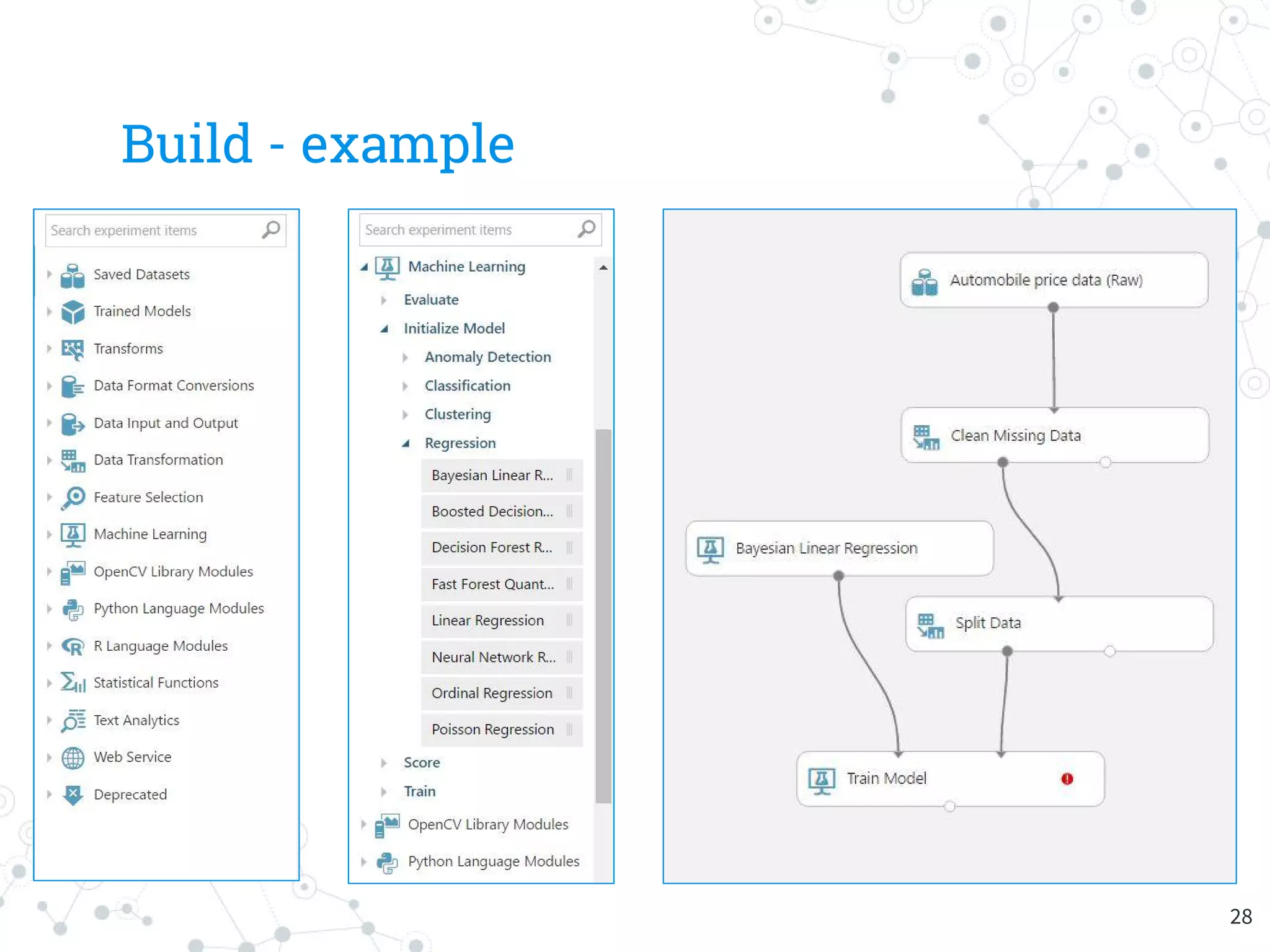
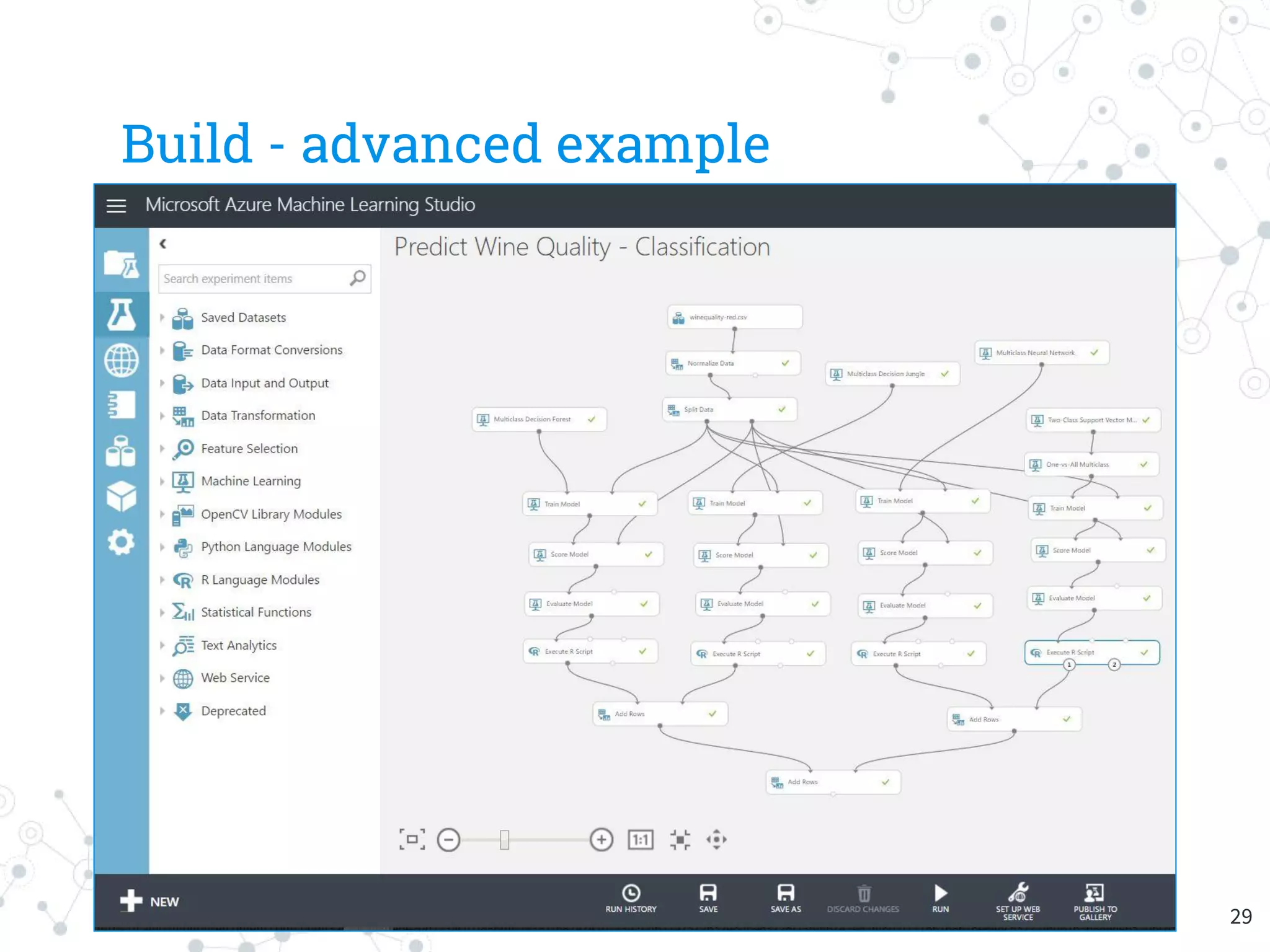
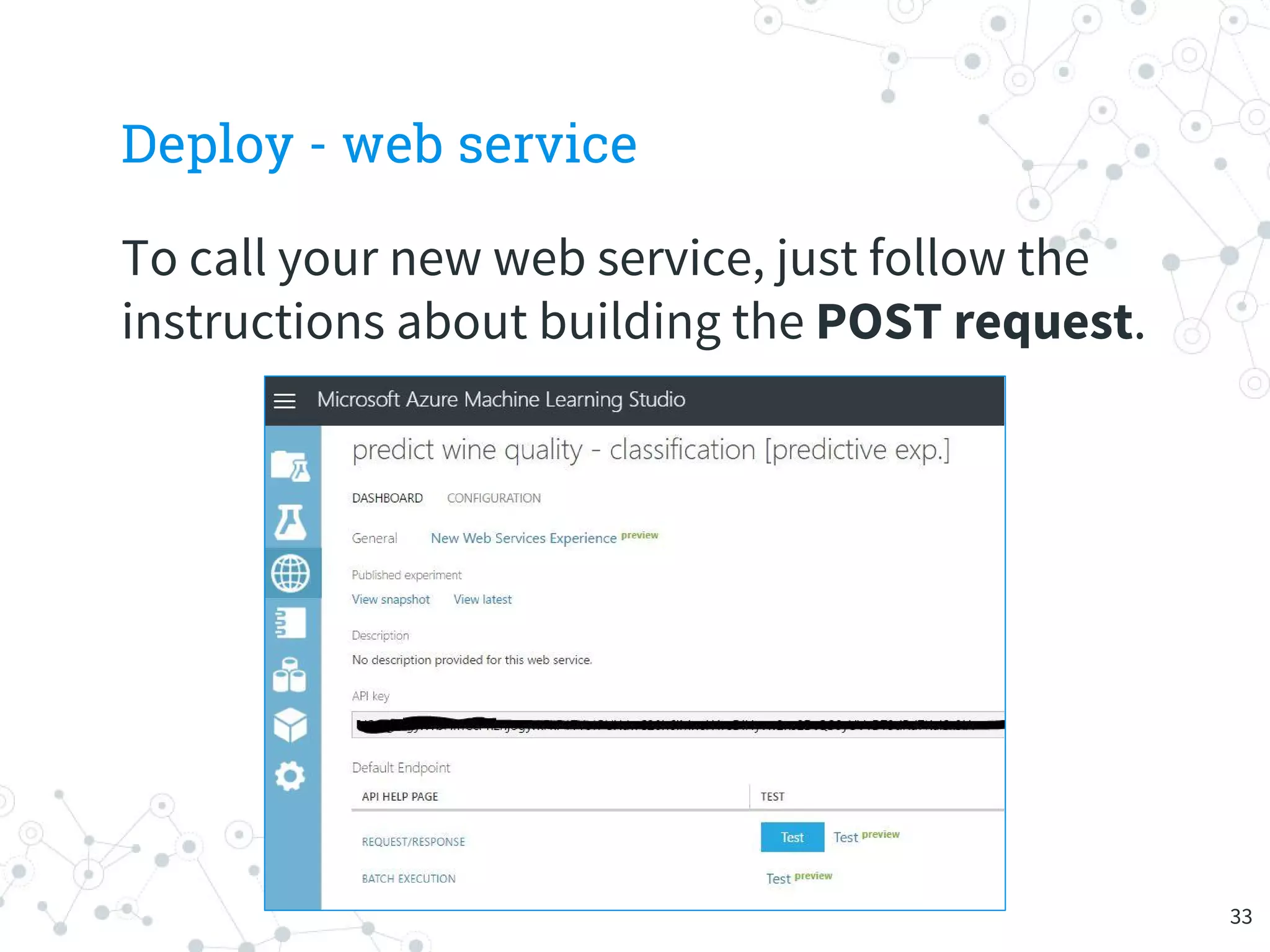
