Downloaded 23 times







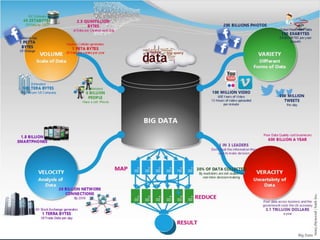
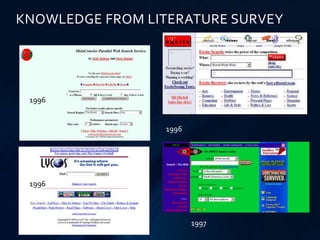



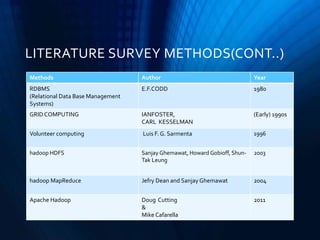







The document discusses big data analytics using Hadoop, highlighting its capability to analyze vast datasets for uncovering business insights and enhancing operational efficiency. It outlines challenges in data processing, such as data silos and the handling of unstructured data, and emphasizes the advantages of adopting technologies like MapReduce and HDFS. Additionally, it reviews the history of Hadoop's development and applications in various sectors, concluding that effective big data analytics can significantly improve business decisions and outcomes.





























































![[IJCT-V3I2P32] Authors: Amarbir Singh, Palwinder Singh](https://cdn.slidesharecdn.com/ss_thumbnails/ijct-v3i2p32-160609071950-thumbnail.jpg?width=640&height=640&fit=bounds)


![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)







![7.__Developing_a_Research_Proposal[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/7-260131073037-df92dd7d-thumbnail.jpg?width=640&height=640&fit=bounds)








