Downloaded 46 times





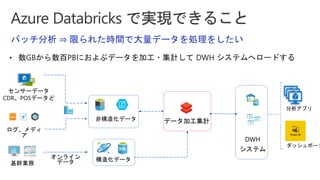
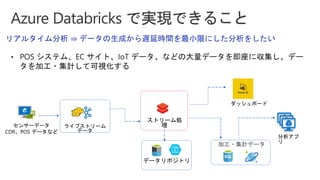
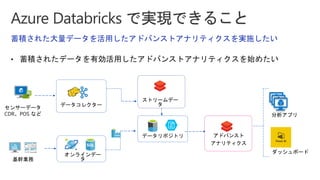

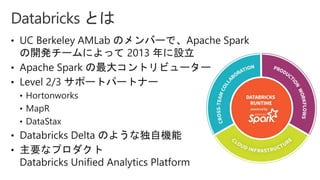
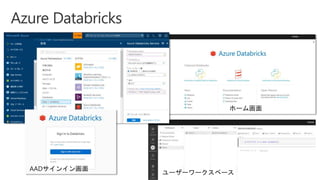
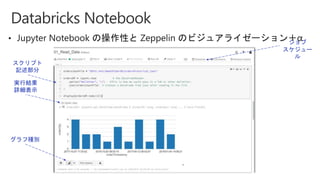
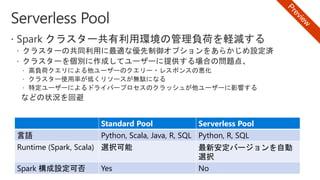



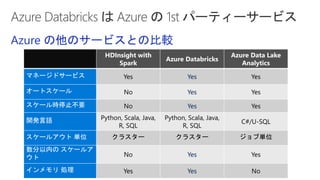

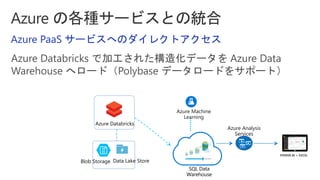
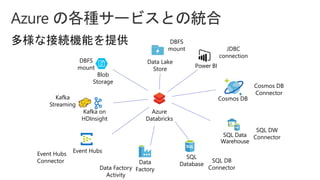
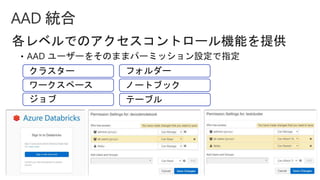

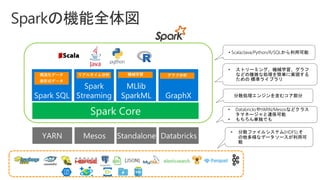


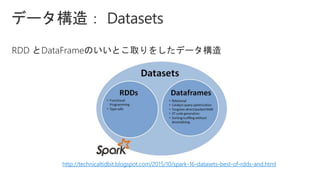

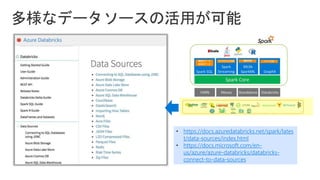






Slides for Azure Webinar: Azure Databricks for Application Developers (Webinar delivery date: June 7, 2018 ) Delivered by: Nobukatsu Tanahashi & Yoichi Kawasaki [ウェビナー] アプリケーション開発者のためのAzure Databricks入門 (2018年6月7日実施) 棚橋 信勝, Data & AI テクノロジースペシャリスト, マイクロソフトコーポレーション 川崎 庸市. Azureテクノロジースペシャリスト, マイクロソフトコーポレーション

![[AWS EXpert Online for JAWS-UG 18] 見せてやるよ、Step Functions の本気ってやつをな](https://cdn.slidesharecdn.com/ss_thumbnails/awsxon18howfarstepfunctionsgo-211124111849-thumbnail.jpg?width=640&height=640&fit=bounds)



























![[de:code 2019 振り返り Night!] Data Platform](https://cdn.slidesharecdn.com/ss_thumbnails/20190610decode2019dataplatformrecap-190610113039-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Microsoft Tech Summit 2018] Azure Machine Learning サービスと Azure Databricks で実...](https://cdn.slidesharecdn.com/ss_thumbnails/20181107techsummitazuremldatabricks-181108015121-thumbnail.jpg?width=640&height=640&fit=bounds)




