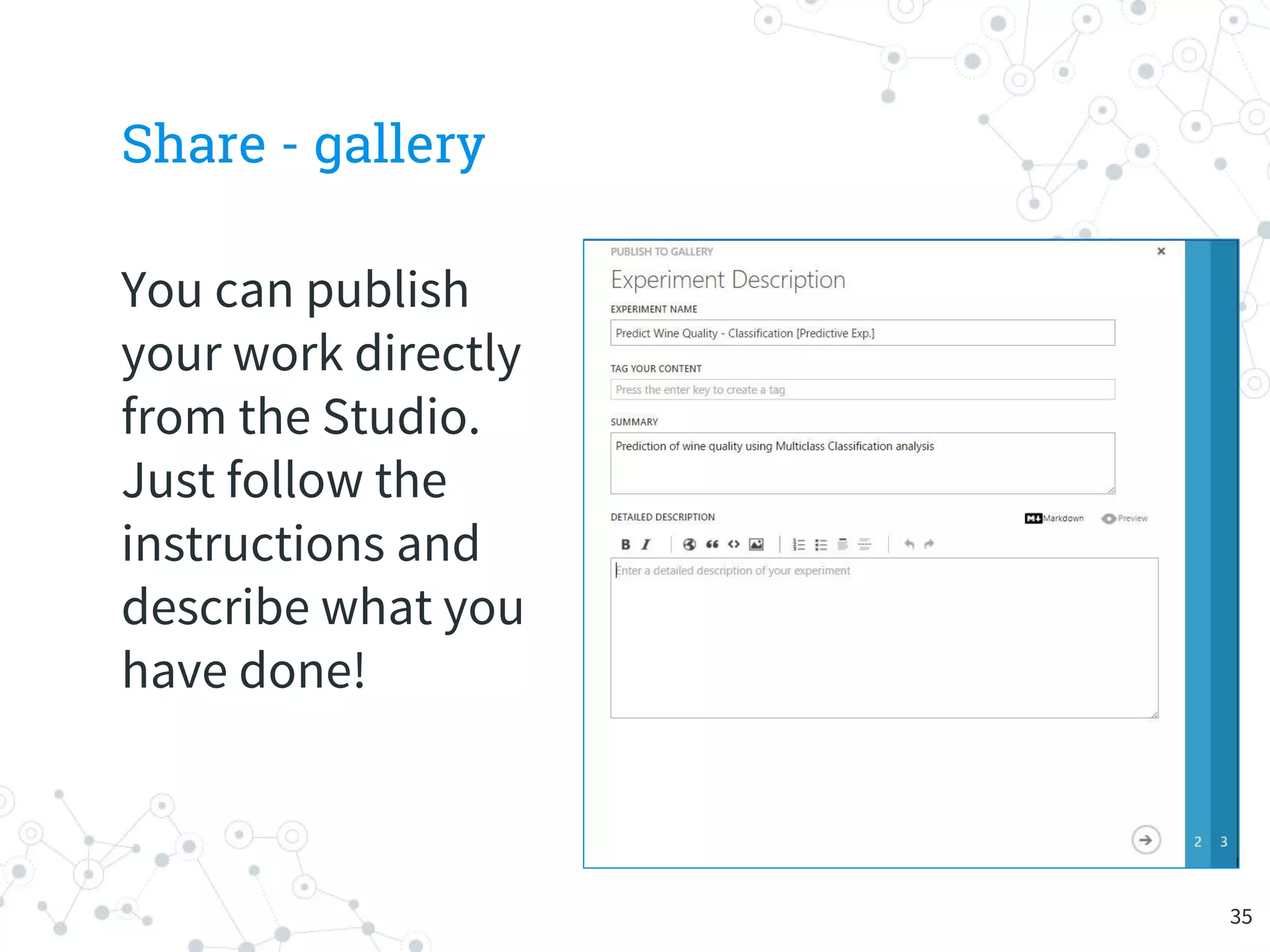
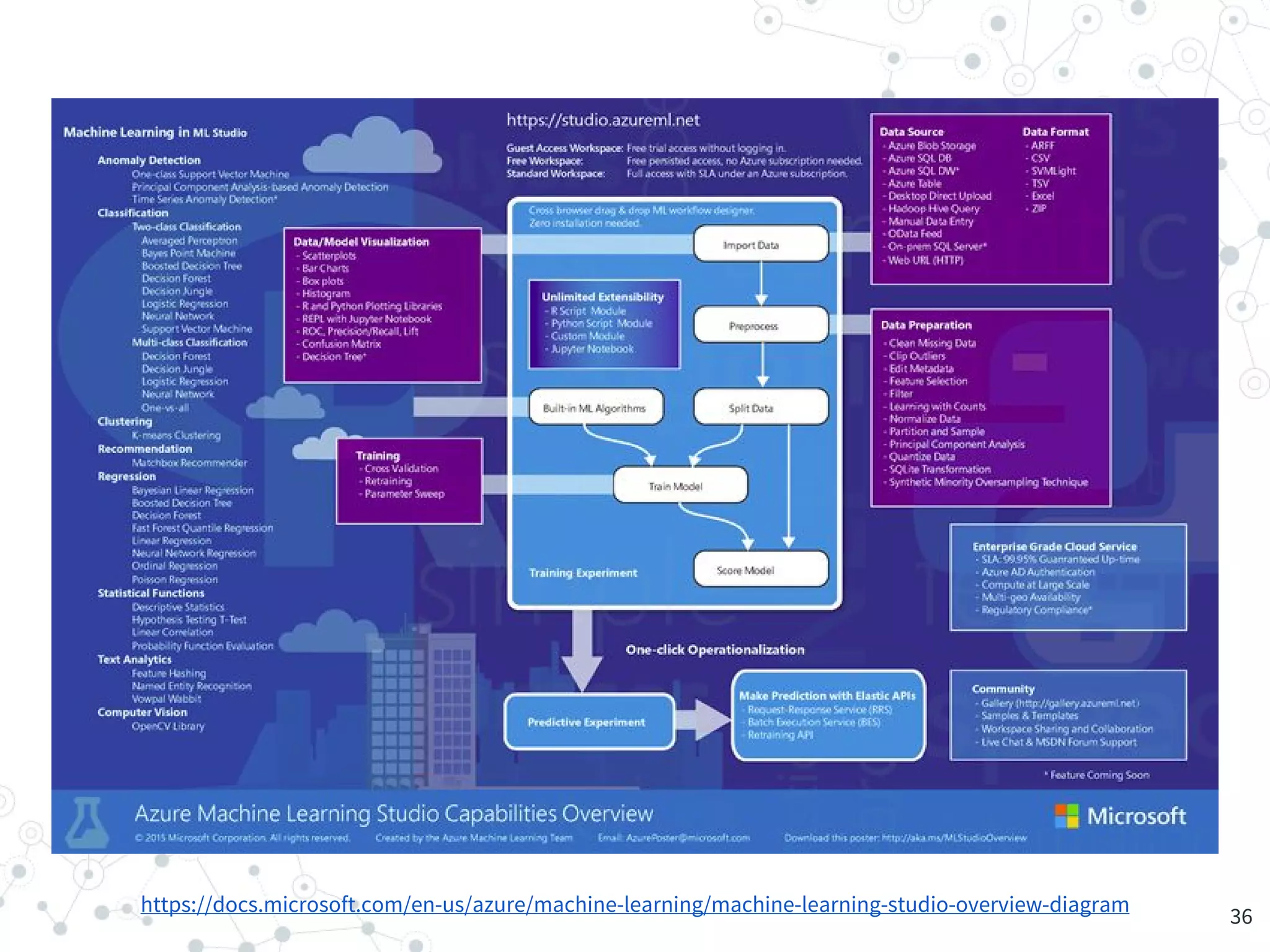
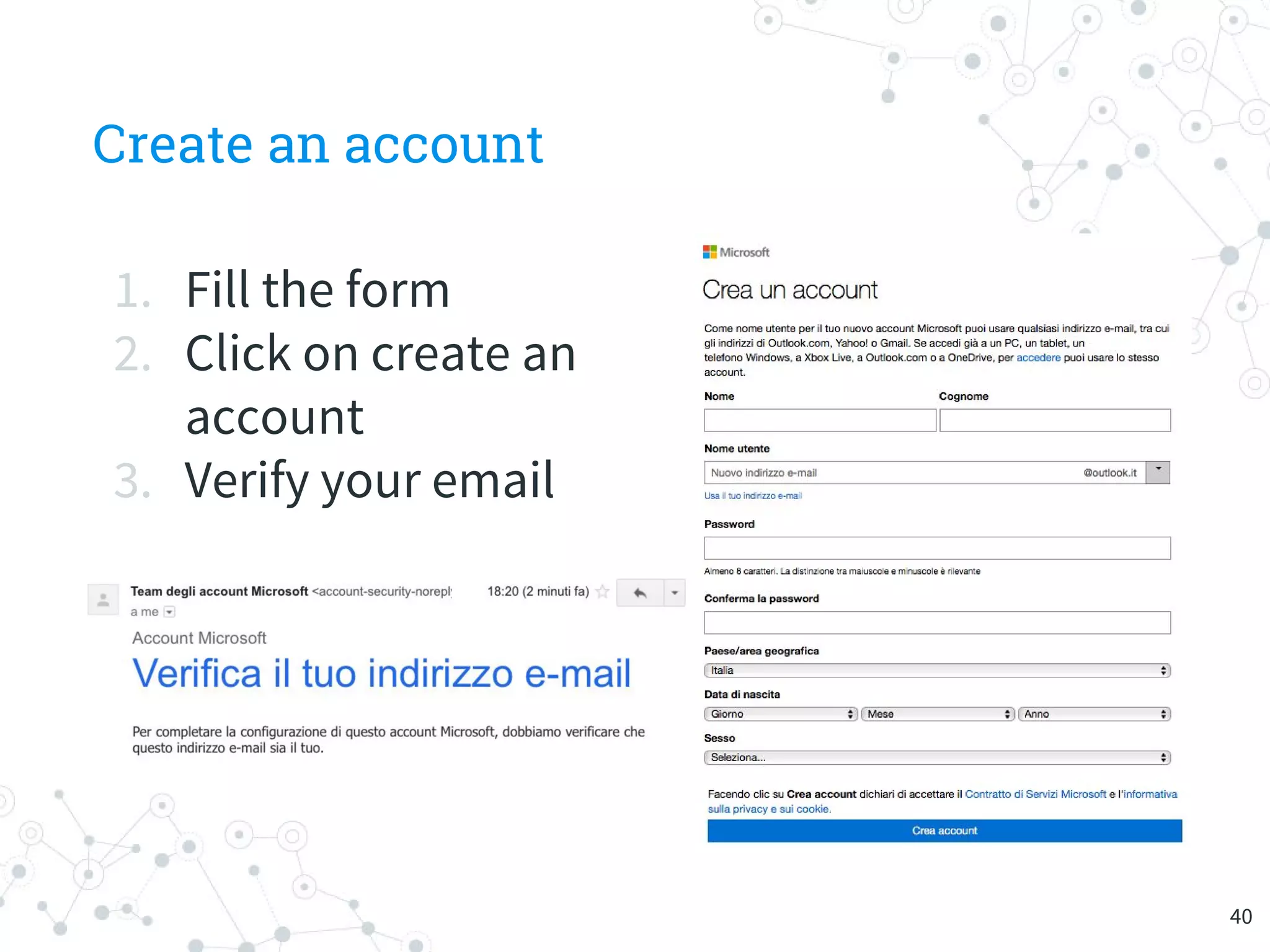
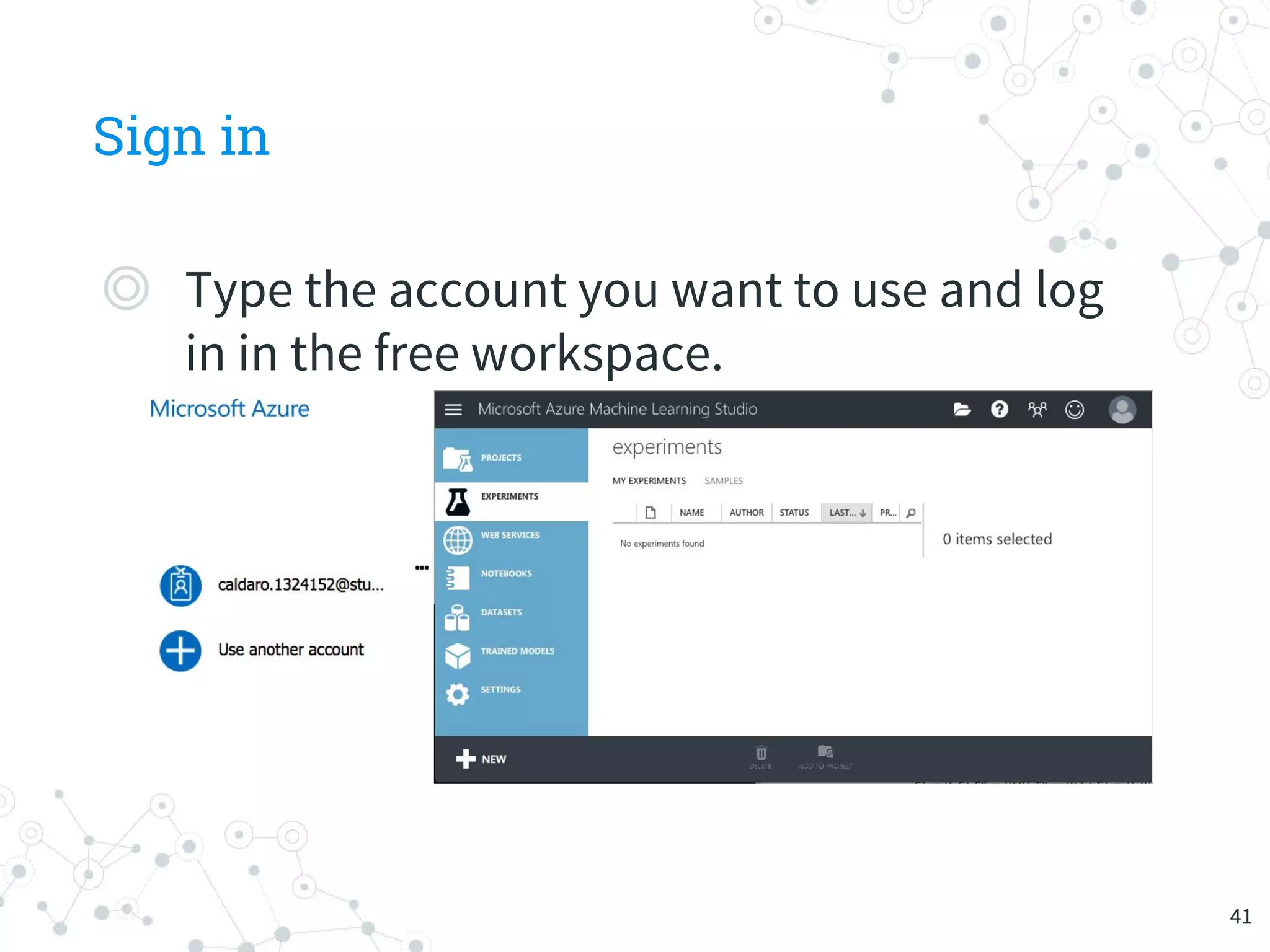
