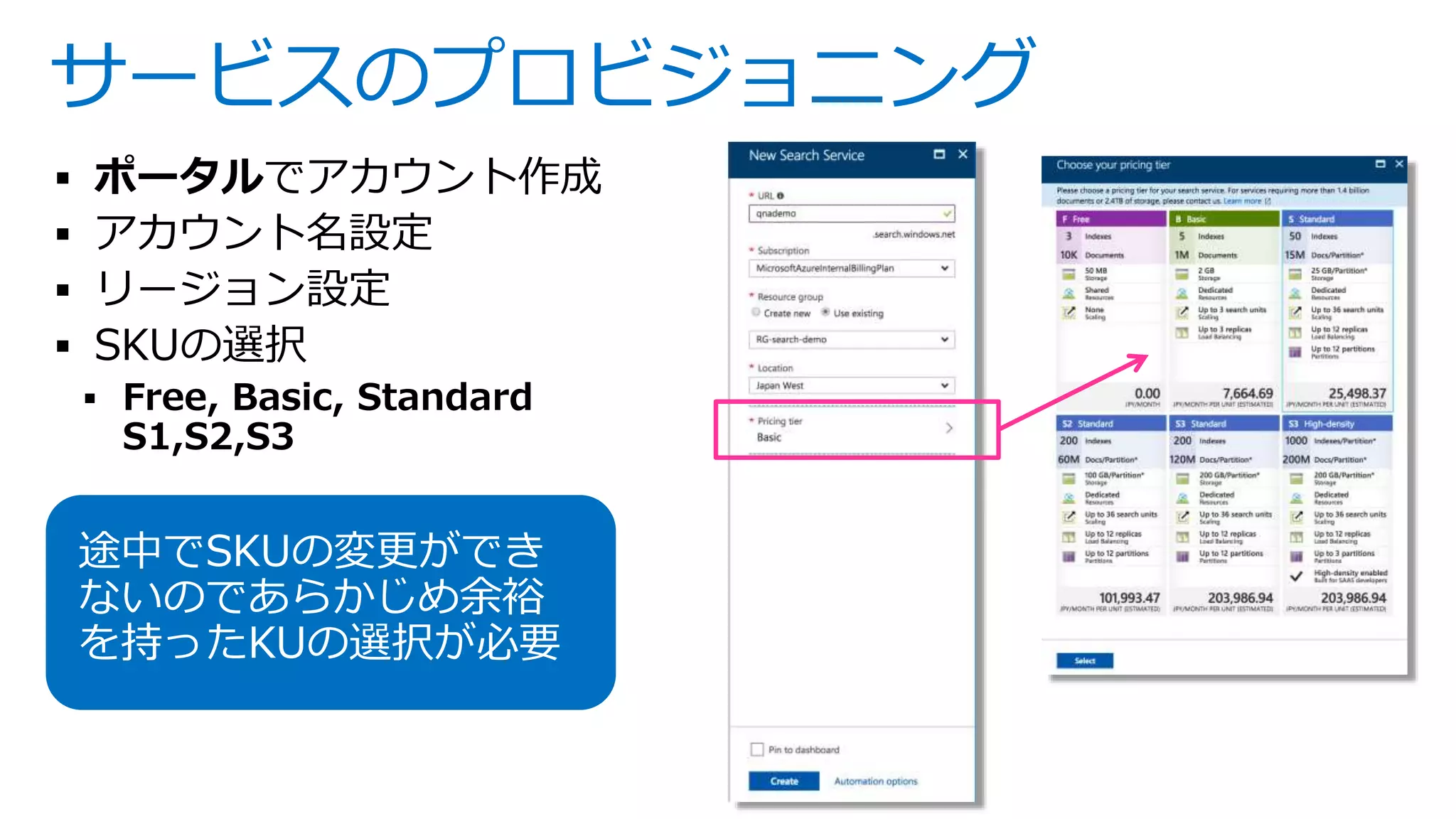
Downloaded 36 times



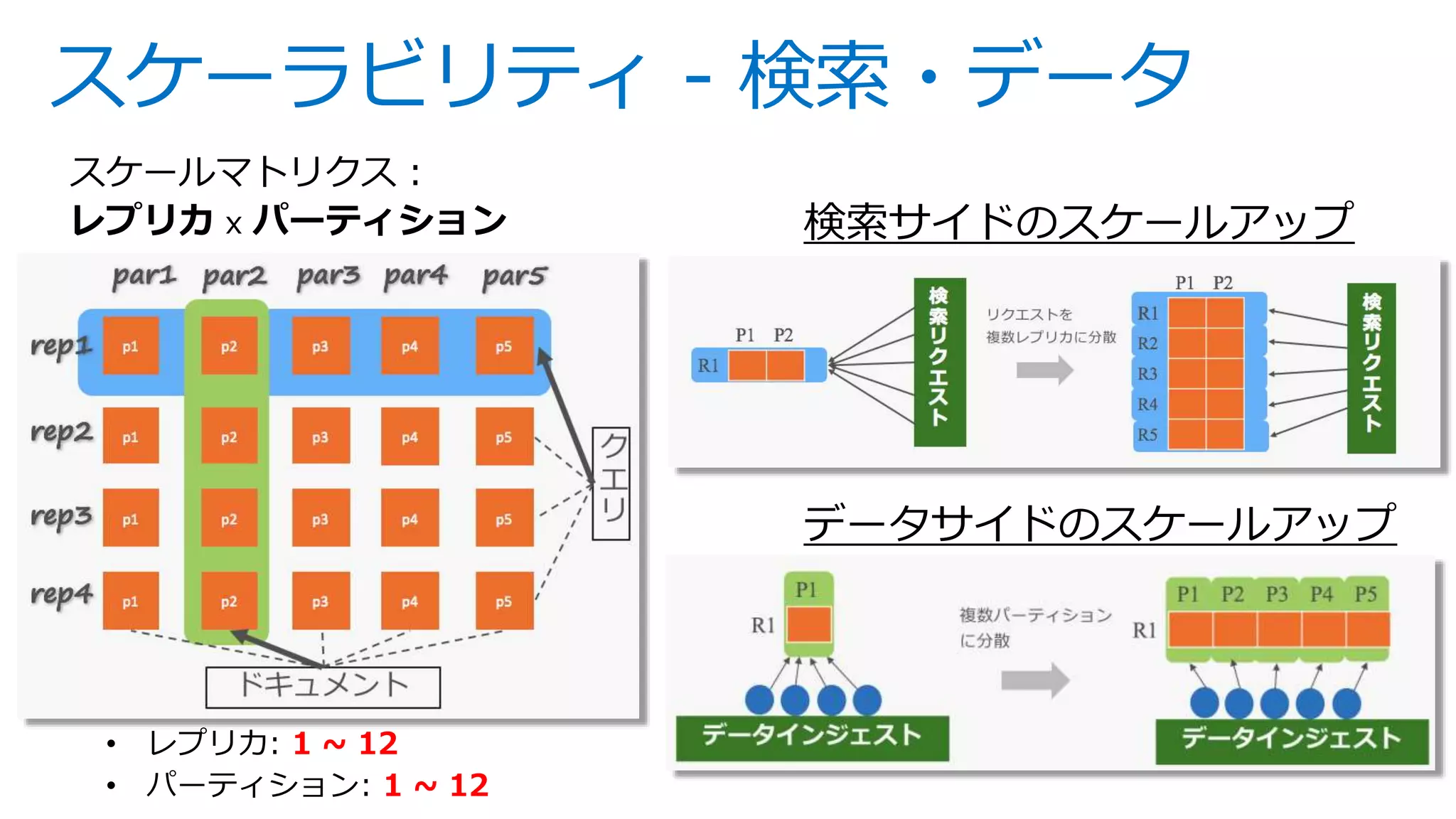
![シンプルなAPIとフォーマット
インデックス追加・更新 /indexes/<indexname> PUT
インデックス一覧表示 /indexes GET
インデックス統計情報取
得
/indexes/<indexname>/stats GET
インデックスの削除 /indexes/<indexname> DELETE
ドキュメント追加・削除 /indexes/<indexname>/docs/index POST
検索 /indexes/<indexname>/docs GET
ドキュメントlookup /indexes/<indexname>/docs/<key> GET
ドキュメント数取得 /indexes/<indexname>/docs/$count GET
サジェスション /indexes/<indexname>/docs/suggest GET
テストアナライザ /indexes/<indexname>/analyze POST
https://<アカウント名>.search.windows.net
{
"@odata.context":
"https://yoichikademo.search.windows.net/
indexes('messages')/$metadata#Collection(
Microsoft.Azure.Search.V2016_09_01.IndexR
esult)",
"value": [
