T-SQL では、複数のクエリを一つのバッチとして実行できる為、無理してサブクエリ化したような
クエリは、ステップ分けした方が大幅に性能向上できる場合がある
(例: Exadata40分 / Synapse SQL 当初 60分超 ⇒ 3.5分)
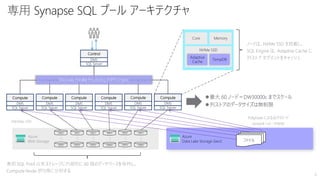
T-SQL のメリットを最大化する
29
--------------------------------------------------------------------------
-- Query-1 の結果が1件 ★インメモリ
--------------------------------------------------------------------------
--// 個別変数
DECLARE @DeviceId NCHAR(10)
DECLARE @Temperature INT
--// Query-1
SELECT TOP 1 @DeviceId = DeviceId, @Temperature = Temperature
FROM dbo.asalog ORDER BY Temperature DESC;
--// Query-2
SELECT a.*, @Temperature Temperature FROM dbo.asalog a
WHERE a.DeviceId = @DeviceId;
--------------------------------------------------------------------------
-- Query-1 の結果が小規模 (~数万件) ★インメモリ
--------------------------------------------------------------------------
--// テーブル変数
DECLARE @tableVal TABLE
(
DeviceId NCHAR(10),
Temperature INT
)
--// Query-1
INSERT INTO @tableVal
SELECT TOP 1000 * FROM dbo.asalog ORDER BY Temperature DESC;
--// Query-2
SELECT a.*, t.Temperature FROM dbo.asalog a
INNER JOIN @tableVal t ON a.DeviceId = t.DeviceId;
--------------------------------------------------------------------------
-- Query-1 の結果が中規模 (~数十万件) ★インメモリ
-- CTE (Common Table Expression) の利用
--------------------------------------------------------------------------
--// CTE (Common Table Expression)
WITH table_cte (DeviceId, Temperature)
AS
(
--// Query-1
SELECT TOP 100000 * FROM dbo.asalog ORDER BY Temperature DESC
)
--// Query-2
SELECT a.*, t.Temperature FROM dbo.asalog a
INNER JOIN table_cte t ON a.DeviceId = t.DeviceId;
--------------------------------------------------------------------------
-- Query-1 の結果が大規模 (数百万件以上) ★一時テーブル on tempDB
-- SQLDB BC/Hyperscale, Synapse SQL の場合、tempDB は NVMe SSD 上なので高速
--------------------------------------------------------------------------
--// 一時テーブル削除
IF OBJECT_ID(N'tempdb..#table1',N'U') IS NOT NULL
DROP TABLE #table1;
--// Query-1 to 一時テーブル
SELECT TOP 2000000 * INTO #table1 FROM dbo.asalog ORDER BY Temperature DESC;
--// Query-2
SELECT a.*, t.Temperature FROM dbo.asalog a
INNER JOIN #table1 t ON a.DeviceId = t.DeviceId;
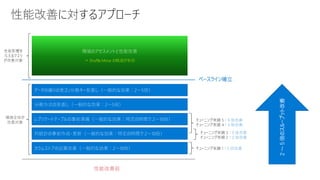
チェック対象:1 分集計とした以下のメトリクスをチェックし、定常的に負荷が高い場合、DWU 追加を検討
•CPU used percentage 最大値
• Memory used percentage 最大値
• Local tempDB used percentage 最大値 (ソート, データ移動, Polybase によるロード, 一時テーブルで利用)
• Adaptive cache hit percentage 平均値 (クエリ実行時に列ストアデータが NVMe SSD に載っている割合) ⇒ 80% 以上が目安
• Workload group active queries 合計
• Workload group queued queries 合計 ⇒ 定常的にキュー待ちが大量に起きていないか
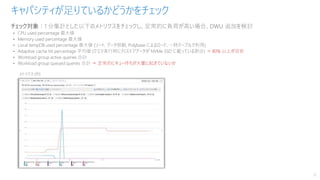
キャパシティが足りているかどうかをチェック
32
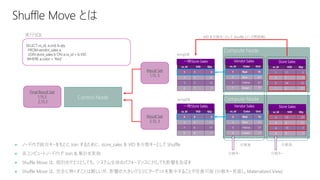
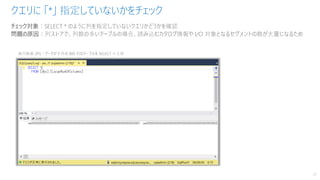
33.