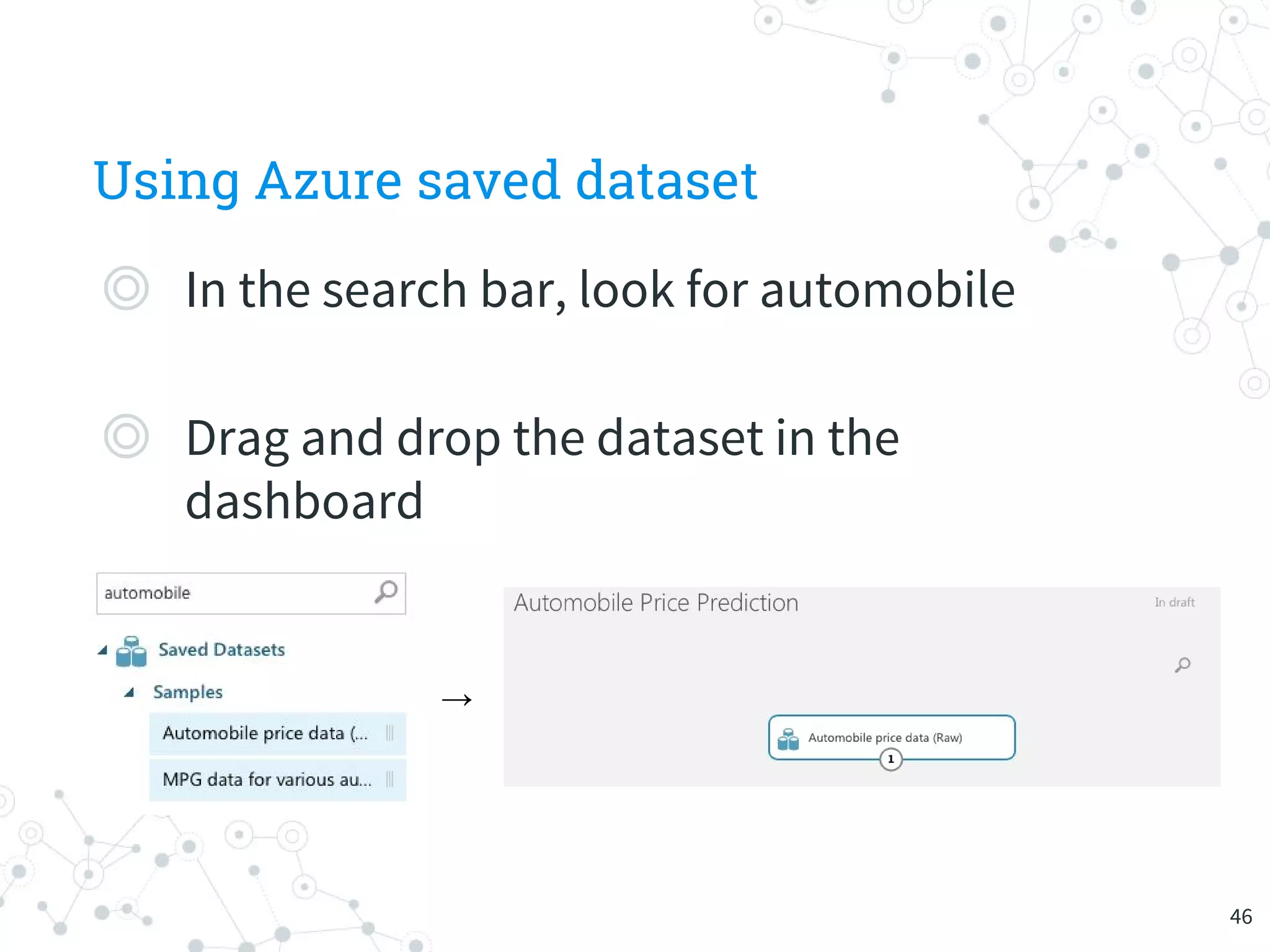
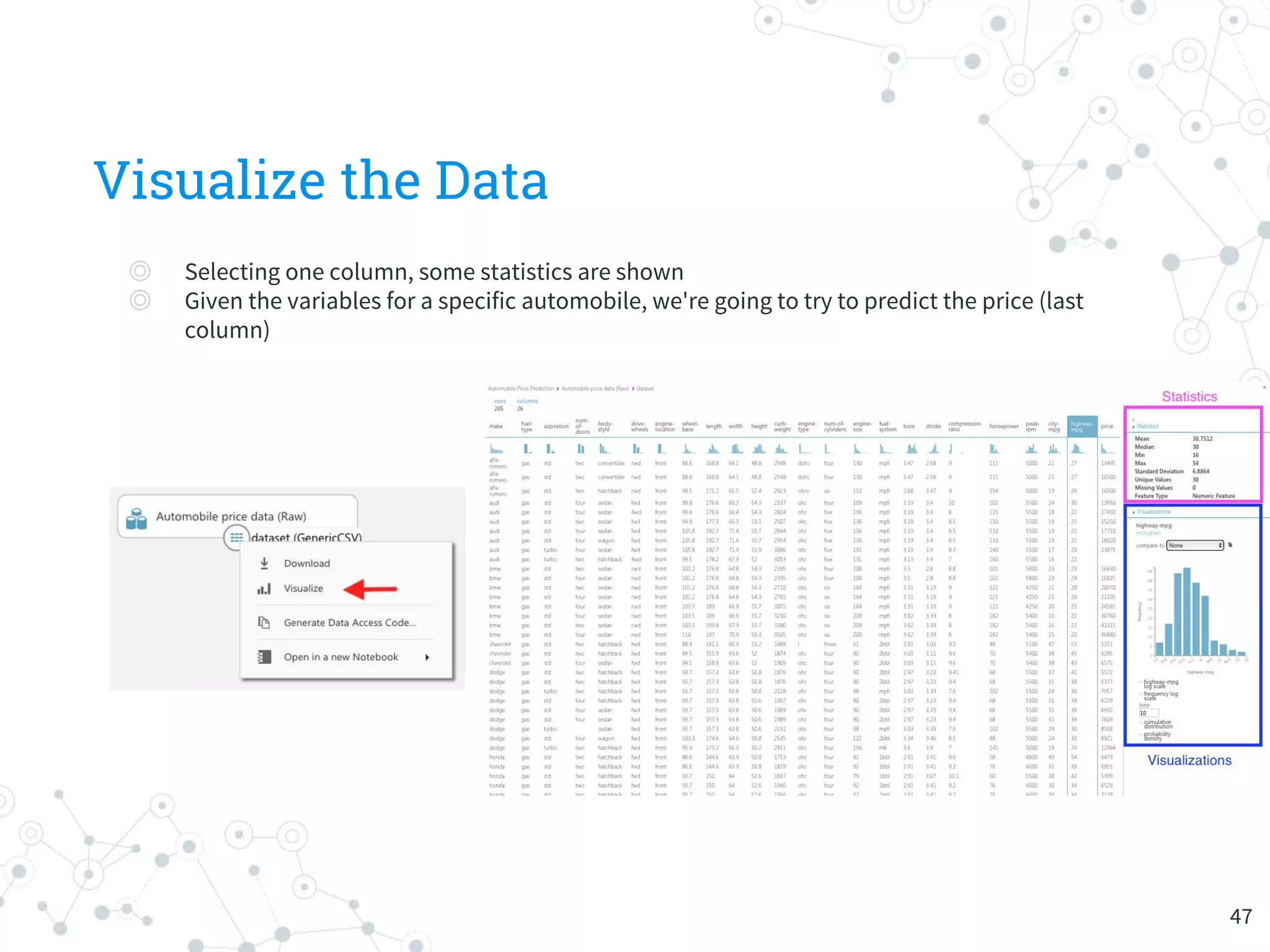
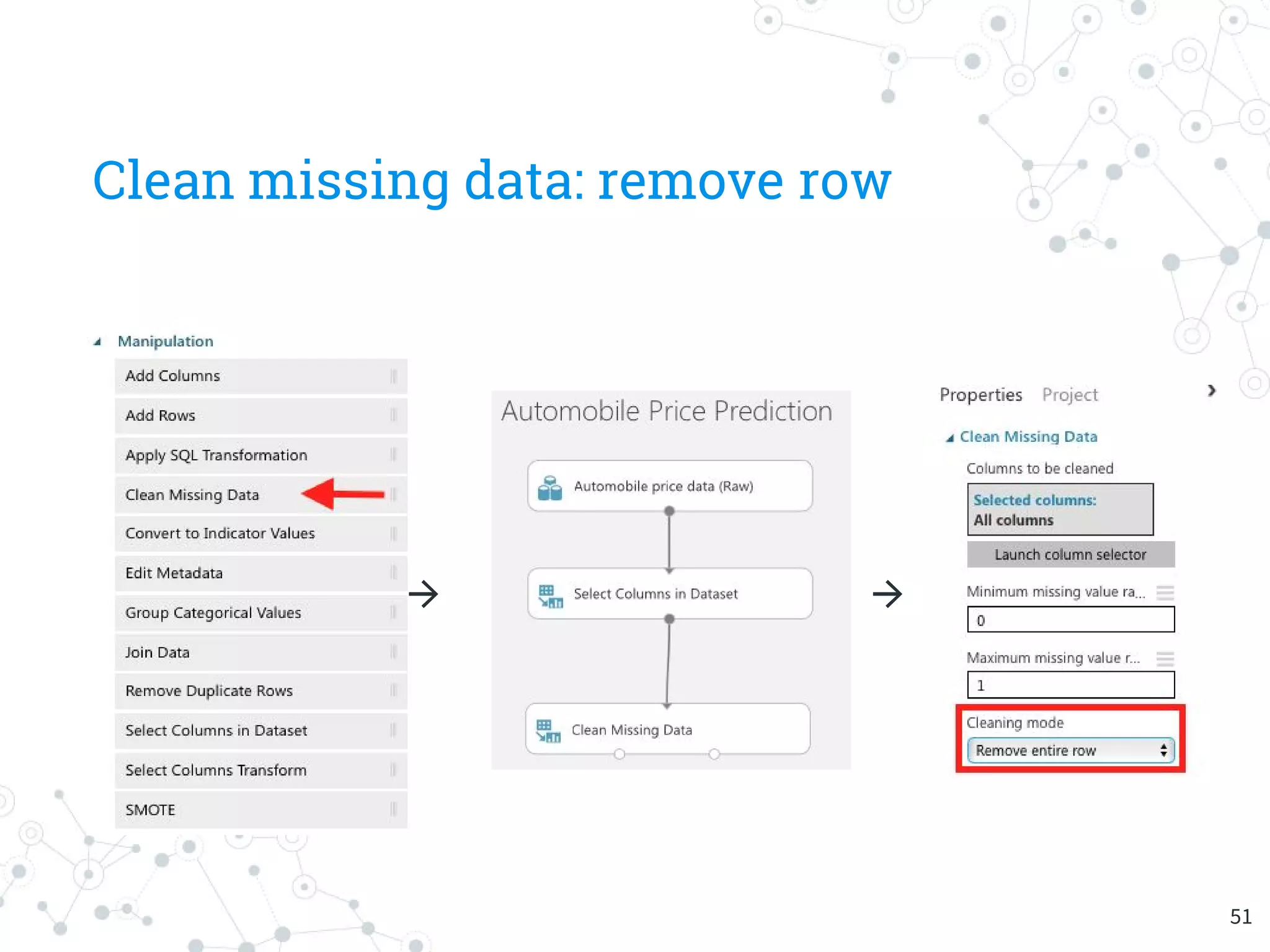