{ "errorMessage": null, "key": "1",
"status": true, "statusCode": 201 },
{ "errorMessage": null, "key": "2",
"status": true, "statusCode": 201 },
{ "errorMessage": null, "key": "3",
"status": true, "statusCode": 201 }
]
}
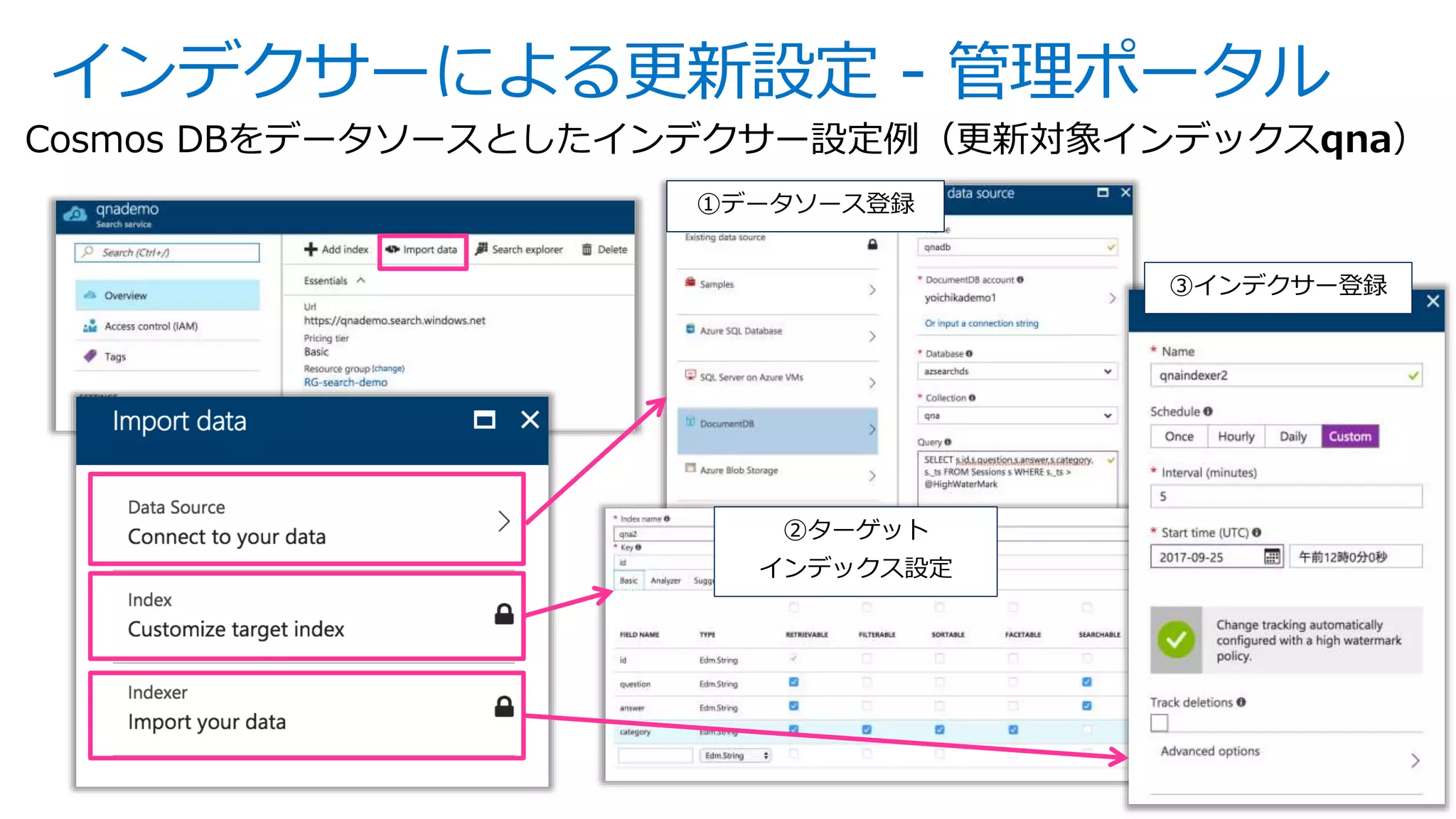
※ APIバージョン 2016-09-21の機能一覧。バージョンごとの機能についてはこちらを参照ください](https://image.slidesharecdn.com/webinar-azuresearchappdev-20170929v3-171010164213/75/Azure-6-2048.jpg)



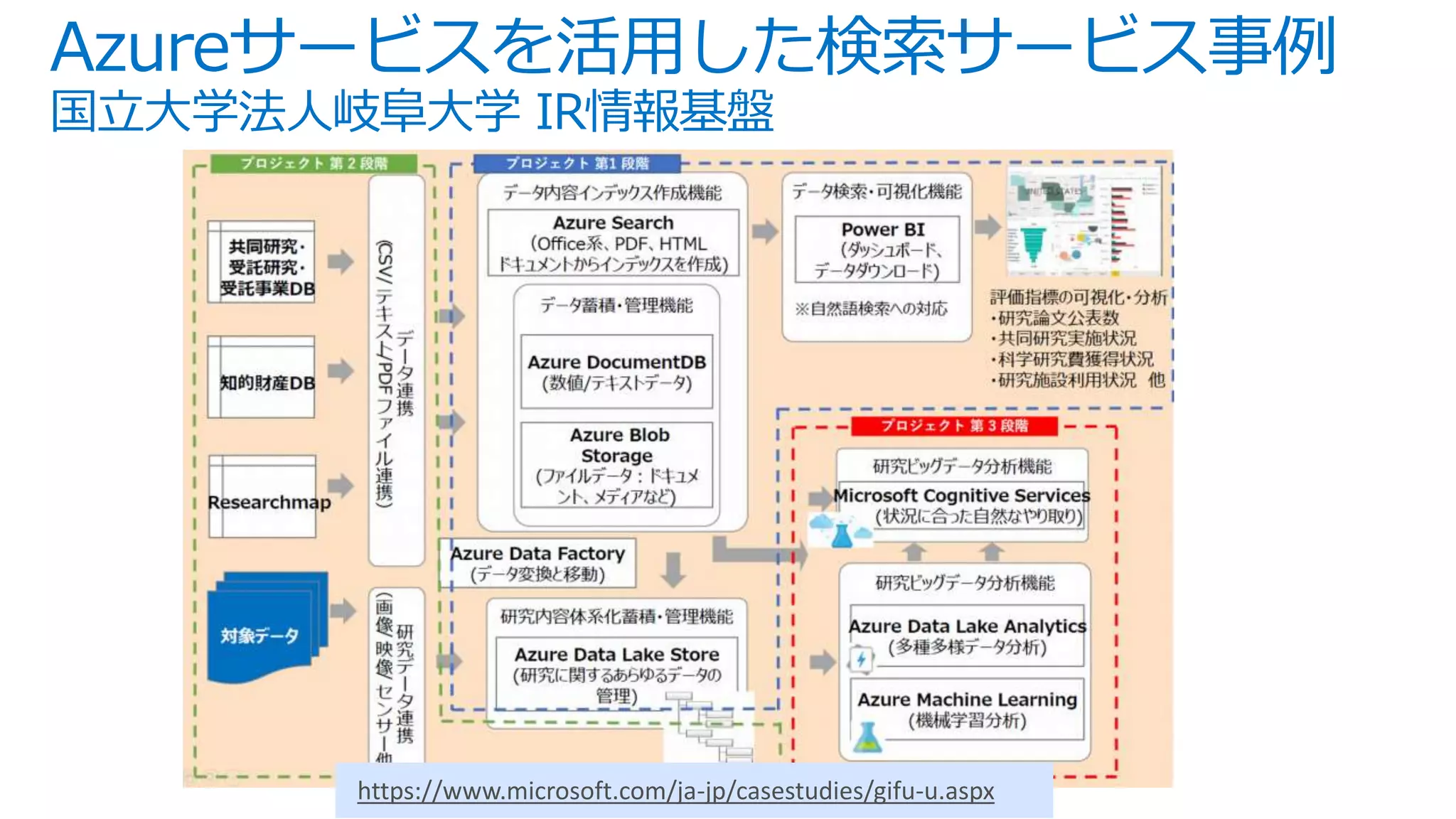




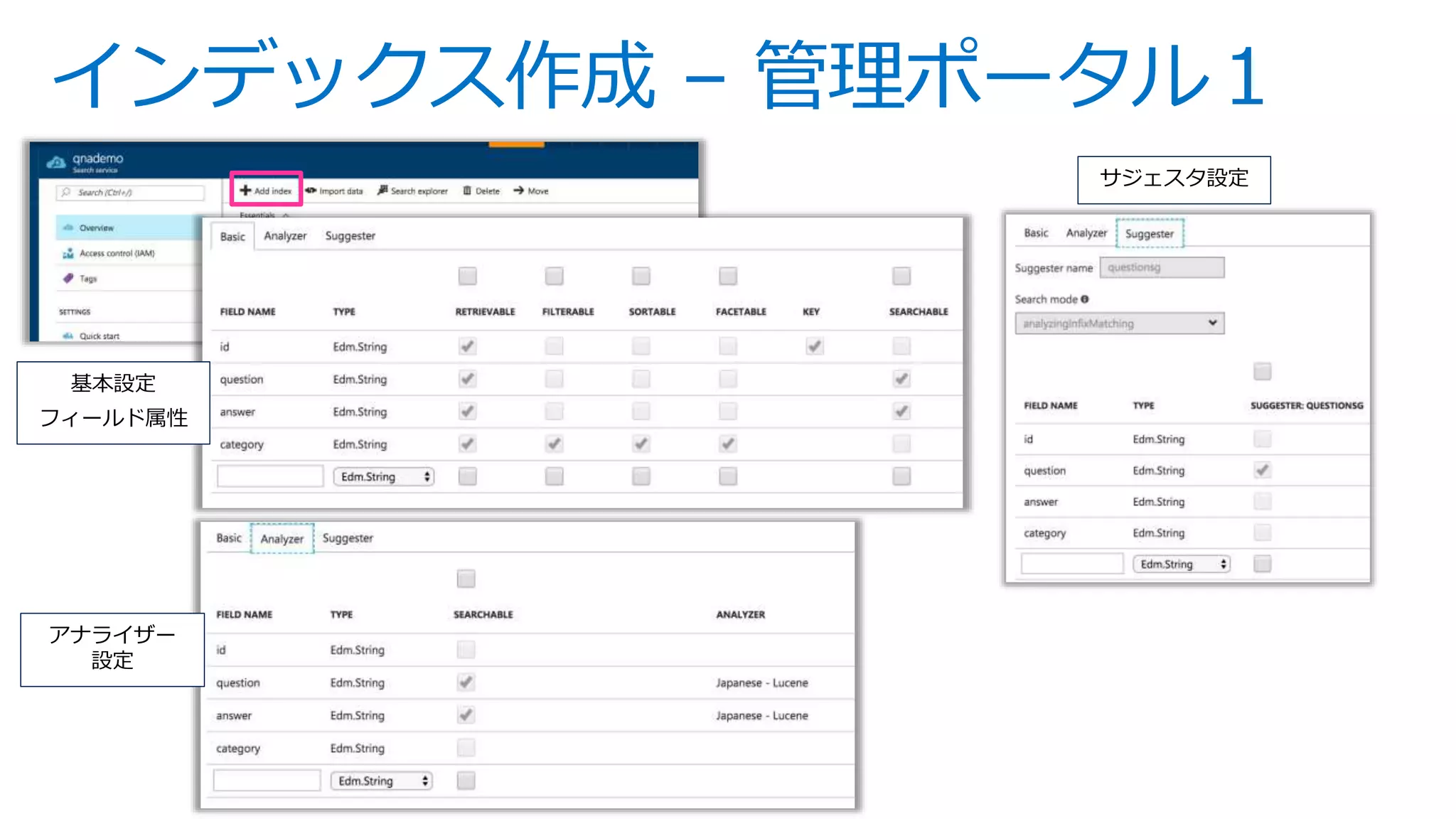
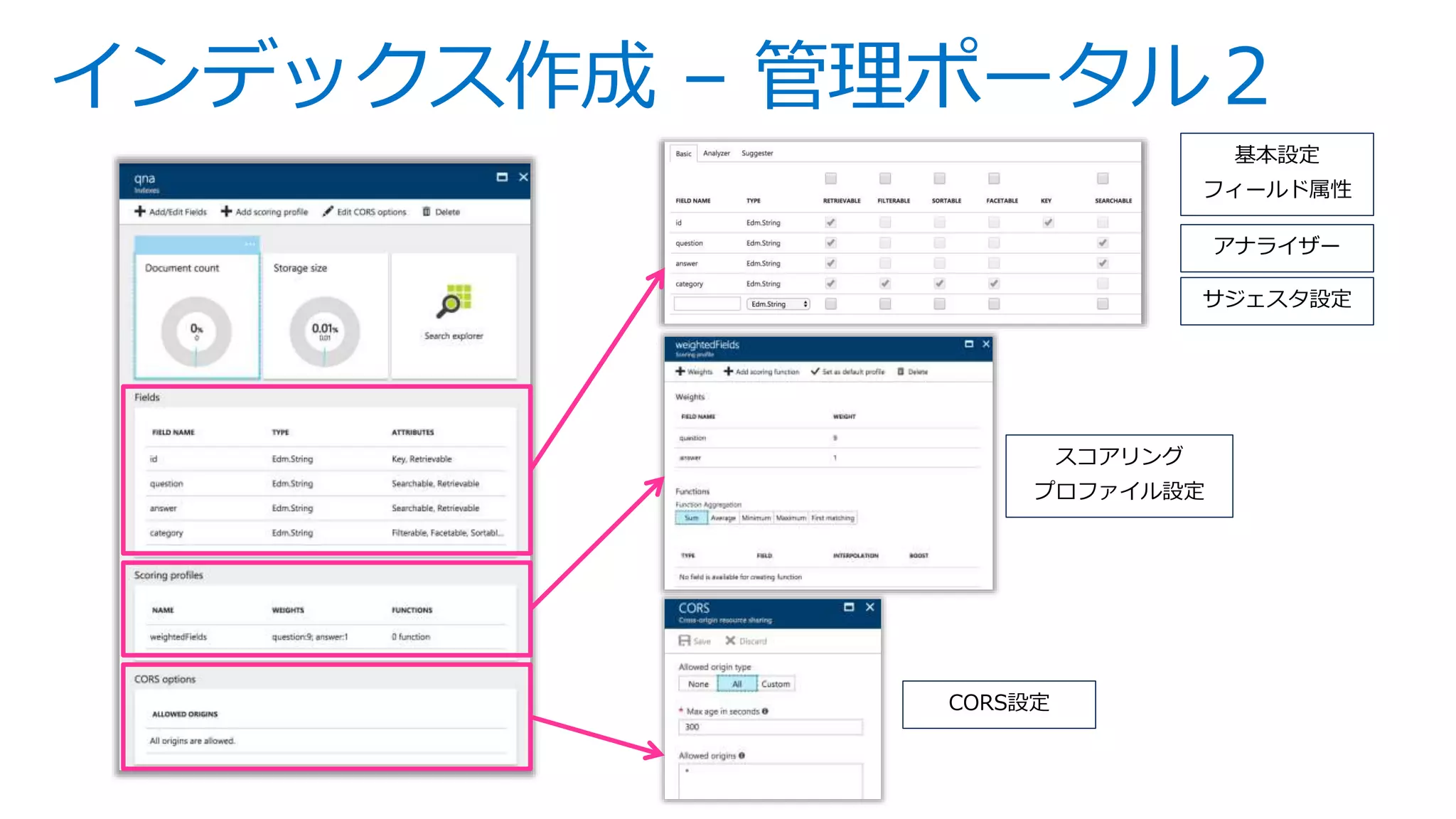
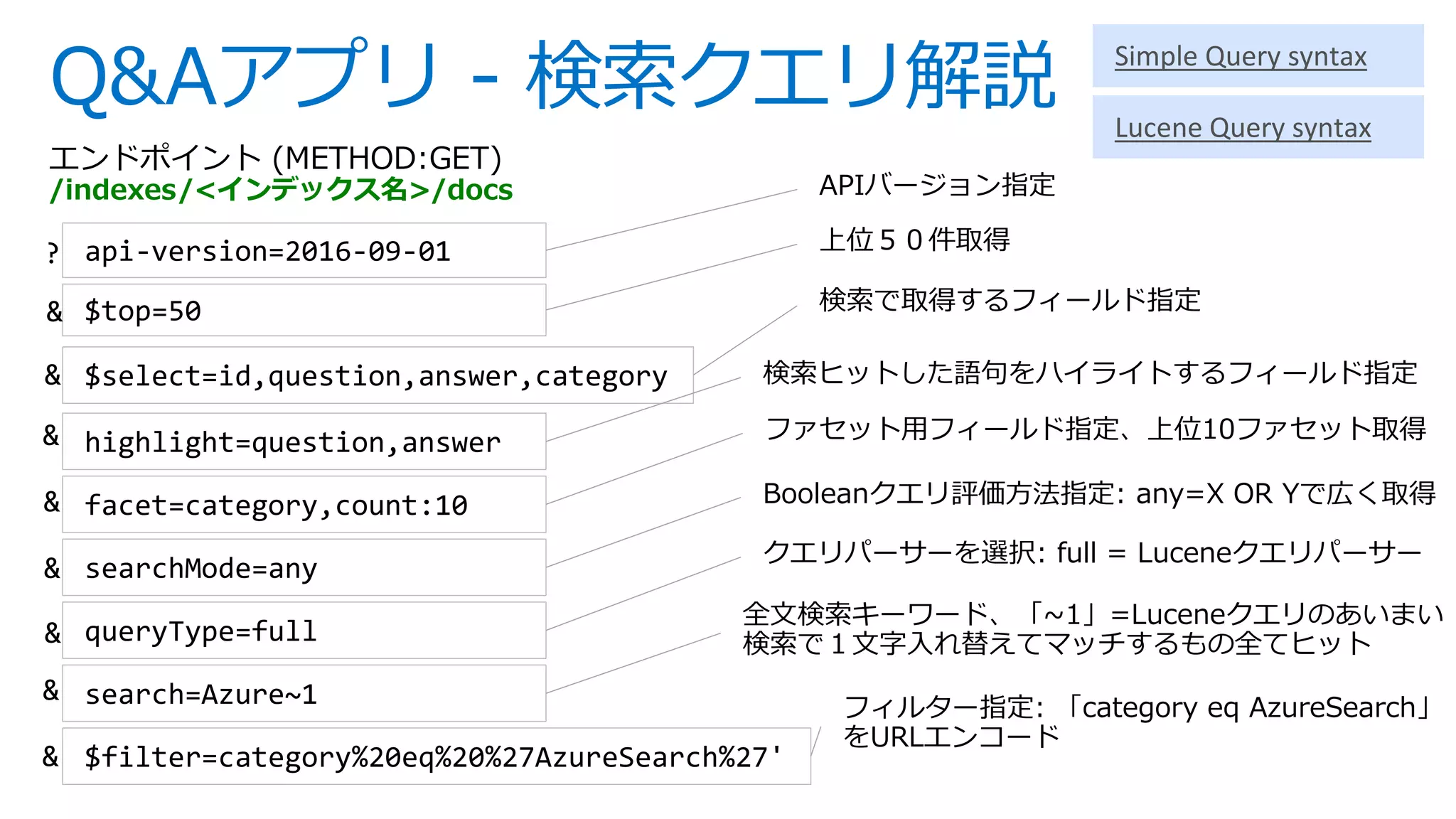
![インデックス作成 – REST API
POST /indexes?api-version=2016-09-01
Host: qnademo.search.windows.net
api-key: 91FAB1CDBD75CF1D39491043BF3491AC
Content-Type: application/json
{
"name": "qna",