チェック対象:以下クエリ実行時の [COMPRESSED_rowgroup_rows_XXX] 列の値は、104万行に近いほど品質が良い
問題の原因:データロード時のリソースクラス or ワークロード グループの REQUEST_MIN_RESOURCE_GRANT_PERCENT の値が小さ過ぎる
列ストア セグメントの品質を疑う
33
※参照:https://docs.microsoft.com/ja-jp/azure/synapse-analytics/sql-data-warehouse/sql-data-warehouse-tables-index#optimizing-clustered-columnstore-indexes
----------------------------------------------------------------------------------
-- CCI セグメント品質のチェック (簡易版)
----------------------------------------------------------------------------------
-- [table_partition_count] パーティション数
-- [row_count_total] トータル行数
-- [COMPRESSED_rowgroup_rows] 圧縮済み行グループのトータル行数
-- [COMPRESSED_rowgroup_rows_MIN] 圧縮済み行グループ内の最小行数
-- [COMPRESSED_rowgroup_rows_MAX] 圧縮済み行グループ内の最大行数
-- [COMPRESSED_rowgroup_rows_AVG] 圧縮済み行グループ内の平均行数
-- [COMPRESSED_rowgroup_rows_DELETED] 行グループ内の論理削除された行数
----------------------------------------------------------------------------------
SELECT
s.name AS [schema_name]
, t.name AS [table_name]
, COUNT(DISTINCT rg.[partition_number]) AS [table_partition_count]
, SUM(rg.[total_rows]) AS [row_count_total]
, SUM(CASE WHEN rg.[State] = 3 THEN rg.[total_rows] ELSE 0 END) AS [COMPRESSED_rowgroup_rows]
, AVG(CASE WHEN rg.[State] = 3 THEN rg.[total_rows] ELSE NULL END) AS [COMPRESSED_rowgroup_rows_AVG]
, MIN(CASE WHEN rg.[State] = 3 THEN rg.[total_rows] ELSE NULL END) AS [COMPRESSED_rowgroup_rows_MIN]
, MAX(CASE WHEN rg.[State] = 3 THEN rg.[total_rows] ELSE NULL END) AS [COMPRESSED_rowgroup_rows_MAX]
, SUM(CASE WHEN rg.[State] = 3 THEN rg.[deleted_rows] ELSE 0 END) AS [COMPRESSED_rowgroup_rows_DELETED]
, SUM(CASE WHEN rg.[State] = 1 THEN rg.[total_rows] ELSE 0 END) AS [OPEN_rowgroup_rows]
, AVG(CASE WHEN rg.[State] = 1 THEN rg.[total_rows] ELSE NULL END) AS [OPEN_rowgroup_rows_AVG]
, MIN(CASE WHEN rg.[State] = 1 THEN rg.[total_rows] ELSE NULL END) AS [OPEN_rowgroup_rows_MIN]
, MAX(CASE WHEN rg.[State] = 1 THEN rg.[total_rows] ELSE NULL END) AS [OPEN_rowgroup_rows_MAX]
, 'ALTER INDEX ALL ON ' + s.name + '.' + t.NAME + ' REBUILD;' AS [Rebuild_Index_SQL]
FROM sys.[pdw_nodes_column_store_row_groups] rg
JOIN sys.[pdw_nodes_tables] nt ON rg.[object_id] = nt.[object_id]
AND rg.[pdw_node_id] = nt.[pdw_node_id]
AND rg.[distribution_id] = nt.[distribution_id]
JOIN sys.[pdw_table_mappings] mp ON nt.[name] = mp.[physical_name]
JOIN sys.[tables] t ON mp.[object_id] = t.[object_id]
JOIN sys.[schemas] s ON t.[schema_id] = s.[schema_id]
--WHERE s.name = @schemaName AND t.name = @tableName
GROUP BY s.[name], t.[name]
ORDER BY s.[name], t.[name]
34.