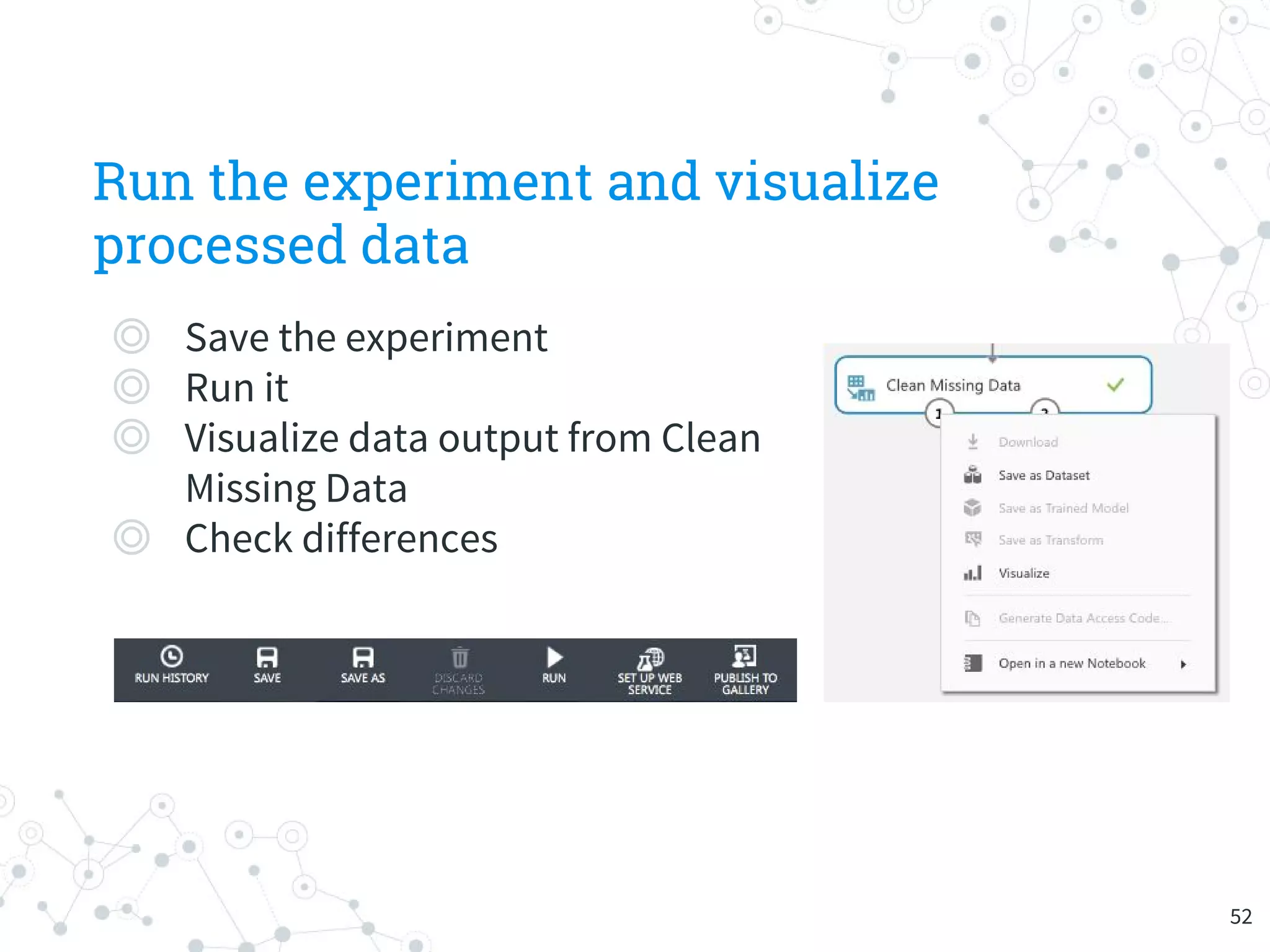
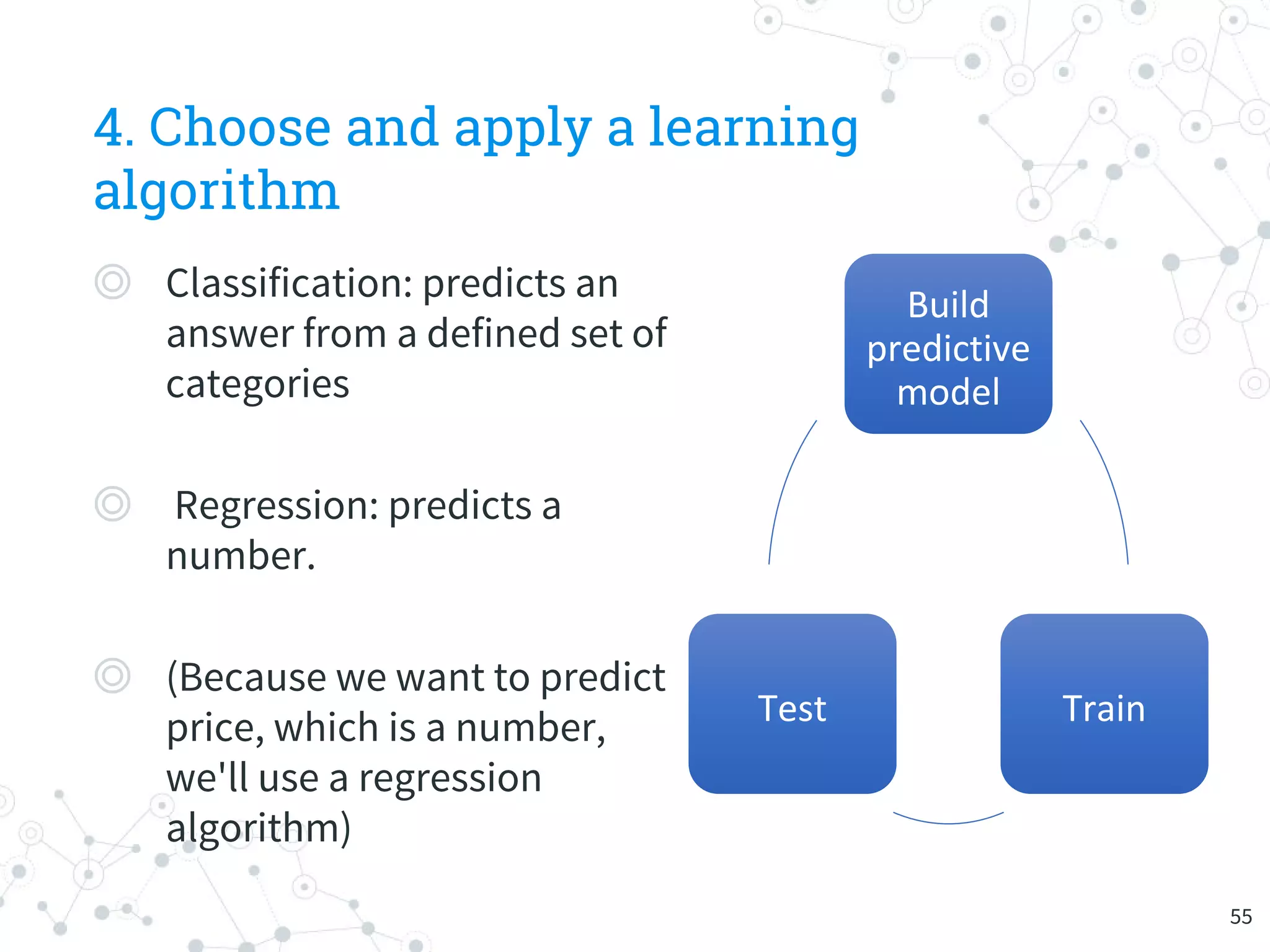
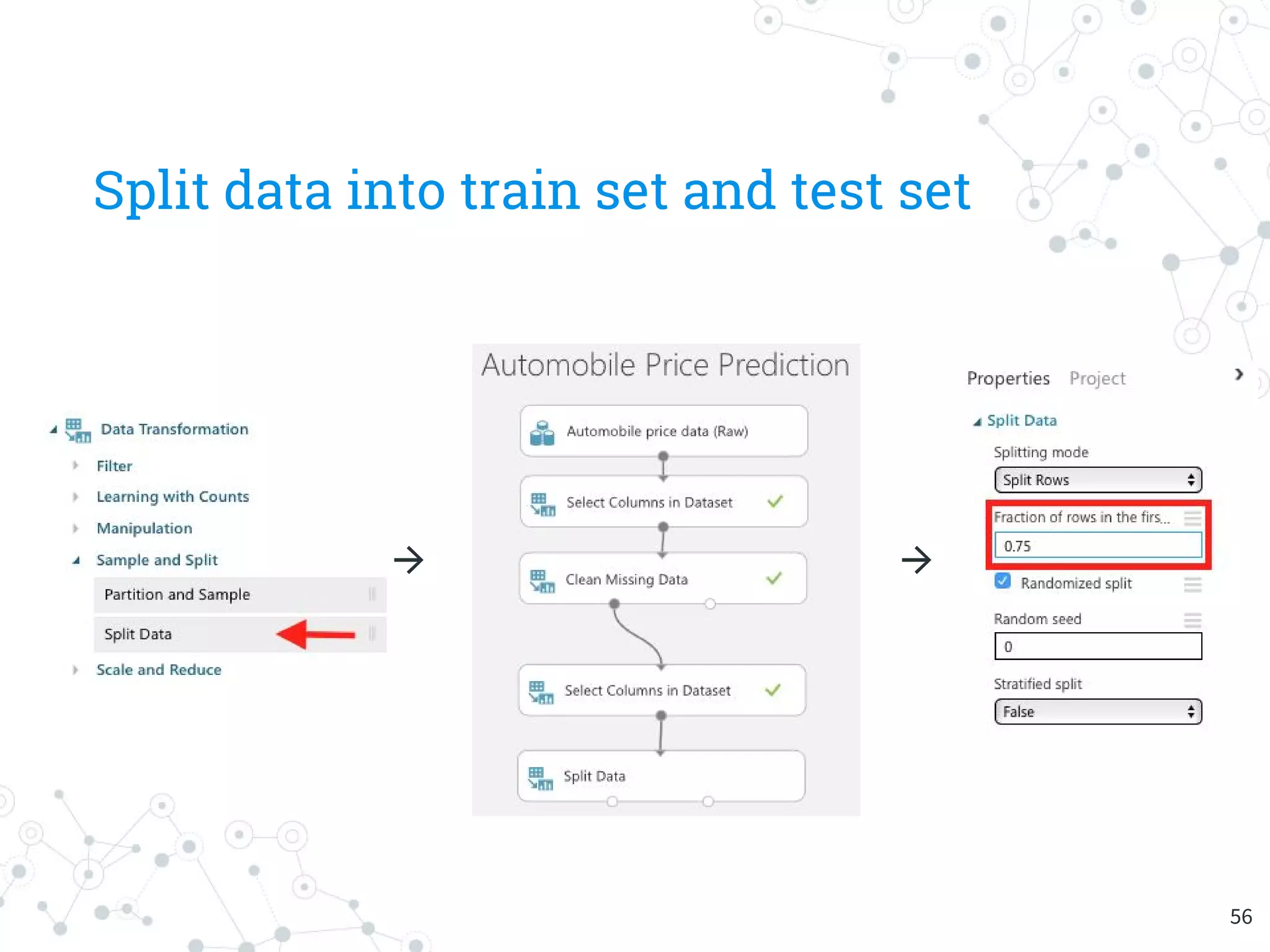