"fields": [
{ "name":"id", "type":"Edm.String", "key":true, "retrievable":true, "searchable":false, "filterable":false,
"sortable":false, "facetable":false },
{ "name":"question", "type":"Edm.String", "retrievable":true, "searchable":true, "filterable":false,
"sortable":false, "facetable":false,"analyzer":"ja.lucene"},
{ "name":"answer", "type":"Edm.String", "retrievable":true, "searchable":true, "filterable":false,
"sortable":false, "facetable":false,"analyzer":"ja.lucene"},
{ "name":"category", "type":"Edm.String", "retrievable":true, "searchable":false, "filterable":true,
"sortable":true, "facetable":true }
],
"suggesters": [
{ "name":"questionsg", "searchMode":"analyzingInfixMatching", "sourceFields":["question"] }
],
"scoringProfiles": [
{
"name": "weightedFields",
"text": {
"weights": {
"question": 9,
"answer": 1
}
}
}
],
"corsOptions": {
"allowedOrigins": ["*"],
"maxAgeInSeconds": 300
}
}
基本設定
フィールド属性
アナライザー
サジェスタ設定
CORS設定
スコアリング
プロファイル設定](https://image.slidesharecdn.com/webinar-azuresearchappdev-20170929v3-171010164213/75/Azure-23-2048.jpg)
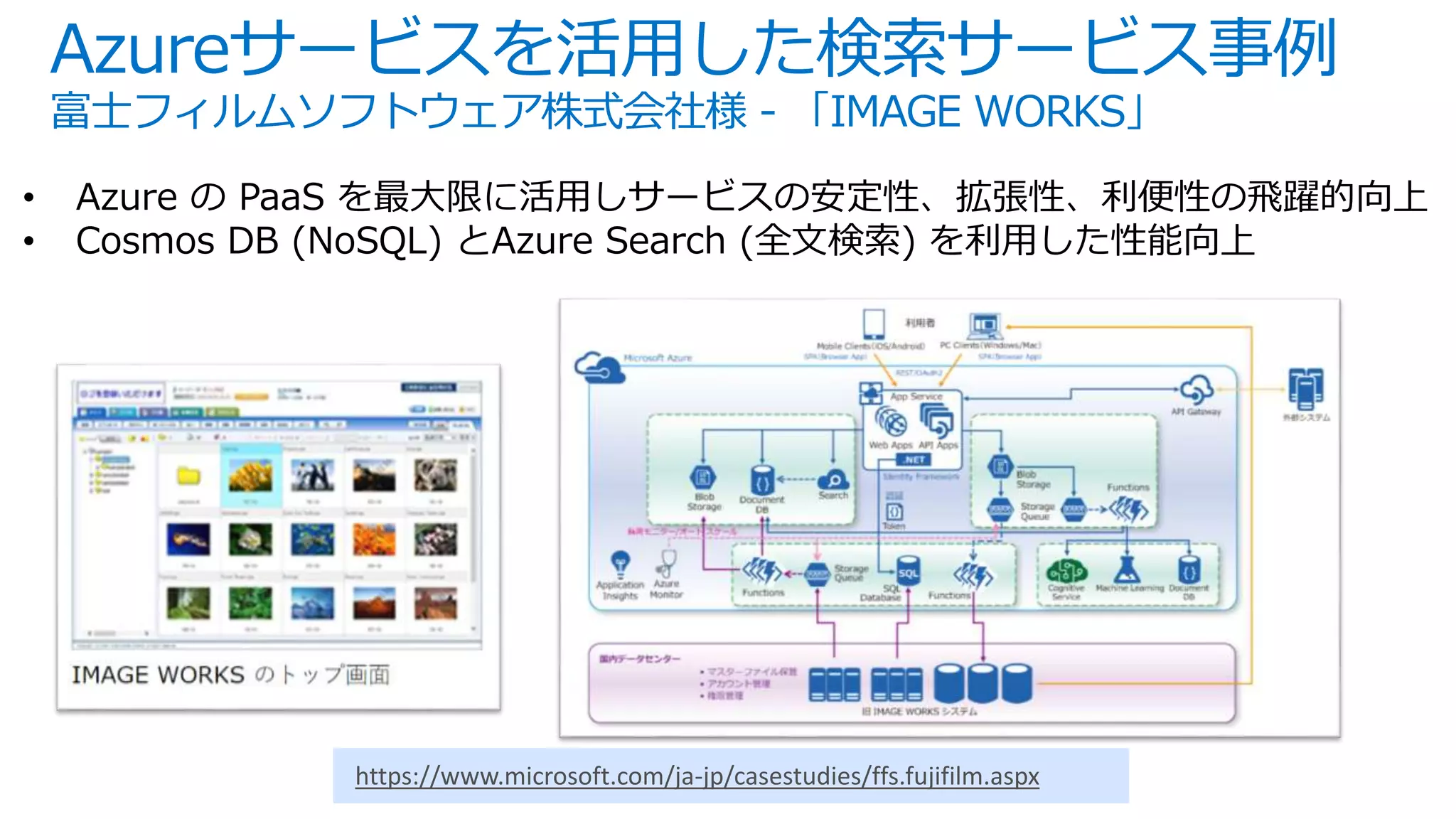
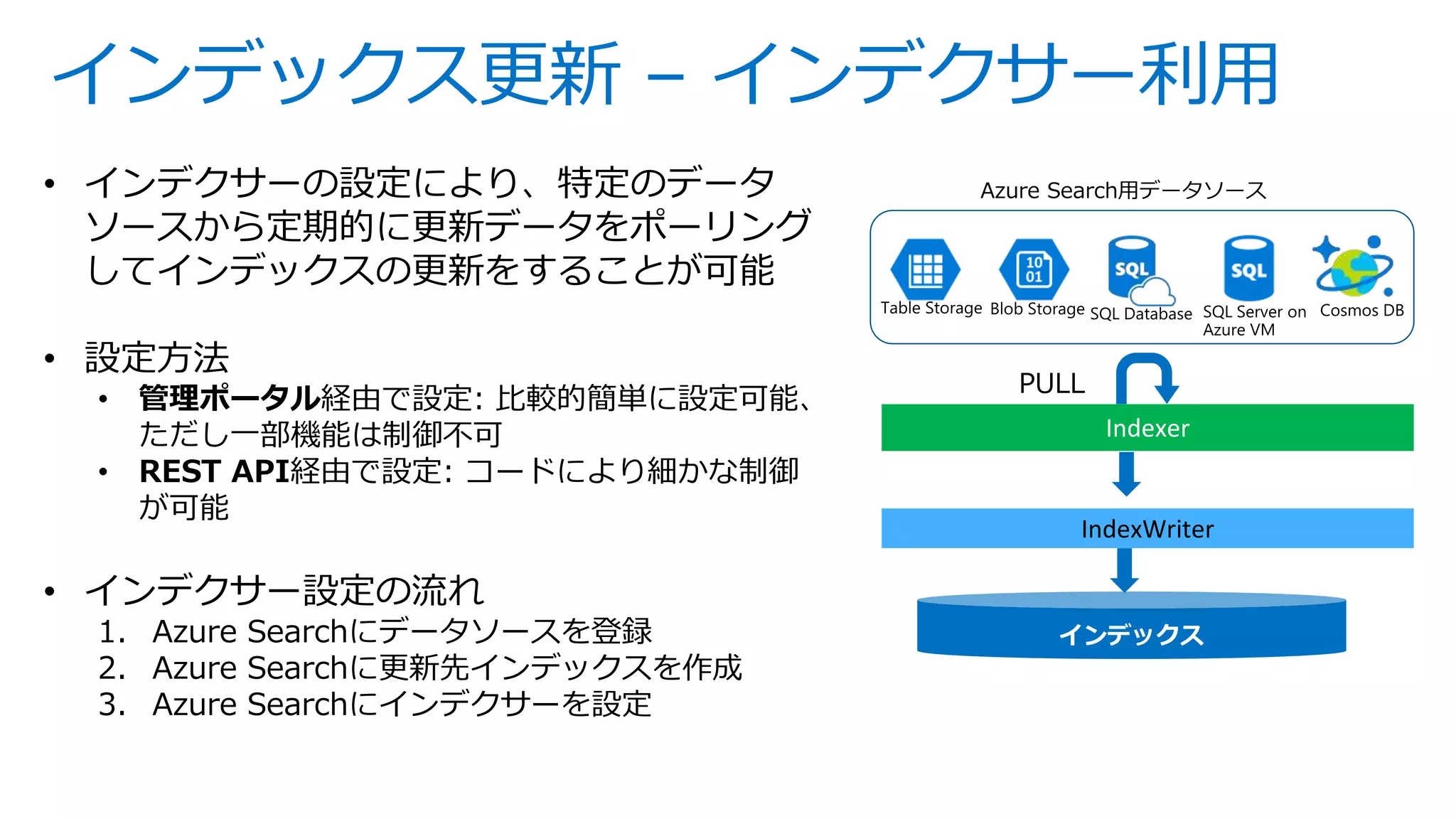
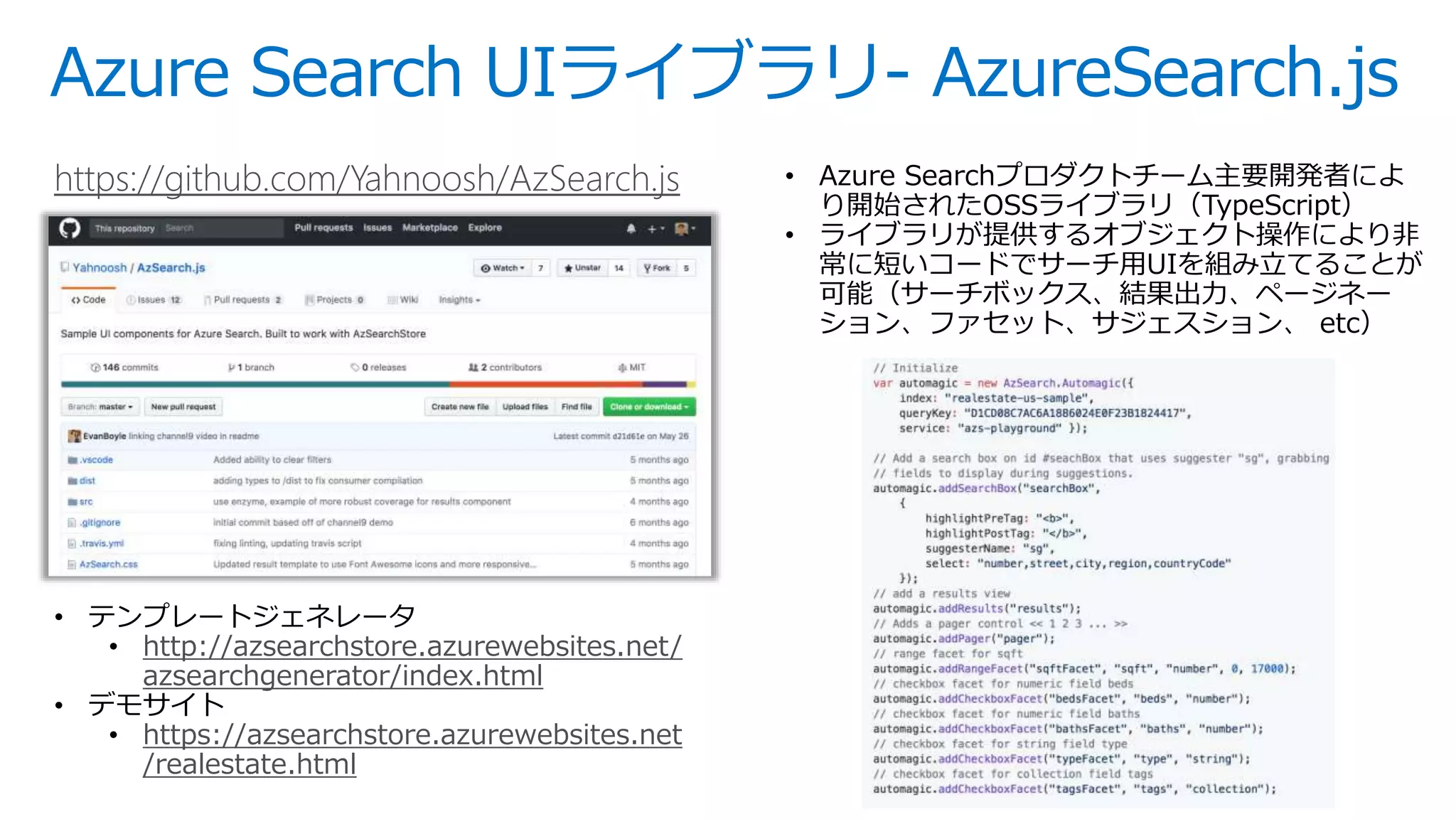
![インデックス更新 – 直接PUSH
APIにドキュメントを直接POSTしてリアルタイム に近いデータ 更新が可能
更新内容反映までの時間はその時のシステムの負荷状況により異なります
POST /indexes/qna/docs/index?api-version=2016-09-01
Host: qnademo.search.windows.net
api-key: 91FAB1CDBD75CF1D39491043BF3491AC
Content-Type: application/json
{
"value": [
{
"@search.action": "upload",