チェック対象:以下クエリ実行時の [distribution_id] 列毎の[row_count] 列の値を見て、片寄りが無いかを確認
問題の原因:分散キーに設定した列が適切で無い (=カージナリティが低い or 値に片寄りがある) 可能性が高い
ディストリビューションのデータの偏りを疑う
34
※参照:https://docs.microsoft.com/ja-jp/azure/synapse-analytics/sql-data-warehouse/sql-data-warehouse-tables-distribute#determine-if-the-table-has-data-skew
★dbo.vTableSizes ビューは、参照先のリンクに定義がある
----------------------------------------------------------------------------------
-- 特定のノード/ディストリビューションにデータの偏りがないかのチェック
----------------------------------------------------------------------------------
-- 特定のテーブルについてノードにデータの片寄りが無いか
DBCC PDW_SHOWSPACEUSED('schema_name.table_name');
-- ディストリビューションの 10% 以上の偏りを抽出
select
two_part_name
, pdw_node_id
, pdw_node_type
, distribution_id
, dist_name,partition_nmbr
, row_count
, distribution_column
, distribution_policy_name
, index_type_desc
from dbo.vTableSizes -- ★★ このビューは、参照先のリンクにスクリプトがある
where two_part_name in
(
select two_part_name
from dbo.vTableSizes
where row_count > 0
group by two_part_name
having (max(row_count * 1.000) - min(row_count * 1.000))/max(row_count * 1.000) >= .10
)
order by two_part_name, distribution_id, row_count
;
35.
チェック対象:以下クエリ実行時の [operation_type] 列毎の[total_elapsed_time], [row_count] の値を見て、時間・件数が大きくないか確認
問題の原因:
• BroadcastMoveOperation (全データを全ノードへ移動) :レプリケート テーブル適用について検討が必要
• ShuffleMoveOperation (ジョインに必要なデータの移動):ノード内でジョインが完結していない ⇒ 結合キー (列) を分散キーに出来ないか検討が必要
コンピュート ノード間でデータ移動が大量に発生していないか疑う
35
※参照:https://docs.microsoft.com/ja-jp/sql/relational-databases/system-dynamic-management-views/sys-dm-pdw-request-steps-transact-sql?toc=/azure/synapse-analytics/sql-data-
warehouse/toc.json&bc=/azure/synapse-analytics/sql-data-warehouse/breadcrumb/toc.json&view=azure-sqldw-latest
--------------------------------------------
-- コンピュートノード間でのデータ移動を確認
--------------------------------------------
-- 完了した対象のクエリの QID を確認
SELECT *
FROM sys.dm_pdw_exec_requests
WHERE status in ('Completed','Failed','Cancelled')
AND session_id <> session_id()
ORDER BY submit_time DESC;
-- 分散実行プランでデータ移動が大量に発生していないか確認
-- (BroadcastMoveOperation, ShuffleMoveOperation が対象)
DECLARE @qid VARCHAR(20) = ’QIDxxxxxx’;
SELECT * FROM sys.dm_pdw_request_steps
WHERE request_id = @qid
ORDER BY step_index;








![Fact / Transaction 系のテーブルは、分散キーを設定し、ハッシュ分散させること
ファクト系テーブルは、ハッシュ分散させる
11
注意点
• デフォルト (分散キー未指定) だと、ラウンドロビンが選択されてしまう ⇒ データ移動が発生し易い
• 分散キーには、カージナリティの高い (バリエーションが多い) 列を選択すること ⇒ カージナリティが低いと、データの偏りが起き易い
• ジョインに良く利用される列を選択すること ⇒ データ移動の発生頻度が低くなる
CREATE TABLE [schema].[table_name]
(
~列定義~
)
WITH
(
CLUSTERED COLUMNSTORE INDEX
, DISTRIBUTION = HASH([distiribution_key_column_name])
)
