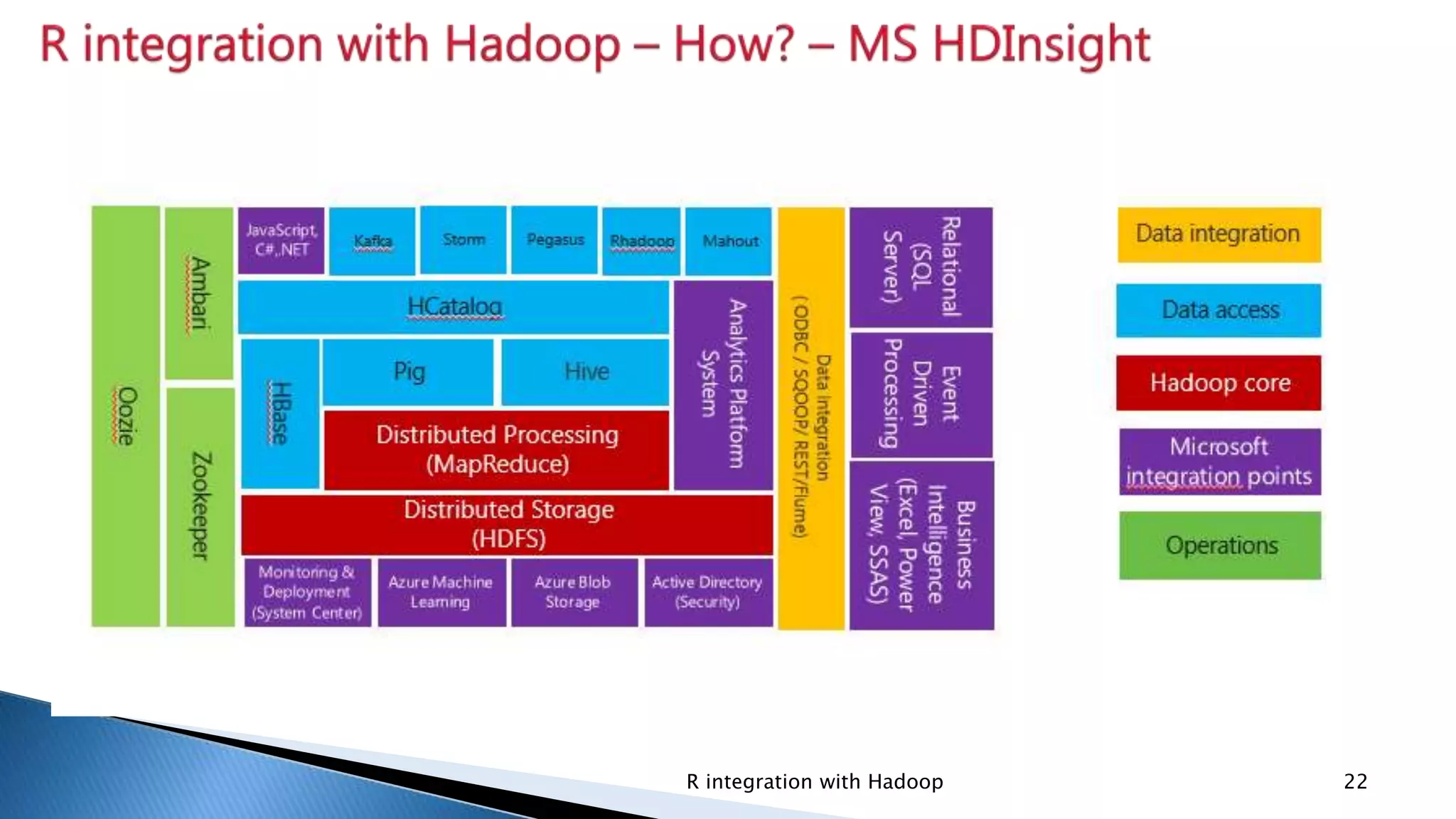
Introduction of rhdfs for HDFS manipulation, rhbase for HBASE tables, and rmr for writing MapReduce programs.
Provides references for further reading on Big Data, Hadoop, and R integration.






















































