






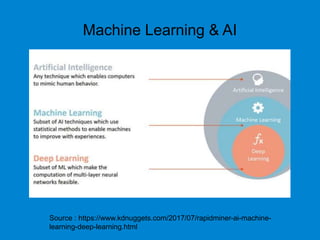




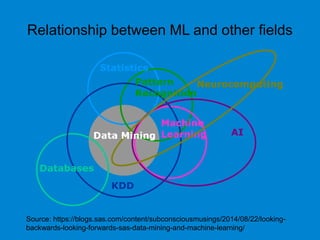
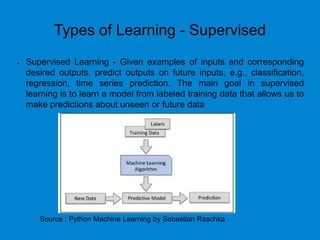

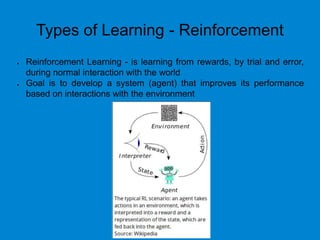






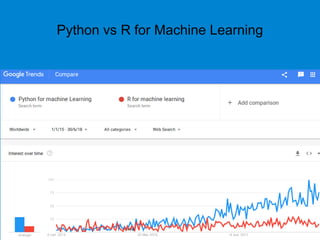

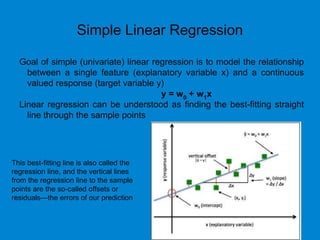
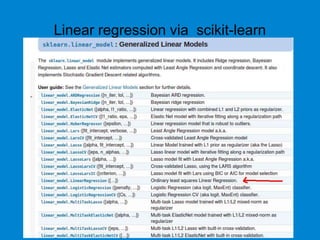



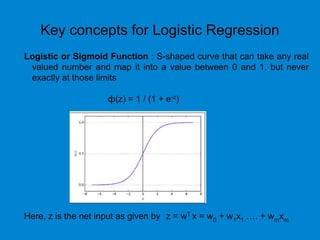


This document provides an overview of machine learning basics including: - A brief history of machine learning and definitions of machine learning and artificial intelligence. - When machine learning is needed and its relationships to statistics, data mining, and other fields. - The main types of learning problems - supervised, unsupervised, reinforcement learning. - Common machine learning algorithms and examples of classification, regression, clustering, and dimensionality reduction. - Popular programming languages for machine learning like Python and R. - An introduction to simple linear regression and how it is implemented in scikit-learn.


























































![7.__Developing_a_Research_Proposal[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/7-260131073037-df92dd7d-thumbnail.jpg?width=640&height=640&fit=bounds)