※参照:https://docs.microsoft.com/ja-jp/azure/synapse-analytics/sql-data-warehouse/sql-data-warehouse-tables-distribute](https://image.slidesharecdn.com/20220423jssugosamuhir-220423094727/85/Azure-Synapse-Analytics-SQL-Pool-11-320.jpg)
![Fact / Transaction 系のテーブルはハッシュ分散を選択するのが基本だが、適切なハッシュキーが
見つからず、結果として、データの偏りが大きい場合は、ラウンドロビンで分散させる
適切なハッシュキーが見つからなければ、ラウンドロビンで分散
12
CREATE TABLE [schema].[table_name]
(
~列定義~
)
WITH
(
CLUSTERED COLUMNSTORE INDEX
, DISTRIBUTION = ROUND_ROBIN
)
※参照:https://docs.microsoft.com/ja-jp/sql/t-sql/statements/create-table-azure-sql-data-warehouse?toc=%2Fazure%2Fsynapse-analytics%2Fsql-data-
warehouse%2Ftoc.json&bc=%2Fazure%2Fsynapse-analytics%2Fsql-data-warehouse%2Fbreadcrumb%2Ftoc.json&view=azure-sqldw-latest](https://image.slidesharecdn.com/20220423jssugosamuhir-220423094727/85/Azure-Synapse-Analytics-SQL-Pool-12-320.jpg)
![物理サイズが 2 GB 程度を目安に、マスター系テーブルは、レプリケート テーブルにする
マスター系テーブルは、レプリケート テーブルを考慮する
13
注意点
• レプリケート テーブルは、各ノードにコピーされるが、更新が発生するとコピーは無効になる ⇒ 更新頻度の高いテーブルは不向き
• 各ノードのコピーが無効化されるのは、以下の条件となる
✓ データがロードされる、または、変更される
✓ Synapse SQL インスタンスが別のレベルにスケーリングされる
✓ テーブル定義が更新される
CREATE TABLE [schema].[table_name]
(
~列定義~
)
WITH
(
CLUSTERED COLUMNSTORE INDEX
, DISTRIBUTION = REPLICATE
)
※参照:https://docs.microsoft.com/ja-jp/azure/synapse-analytics/sql-data-warehouse/design-guidance-for-replicated-tables](https://image.slidesharecdn.com/20220423jssugosamuhir-220423094727/85/Azure-Synapse-Analytics-SQL-Pool-13-320.jpg)
![パーティションは、日付での効率的なロードや削除などの運用目的で設定し、パーティションのサイズ
が小さくなり過ぎないように注意する (例えば、2,000 万行は小さい)
細か過ぎるパーティションは設定しない
14
注意点
• 列ストア セグメントは、MIN/MAX 値をカタログに保持している為、I/O 効率が高い ⇒ I/O 効率目的だけでパーティションは設定しない
• パーティションを設定すると、パーティション数 × ディストリビューション (60) にテーブルが分割される為、列ストア セグメントの品質を落とす 可
能性が高くなる ⇒ 列ストア セグメントの品質 (I/O 効率) が最も良いのは 104 万行に近い値
CREATE TABLE [schema].[table_name]
(
~列定義~
)
WITH
(
CLUSTERED COLUMNSTORE INDEX
, DISTRIBUTION = HASH([distiribution_key_column_name])
, PARTITION([partition_column_name] RANGE RIGHT FOR VALUES
(20000101,20010101,20020101 ,20030101,20040101,20050101))
)
※参照:https://docs.microsoft.com/ja-jp/azure/synapse-analytics/sql-data-warehouse/sql-data-warehouse-tables-partition?toc=/azure/synapse-
analytics/toc.json&bc=/azure/synapse-analytics/breadcrumb/toc.json](https://image.slidesharecdn.com/20220423jssugosamuhir-220423094727/85/Azure-Synapse-Analytics-SQL-Pool-14-320.jpg)
![条件句でよく利用される並び順が重要な列に順序指定 列ストア インデックスを適用して、
IO 効率を上げる
順序指定 列ストア インデックスを活用する
15
注意点
• 列ストア セグメントは、MIN/MAX 値をカタログに保持している為、I/O 効率が高い ⇒ Ordered CCI はこの特性に大きく寄与する
• 参照性能が速くなる一方、ロード性能との間でトレードオフが発生する為、性能検証を行い、バランスを考慮すること
CREATE TABLE [schema].[table_name]
(
~列定義~
)
WITH
(
CLUSTERED COLUMNSTORE INDEX ORDER ([order_column_name1],…)
, DISTRIBUTION = HASH([distiribution_key_column_name])
)