"id": "37e308d0-c62f-45b5-b953-363c3b77c1ea”,
"question": "Azure Cosmos DB とは何ですか?”,
"answer": "Azure Cosmos DB は、グローバルにレプリケートされたマルチモデル…",
"category": "CosmosDB"
},
{
"@search.action": "upload",
"id": "94e26eff-3048-4275-a8d0-4b4856dc6b3c",
"question": "提供されているアルゴリズムは、R または Python で記述されていますか”,
"answer": "いいえ。これらのアルゴリズムは、多くの場合、より優れたパフォーマンスを… ",
"category": "MachineLearning"
},
…
]
}
一度に最大1000ドキュメントまで、
もしくはBODYサイズ最大16MB
までPOSTすることが可能。](https://image.slidesharecdn.com/webinar-azuresearchappdev-20170929v3-171010164213/75/Azure-24-2048.jpg)


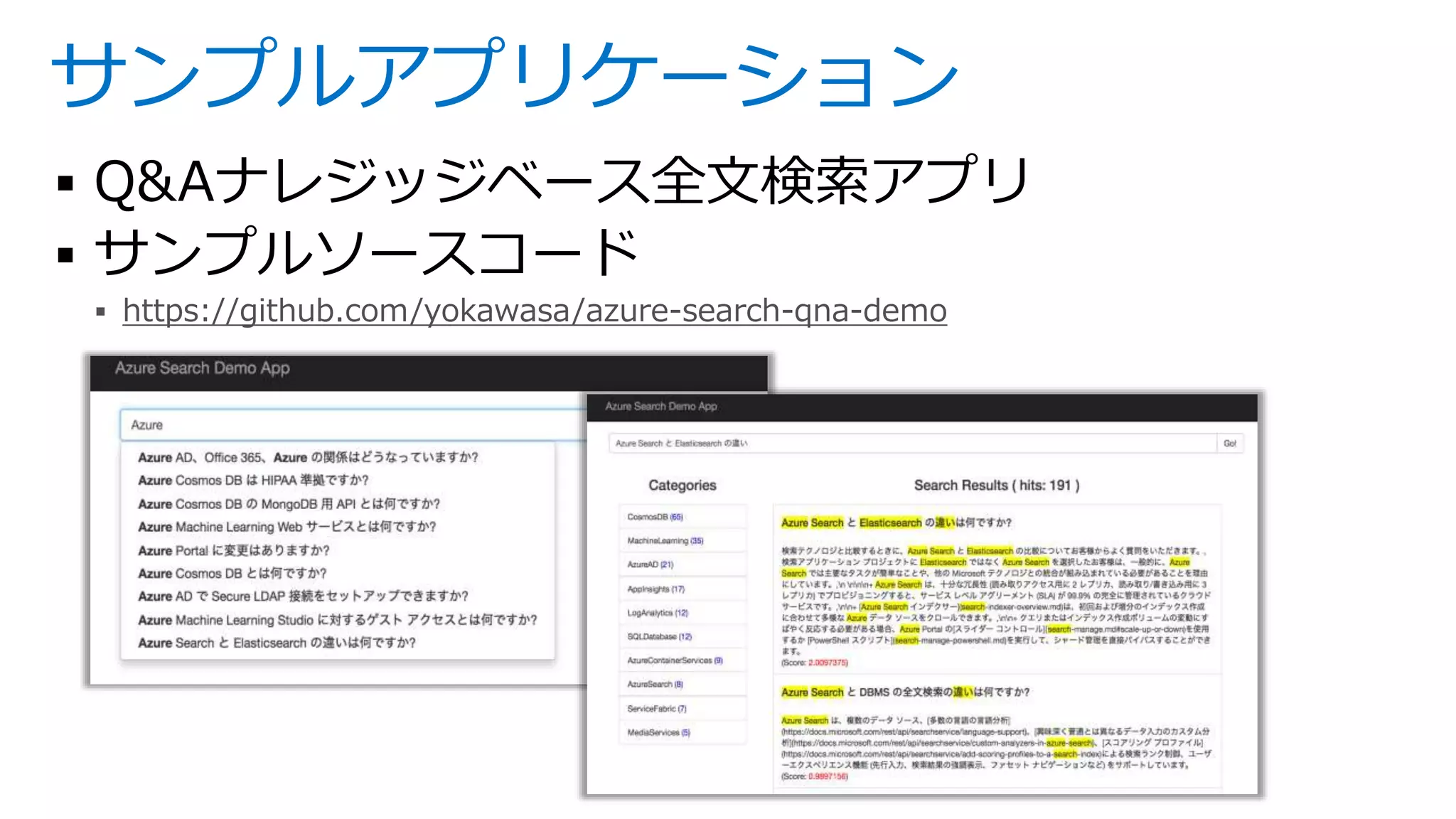
![サジェッション
入力したキーワード文字列に関連の深い語句を逐次予測して表示するための機能
事前に検索対象フィールドをサジェスタ(suggesters)登録する必要があります
"suggesters": [
{
"name":"questionsg",
"searchMode":"analyzingInfixMatching",
"sourceFields":["question"]