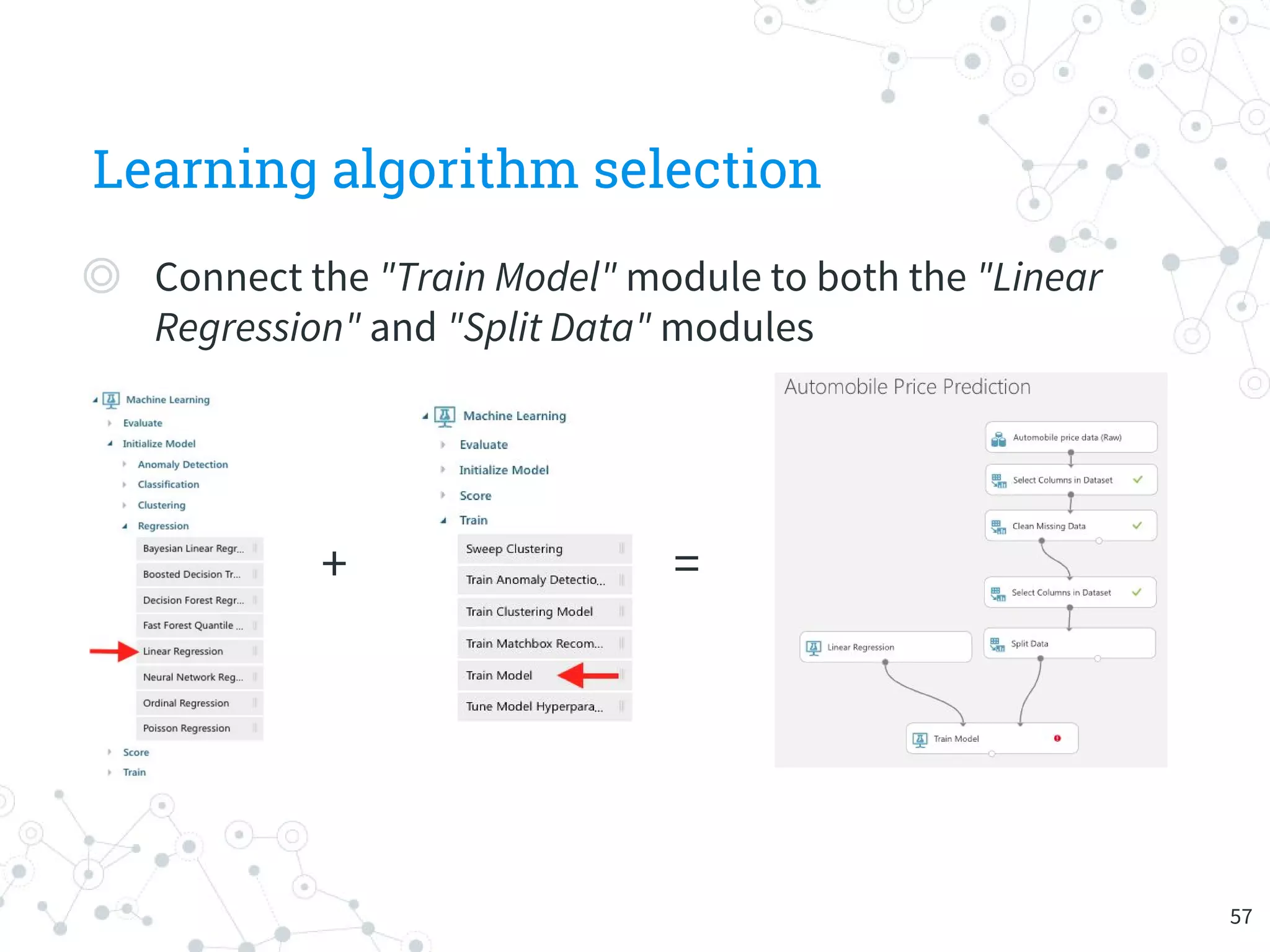
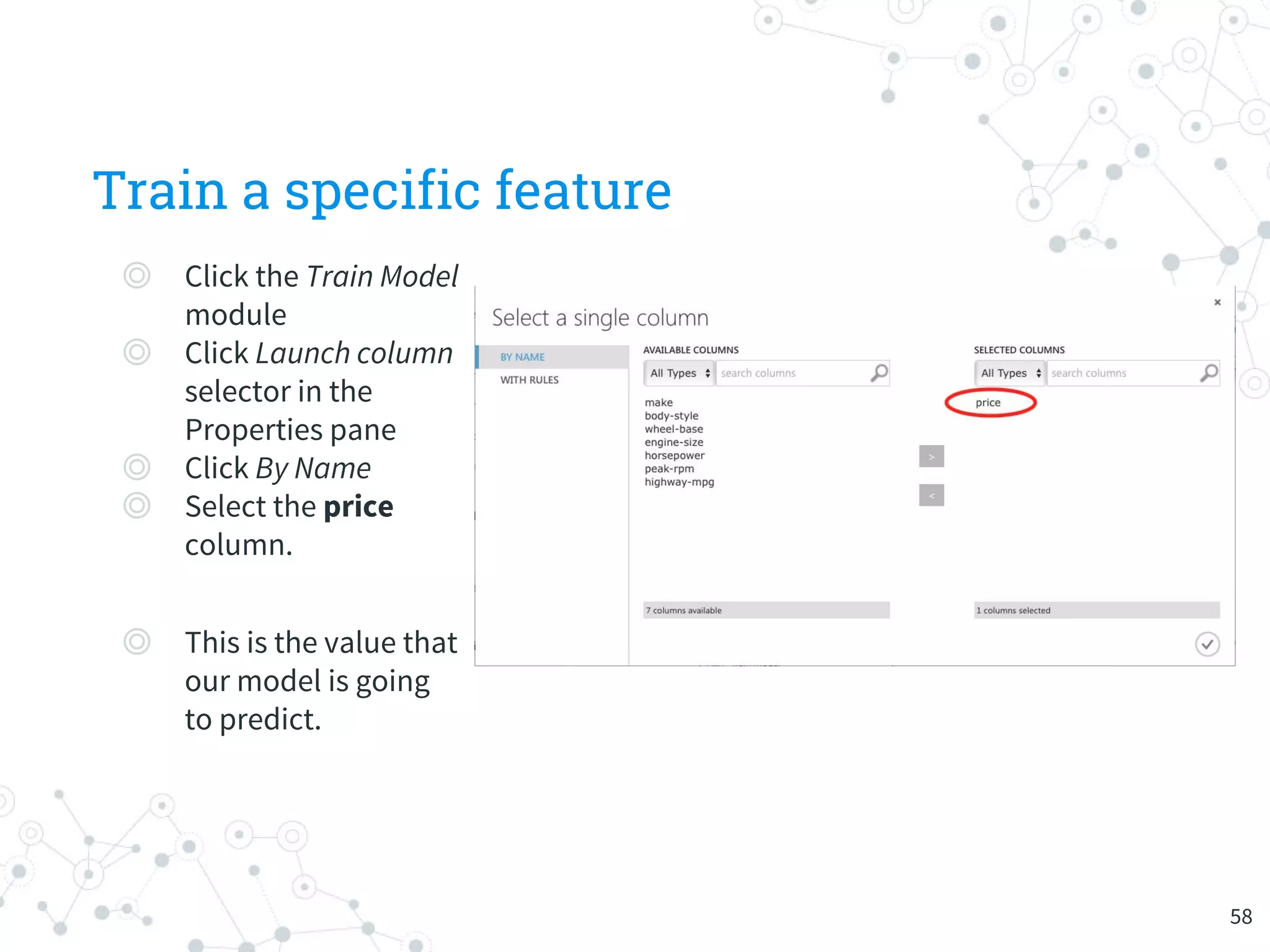
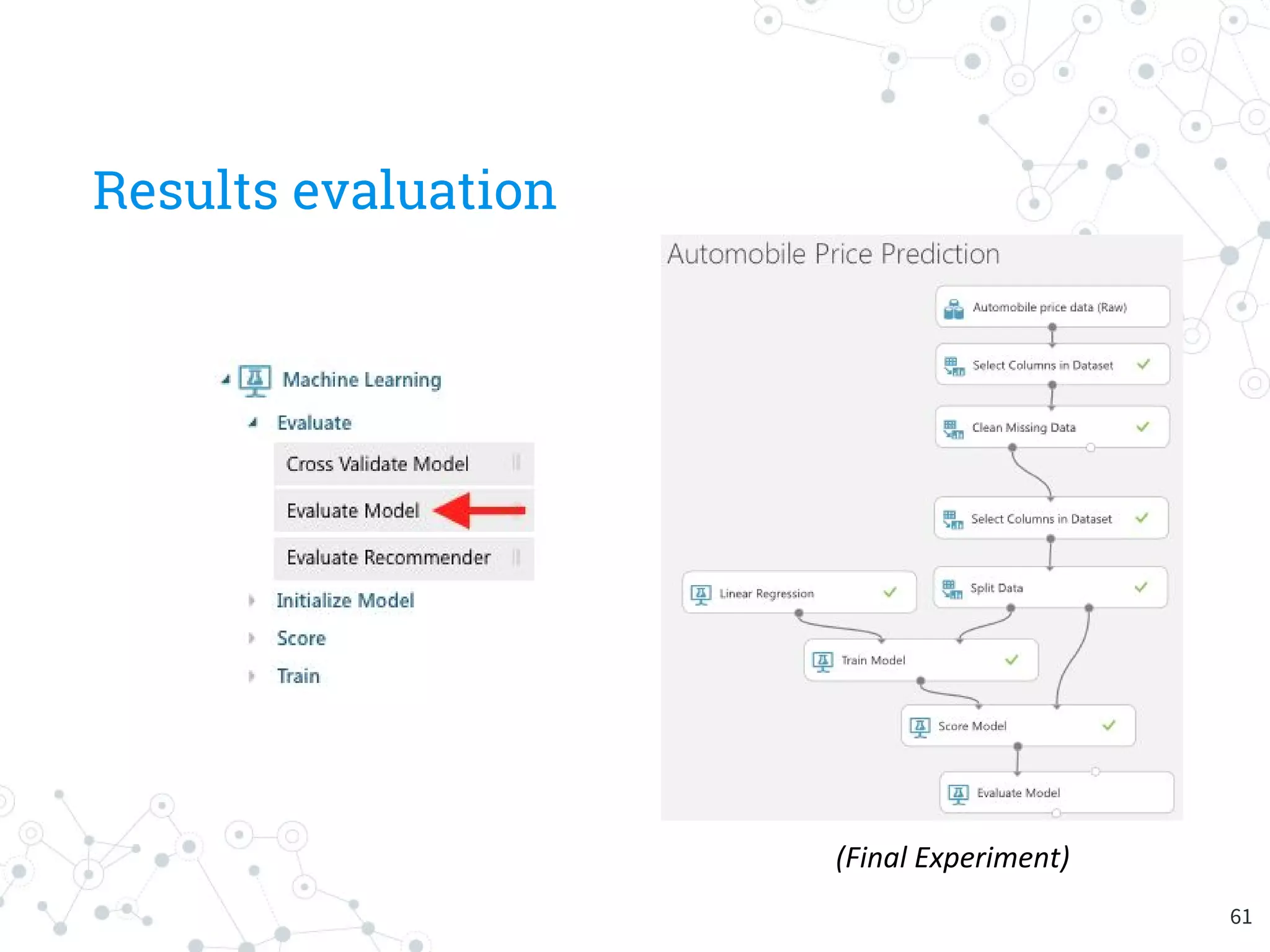
The document provides an overview of machine learning and its applications, focusing on Azure Machine Learning Studio as a tool for developing predictive models. It outlines the ease of use of Azure's platform for building and deploying experiments, along with the benefits of machine learning as a service. Additionally, it includes a hands-on tutorial on how to create and deploy a model for predicting automobile prices.