※参照: https://docs.microsoft.com/ja-jp/azure/synapse-analytics/sql-data-warehouse/performance-tuning-ordered-cci](https://image.slidesharecdn.com/20220423jssugosamuhir-220423094727/85/Azure-Synapse-Analytics-SQL-Pool-15-320.jpg)



![最終系のテーブルではなく、中間的なテーブルとしてロードする場合、列ストアではなく、一
時ヒープテーブル (行ストア) としてロードすることで、プロセス全体を高速化できる
ステージング テーブルは、一時ヒープテーブルにロードする
19
注意点
• 一時テーブルは、NVMe SSD 上の TempDB に格納される ⇒ 高速だが、利用し過ぎると、ソート処理などに支障が出る
• 一時テーブルは、同一セッション内でのみ有効 ⇒ T-SQL バッチなどで一連の処理を実行
CREATE TABLE #temp_table_name
WITH
(
HEAP
, DISTRIBUTION = HASH([distiribution_key_column_name])
)
AS
SELECT *
FROM [schema].[external_table_name]](https://image.slidesharecdn.com/20220423jssugosamuhir-220423094727/85/Azure-Synapse-Analytics-SQL-Pool-19-320.jpg)


![結果セット キャッシュにヒットすると、コントロールノードですぐに結果が返却される為、リソース利用率
を削減し、レスポンスを向上させることができる
結果セット キャッシュ (Result set caching) を有効化する
22
注意点
• 参照先のテーブルが更新されると、キャッシュは無効になる ⇒ 更新が頻繁な環境には向かない
• 結果セット キャッシュのサイズは、データベース全体で 1 TB
• キャッシュされない場合
✓ DateTime.Now() などの非決定論的関数を使用するクエリ
✓ ユーザー定義関数を使用したクエリ
✓ 行レベルのセキュリティまたは列レベルのセキュリティが有効になっているテーブルを使用したクエリ
✓ 64 KB を超える行サイズのデータを返すクエリ 10 GB を超えるサイズの大きなデータを返すクエリ
※参照:https://docs.microsoft.com/ja-jp/azure/synapse-analytics/sql-data-warehouse/performance-tuning-result-set-caching
-- データベースで有効化
ALTER DATABASE [database_name]
SET RESULT_SET_CACHING ON;
-- セッション単位で無効化
SET RESULT_SET_CACHING OFF](https://image.slidesharecdn.com/20220423jssugosamuhir-220423094727/85/Azure-Synapse-Analytics-SQL-Pool-22-320.jpg)
![SELECT TOP 1 * or COUNT_BIG(*) を使い、レプリケート テーブルを事前に各ノードにコピーしておく
レプリケート テーブルは事前に Ready にしておく
23
注意点
• 各ノードのコピーが無効化 されるのは、以下の条件となる
✓ データがロードされる、または、変更される
✓ Synapse SQL インスタンスが別のレベルにスケーリングされる
✓ テーブル定義が更新される
• レプリケート テーブルは、最初の参照時に各ノードの保持する 1 つ目のディストリビューションにコピーされる ⇒ 性能影響が大きい
※参照:https://docs.microsoft.com/ja-jp/azure/synapse-analytics/sql-data-warehouse/design-guidance-for-replicated-tables
-- レプリケート テーブルの状態
SELECT [ReplicatedTable] = t.[name]
FROM sys.tables t
JOIN sys.pdw_replicated_table_cache_state c ON c.object_id = t.object_id
JOIN sys.pdw_table_distribution_properties p ON p.object_id = t.object_id
WHERE c.[state] = 'NotReady' AND p.[distribution_policy_desc] = 'REPLICATE'
-- レプリケートのコピー(以下のどちらかを利用)
SELECT TOP 1 * FROM [schema].[table_name];
SELECT COUNT_BIG(*) FROM [schema].[table_name];](https://image.slidesharecdn.com/20220423jssugosamuhir-220423094727/85/Azure-Synapse-Analytics-SQL-Pool-23-320.jpg)
![列統計は自動作成には任せず、ロードジョブの必須ステップとして事前に作成しておく
列統計は事前に作成しておく
24
注意点
• 列統計は最初のクエリ実行時に自動作成される ⇒ 性能影響が大きい
• 列統計の自動作成では、クエリの WHERE 句内の列 と 結合キーの列が対象となる
• 列統計の自動作成時は、サンプリング (10 億行未満:20% / 10 億行以上:2%)
• 20% のサンプリングで十分な場合も多いが、大きな値や WITH FULLSCAN 指定の方が精度は上がる
※参照:https://docs.microsoft.com/ja-jp/azure/synapse-analytics/sql-data-warehouse/sql-data-warehouse-tables-statistics#examples-create-statistics