}
],
/indexes/qna/docs/suggest
suggesterName
search Azu
文の先頭または中間にある
フレーズのマッチング
(2017-09時点でこのモードのみ)
{
"@odata.context":
"https://qnademo.search.windows.net/indexes(‘qna
')/$metadata#docs(id)",
"value":
{ "@search.text": "Azure AD、Office 365、Azure
の関係はどうなっていますか?",
”id": "3290cbb7-2f62-4948-b984-1bced9a6cb5f"},
{"@search.text": "Azure Cosmos DB の MongoDB
用 API とは何ですか?",
”id": "af19017e-1c72-4b34-b121-9b7efa91cc4a"},
…
]}
https://docs.microsoft.com/en-us/rest/api/searchservice/suggesters](https://image.slidesharecdn.com/webinar-azuresearchappdev-20170929v3-171010164213/75/Azure-30-2048.jpg)


![ファセット・ナビゲーション
ドリルダウンナビゲーションを提供するフィルター処理の一種
スキーマでfacetable:true、filterable:trueで登録されているフィールドを使用
して、クエリ時に作成します
{
"name":”cateogry", "type":"Edm.String",
"searchable": false, "filterable":true,
"sortable":true, "facetable":true
},
インデックス定義でフィールドのファセット有効化
ファセットリクエスト
/indexes/qna/docs
facet
search
"@search.facets": {
"color@odata.type":
"#Collection(Microsoft.Azure.Search.V2016_09_01.Q
ueryResultFacet)",
”category": [
{ "count": 65, "value": ”CosmosDB “ },
{ "count": 35, "value": ”MachineLearning“ },
{ "count": 21, "value": ”AzureAD“ },
{ "count": 17, "value": ”AppInsights “ },
{ "count": 12, "value": “LogAnalytics“ }
…
],
ここでは1ファセットのみ。
複数のファセットを指定す
ることも可能](https://image.slidesharecdn.com/webinar-azuresearchappdev-20170929v3-171010164213/75/Azure-33-2048.jpg)



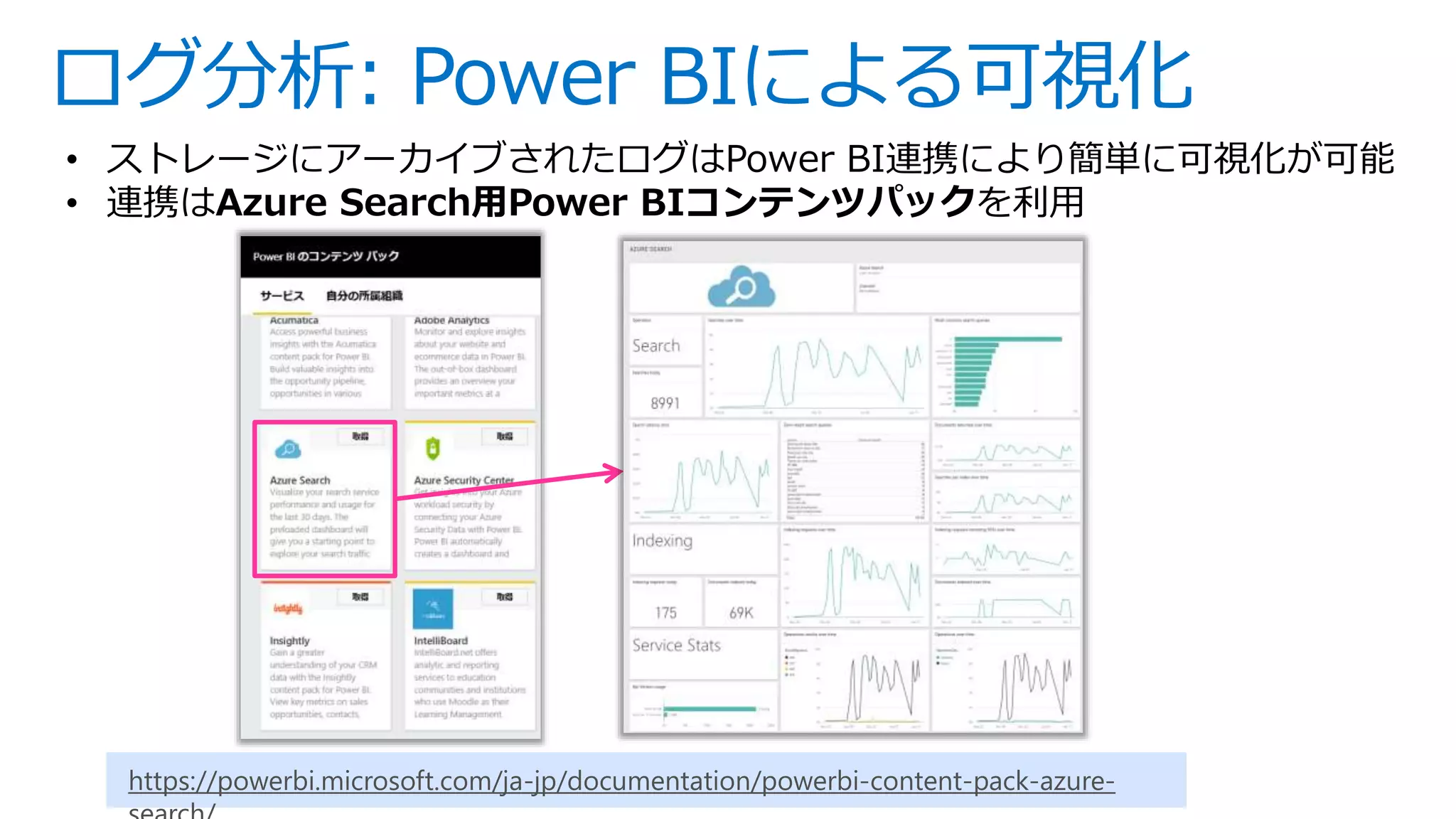



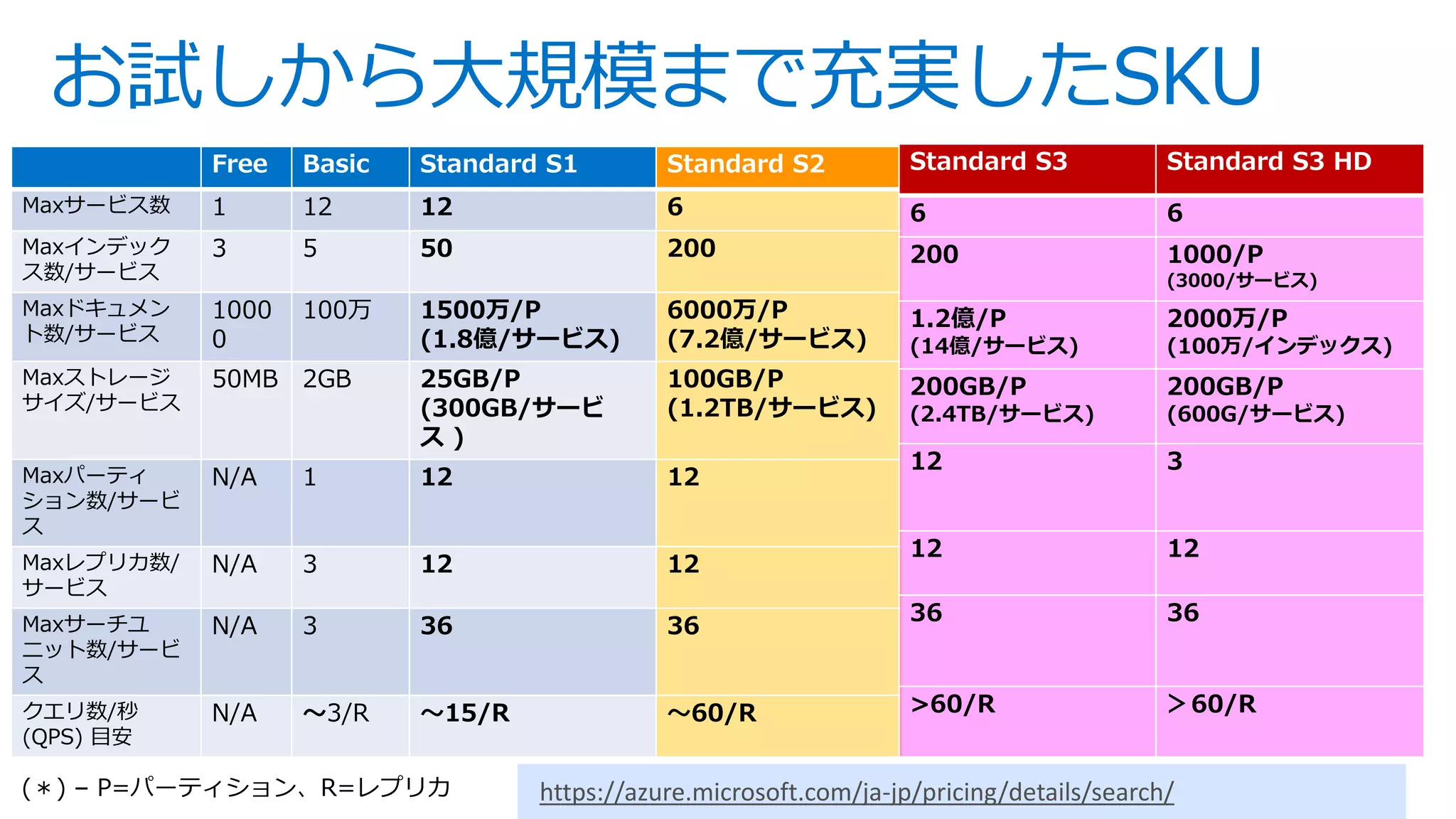


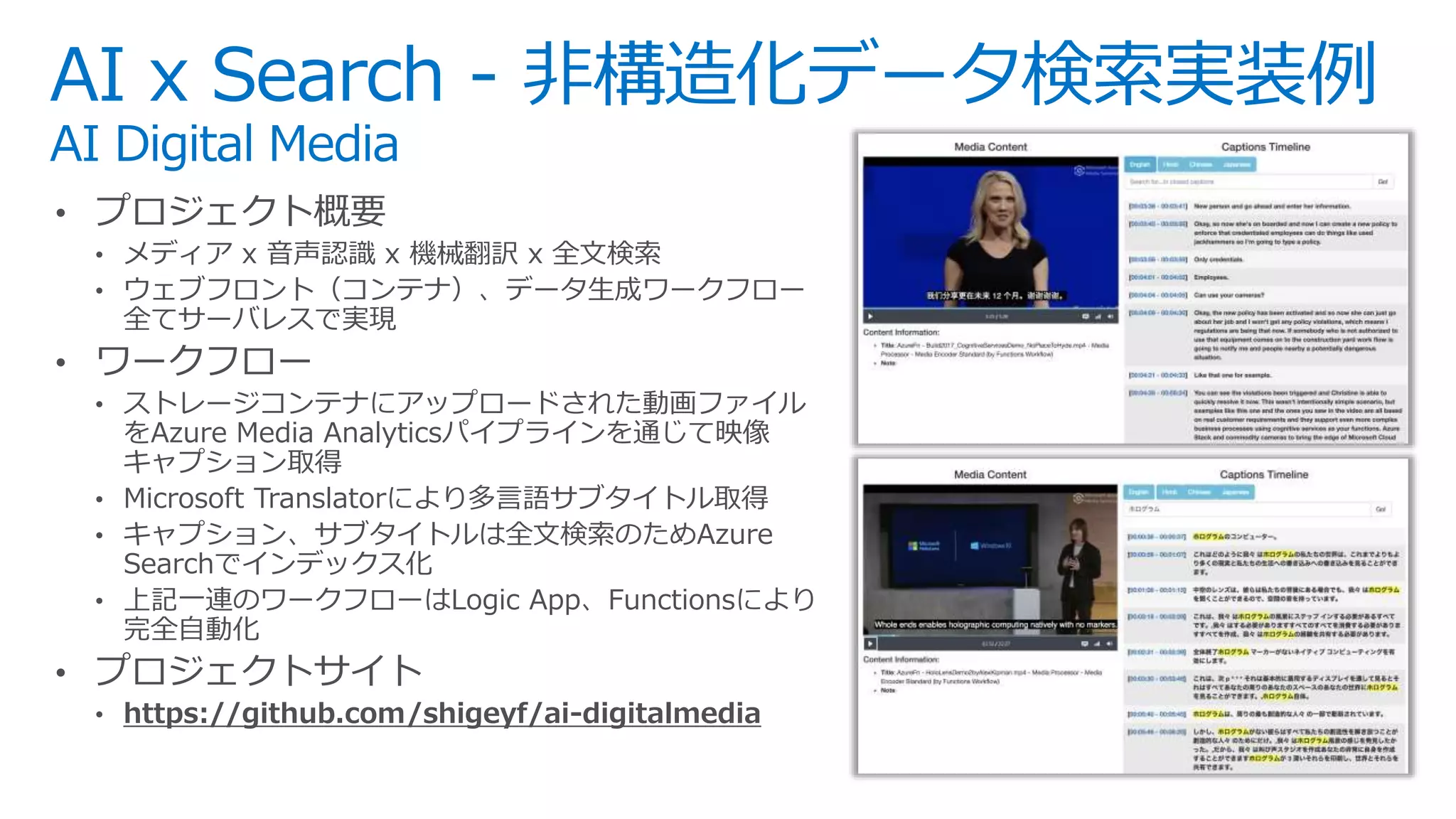
