





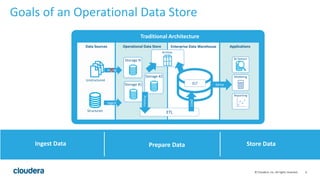
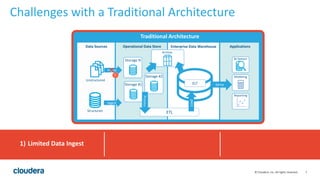
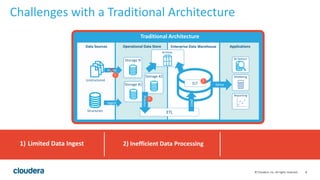
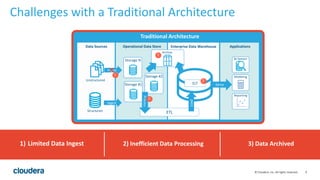
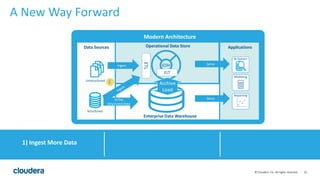
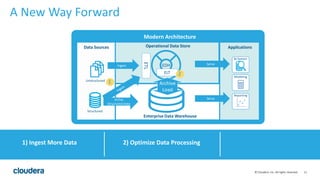
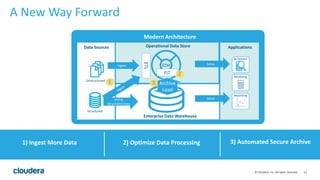



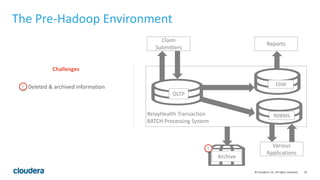
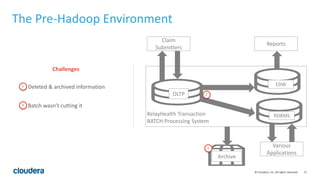
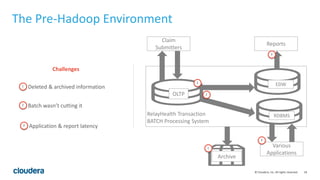
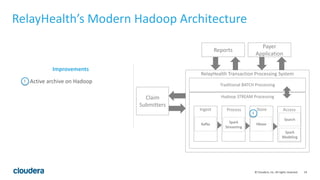
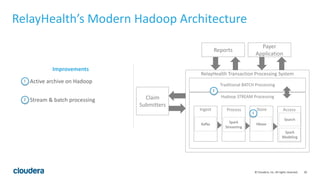
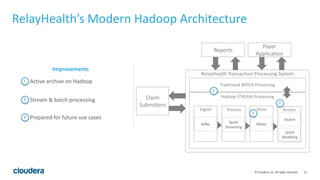
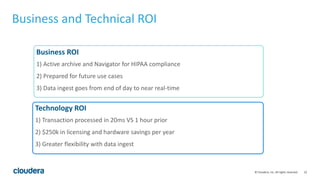




The document discusses the transition from traditional data architectures to modern operational data stores, highlighting the growing need for efficient data ingestion and processing due to the increase in connected devices. It features a case study on RelayHealth, illustrating how they've improved their data processing capabilities using a Hadoop architecture, resulting in faster transaction processing and cost savings. Key takeaways include the importance of starting the transformation process and utilizing community expertise.






















































