-- 単一列統計の作成
CREATE STATISTICS [statistics_name] ON [schema].[table_name]([column_name]) WITH
20 PERCENT;](https://image.slidesharecdn.com/20220423jssugosamuhir-220423094727/85/Azure-Synapse-Analytics-SQL-Pool-24-320.jpg)
![差分更新 (非洗い替え) テーブルの列統計は、ロード処理後に更新する
差分更新テーブルの列統計を更新する
25
注意点
• 列統計は最初のクエリ実行時に自動作成される ⇒ 性能影響が大きい
• 列統計の自動作成では、クエリの WHERE 句内の列 と 結合キーの列が対象となる
• 列統計の自動更新は、既定では無効
-------------------------------------------------------------------------------
-- 更新対象の把握と、統計詳細取得コマンド&統計更新コマンドの自動生成
-------------------------------------------------------------------------------
SELECT
sm.[name] AS [schema_name],
tb.[name] AS [table_name],
co.[name] AS [stats_column_name],
st.[name] AS [stats_name],
STATS_DATE(st.[object_id],st.[stats_id]) AS [stats_last_updated_date],
'DBCC SHOW_STATISTICS(''[' + sm.[name] + '].[' + tb.[name] + ']'',''' + st.[name] + ''')' SHOW_STATS_COMMAND,
'UPDATE STATISTICS [' + sm.[name] + '].[' + tb.[name] + ']([' + st.[name] + ']) WITH SAMPLE 20 PERCENT' UPDATE_COMMAND
FROM
sys.objects ob
JOIN sys.stats st ON ob.[object_id] = st.[object_id]
JOIN sys.stats_columns sc ON st.[stats_id] = sc.[stats_id]
AND st.[object_id] = sc.[object_id]
JOIN sys.columns co ON sc.[column_id] = co.[column_id]
AND sc.[object_id] = co.[object_id]
JOIN sys.types ty ON co.[user_type_id] = ty.[user_type_id]
JOIN sys.tables tb ON co.[object_id] = tb.[object_id]
JOIN sys.schemas sm ON tb.[schema_id] = sm.[schema_id]
WHERE st.[object_id] = OBJECT_ID('nct.T100_packet_tcp') --★テーブル名を指定
AND STATS_DATE(st.[object_id],st.[stats_id]) IS NOT NULL
※参照:https://docs.microsoft.com/ja-jp/azure/synapse-analytics/sql-data-warehouse/sql-data-warehouse-tables-statistics#examples-update-statistics
※参照:https://docs.microsoft.com/ja-jp/sql/relational-databases/statistics/view-statistics-properties?view=sql-server-ver15](https://image.slidesharecdn.com/20220423jssugosamuhir-220423094727/85/Azure-Synapse-Analytics-SQL-Pool-25-320.jpg)






![チェック対象:以下クエリ実行時の [COMPRESSED_rowgroup_rows_XXX] 列の値は、104 万行に近いほど品質が良い
問題の原因:データロード時のリソースクラス or ワークロード グループの REQUEST_MIN_RESOURCE_GRANT_PERCENT の値が小さ過ぎる
列ストア セグメントの品質を疑う
33
※参照:https://docs.microsoft.com/ja-jp/azure/synapse-analytics/sql-data-warehouse/sql-data-warehouse-tables-index#optimizing-clustered-columnstore-indexes
----------------------------------------------------------------------------------
-- CCI セグメント品質のチェック (簡易版)
----------------------------------------------------------------------------------
-- [table_partition_count] パーティション数
-- [row_count_total] トータル行数
-- [COMPRESSED_rowgroup_rows] 圧縮済み行グループのトータル行数
-- [COMPRESSED_rowgroup_rows_MIN] 圧縮済み行グループ内の最小行数