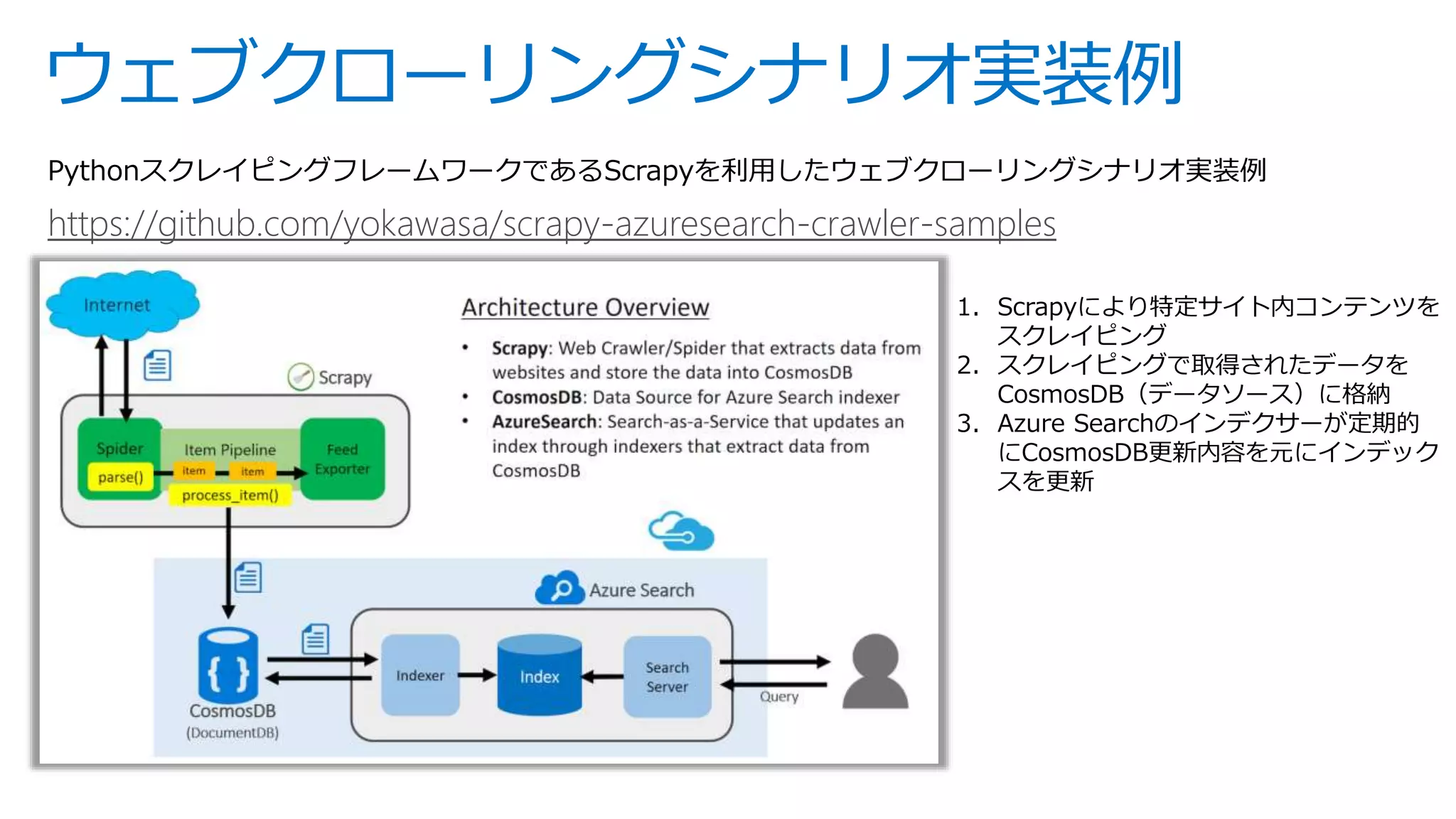

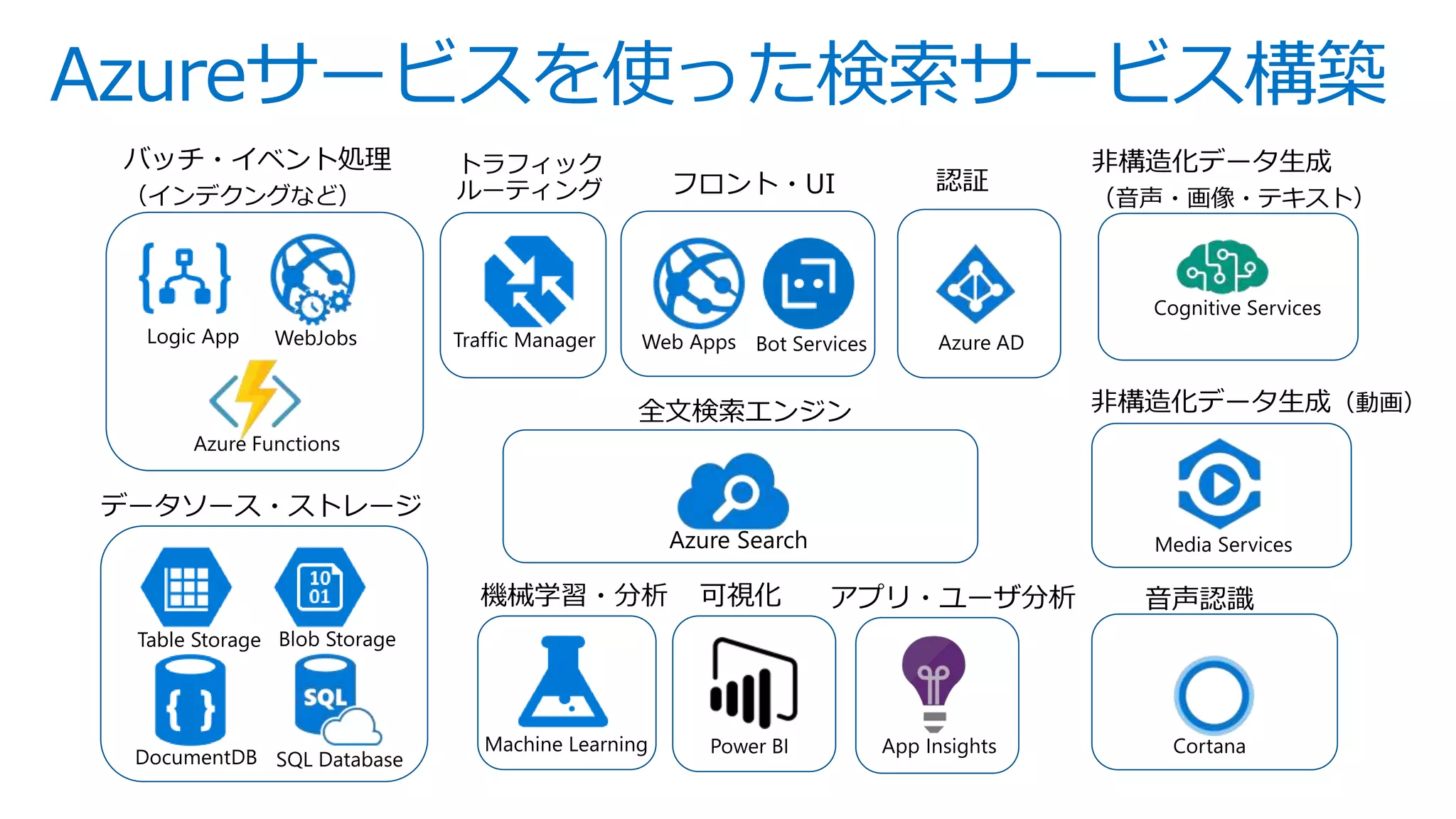
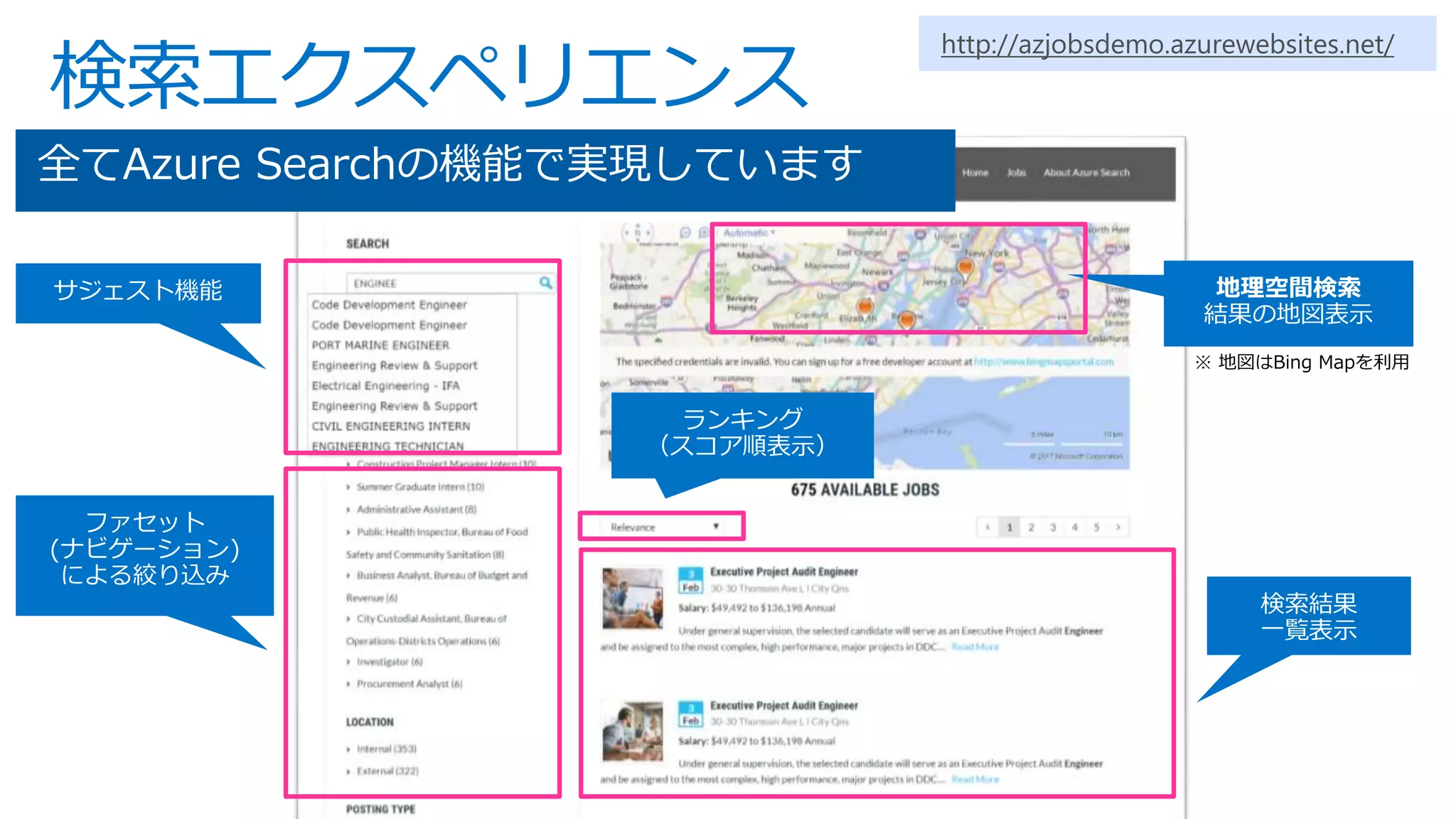
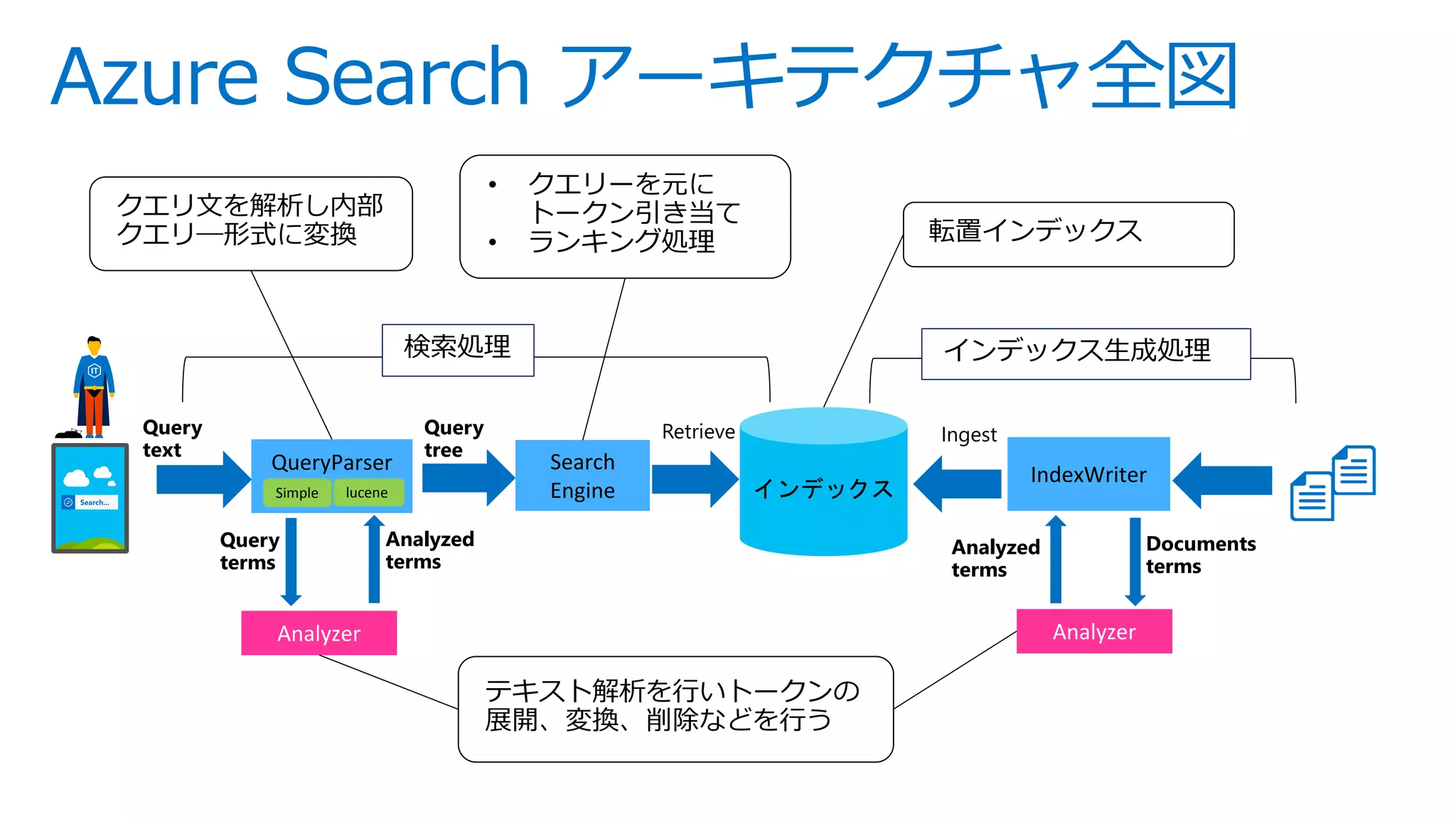
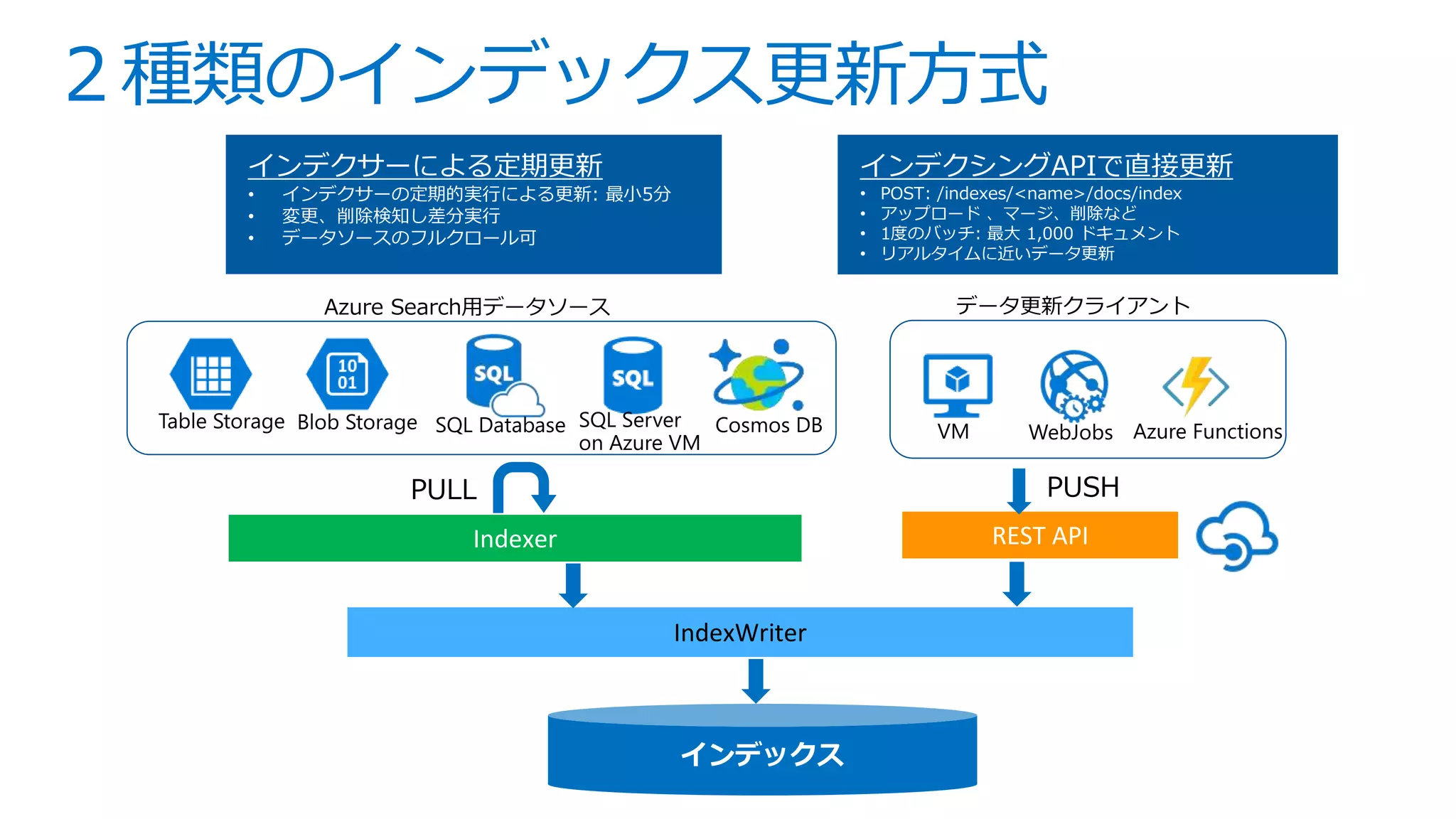
This is slides for Azure Webinar Seminar: Azure Search 今日、検索機能は、eコマース 、SNS、モバイルアプリなどさまざまなサービスにおいてユーザーの主要な操作手法として当たり前のように活用されています。本ウェビナーではモダンアプリケーションを題材にAzure SearchやAzureの主要PaaSサービスを活用した完全マネージドな全文検索アプリケーションの構築方法についてご紹介いたします。 【アジェンダ】 1. 検索機能概要とアプリケーションアーキテクチャ 2. サーチアプリケーション開発




























![[DI08] その情報うまく取り出せていますか? ~ 意外と簡単、Azure Search で短時間で検索精度と利便性を向上させるための方法](https://cdn.slidesharecdn.com/ss_thumbnails/di08-170605024559-thumbnail.jpg?width=640&height=640&fit=bounds)





















































