Downloaded 21 times






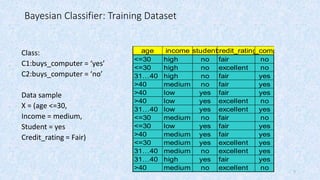





This document provides an overview of Bayesian classification. It begins by explaining that Bayesian classification is a statistical classifier that performs probabilistic predictions based on Bayes' theorem. It then provides an example of how a naive Bayesian classifier would work on a sample training dataset to classify whether someone buys a computer. The document concludes by discussing some advantages, such as being easy to implement and providing good results often, and disadvantages, such as the assumption of class conditional independence losing accuracy when dependencies exist among variables.



































