-- [COMPRESSED_rowgroup_rows_MAX] 圧縮済み行グループ内の最大行数
-- [COMPRESSED_rowgroup_rows_AVG] 圧縮済み行グループ内の平均行数
-- [COMPRESSED_rowgroup_rows_DELETED] 行グループ内の論理削除された行数
----------------------------------------------------------------------------------
SELECT
s.name AS [schema_name]
, t.name AS [table_name]
, COUNT(DISTINCT rg.[partition_number]) AS [table_partition_count]
, SUM(rg.[total_rows]) AS [row_count_total]
, SUM(CASE WHEN rg.[State] = 3 THEN rg.[total_rows] ELSE 0 END) AS [COMPRESSED_rowgroup_rows]
, AVG(CASE WHEN rg.[State] = 3 THEN rg.[total_rows] ELSE NULL END) AS [COMPRESSED_rowgroup_rows_AVG]
, MIN(CASE WHEN rg.[State] = 3 THEN rg.[total_rows] ELSE NULL END) AS [COMPRESSED_rowgroup_rows_MIN]
, MAX(CASE WHEN rg.[State] = 3 THEN rg.[total_rows] ELSE NULL END) AS [COMPRESSED_rowgroup_rows_MAX]
, SUM(CASE WHEN rg.[State] = 3 THEN rg.[deleted_rows] ELSE 0 END) AS [COMPRESSED_rowgroup_rows_DELETED]
, SUM(CASE WHEN rg.[State] = 1 THEN rg.[total_rows] ELSE 0 END) AS [OPEN_rowgroup_rows]
, AVG(CASE WHEN rg.[State] = 1 THEN rg.[total_rows] ELSE NULL END) AS [OPEN_rowgroup_rows_AVG]
, MIN(CASE WHEN rg.[State] = 1 THEN rg.[total_rows] ELSE NULL END) AS [OPEN_rowgroup_rows_MIN]
, MAX(CASE WHEN rg.[State] = 1 THEN rg.[total_rows] ELSE NULL END) AS [OPEN_rowgroup_rows_MAX]
, 'ALTER INDEX ALL ON ' + s.name + '.' + t.NAME + ' REBUILD;' AS [Rebuild_Index_SQL]
FROM sys.[pdw_nodes_column_store_row_groups] rg
JOIN sys.[pdw_nodes_tables] nt ON rg.[object_id] = nt.[object_id]
AND rg.[pdw_node_id] = nt.[pdw_node_id]
AND rg.[distribution_id] = nt.[distribution_id]
JOIN sys.[pdw_table_mappings] mp ON nt.[name] = mp.[physical_name]
JOIN sys.[tables] t ON mp.[object_id] = t.[object_id]
JOIN sys.[schemas] s ON t.[schema_id] = s.[schema_id]
--WHERE s.name = @schemaName AND t.name = @tableName
GROUP BY s.[name], t.[name]
ORDER BY s.[name], t.[name]](https://image.slidesharecdn.com/20220423jssugosamuhir-220423094727/85/Azure-Synapse-Analytics-SQL-Pool-33-320.jpg)
![チェック対象:以下クエリ実行時の [distribution_id] 列毎の [row_count] 列の値を見て、片寄りが無いかを確認
問題の原因:分散キーに設定した列が適切で無い (=カージナリティが低い or 値に片寄りがある) 可能性が高い
ディストリビューションのデータの偏りを疑う
34
※参照:https://docs.microsoft.com/ja-jp/azure/synapse-analytics/sql-data-warehouse/sql-data-warehouse-tables-distribute#determine-if-the-table-has-data-skew
★dbo.vTableSizes ビューは、参照先のリンクに定義がある
----------------------------------------------------------------------------------
-- 特定のノード/ディストリビューションにデータの偏りがないかのチェック
----------------------------------------------------------------------------------
-- 特定のテーブルについてノードにデータの片寄りが無いか
DBCC PDW_SHOWSPACEUSED('schema_name.table_name');
-- ディストリビューションの 10% 以上の偏りを抽出
select
two_part_name
, pdw_node_id
, pdw_node_type
, distribution_id
, dist_name,partition_nmbr
, row_count
, distribution_column
, distribution_policy_name
, index_type_desc
from dbo.vTableSizes -- ★★ このビューは、参照先のリンクにスクリプトがある
where two_part_name in
(
select two_part_name
from dbo.vTableSizes
where row_count > 0
group by two_part_name
having (max(row_count * 1.000) - min(row_count * 1.000))/max(row_count * 1.000) >= .10
)
order by two_part_name, distribution_id, row_count
;](https://image.slidesharecdn.com/20220423jssugosamuhir-220423094727/85/Azure-Synapse-Analytics-SQL-Pool-34-320.jpg)
![チェック対象:以下クエリ実行時の [operation_type] 列毎の [total_elapsed_time], [row_count] の値を見て、時間・件数が大きくないか確認
問題の原因:
• BroadcastMoveOperation (全データを全ノードへ移動) :レプリケート テーブル適用について検討が必要
• ShuffleMoveOperation (ジョインに必要なデータの移動):ノード内でジョインが完結していない ⇒ 結合キー (列) を分散キーに出来ないか検討が必要
コンピュート ノード間でデータ移動が大量に発生していないか疑う
35
※参照:https://docs.microsoft.com/ja-jp/sql/relational-databases/system-dynamic-management-views/sys-dm-pdw-request-steps-transact-sql?toc=/azure/synapse-analytics/sql-data-
warehouse/toc.json&bc=/azure/synapse-analytics/sql-data-warehouse/breadcrumb/toc.json&view=azure-sqldw-latest
--------------------------------------------
-- コンピュートノード間でのデータ移動を確認
--------------------------------------------
-- 完了した対象のクエリの QID を確認
SELECT *
FROM sys.dm_pdw_exec_requests
WHERE status in ('Completed','Failed','Cancelled')
AND session_id <> session_id()
ORDER BY submit_time DESC;
-- 分散実行プランでデータ移動が大量に発生していないか確認
-- (BroadcastMoveOperation, ShuffleMoveOperation が対象)
DECLARE @qid VARCHAR(20) = ’QIDxxxxxx’;
SELECT * FROM sys.dm_pdw_request_steps
WHERE request_id = @qid
ORDER BY step_index;](https://image.slidesharecdn.com/20220423jssugosamuhir-220423094727/85/Azure-Synapse-Analytics-SQL-Pool-35-320.jpg)




























![【ウェブ セミナー】AI 時代のクラウド データ ウェアハウス Azure SQL Data Warehouse [実践編]](https://cdn.slidesharecdn.com/ss_thumbnails/webinarsqldw20170726-180220004900-thumbnail.jpg?width=640&height=640&fit=bounds)













![[ウェビナー] Build 2018 アップデート ~ データ プラットフォーム/IoT編 ~](https://cdn.slidesharecdn.com/ss_thumbnails/20180614azuredataiotwebinar-180614083401-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Japan Tech summit 2017] DAL 003](https://cdn.slidesharecdn.com/ss_thumbnails/techsummit2017pdfdal003-171115033147-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DI12] あらゆるデータをビジネスに活用! Azure Data Lake を中心としたビックデータ処理基盤のアーキテクチャと実装](https://cdn.slidesharecdn.com/ss_thumbnails/di12-170616053736-thumbnail.jpg?width=640&height=640&fit=bounds)


![M20_Azure SQL Database 最新アップデートをまとめてキャッチアップ [Microsoft Japan Digital Days]](https://cdn.slidesharecdn.com/ss_thumbnails/m20azuresqldatabase-211027133338-thumbnail.jpg?width=640&height=640&fit=bounds)













