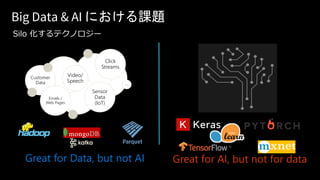
Big Data &AI における課題
Silo 化するテクノロジー
Great for Data, but not AI Great for AI, but not for data
Customer
Data
Emails /
Web Pages
Sensor
Data
(IoT)
Video/
Speech
Click
Streams
…
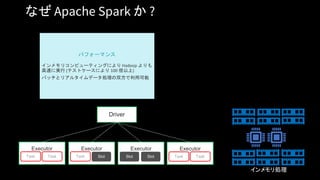
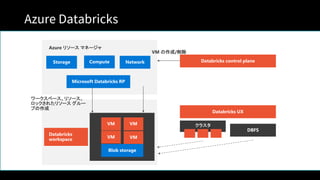
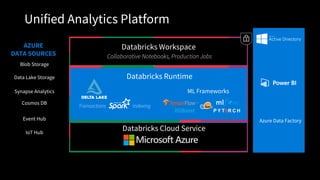
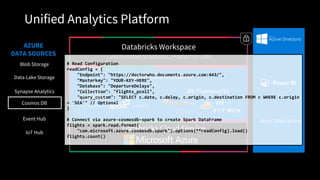
Unified Analytics Platform
DatabricksWorkspace
Collaborative Notebooks, Production Jobs
Databricks Runtime
Databricks Cloud Service
Transactions Indexing
ML Frameworks
Blob Storage
Data Lake Storage
AZURE
DATA SOURCES
Event Hub
IoT Hub
Synapse Analytics
Cosmos DB
Azure Data Factory
19.
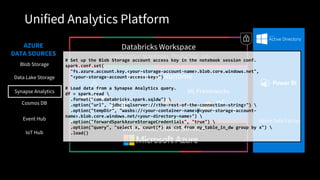
Unified Analytics Platform
DatabricksWorkspace
Collaborative Notebooks, Production Jobs
Databricks Runtime
Databricks Cloud Service
Transactions Indexing
ML Frameworks
Blob Storage
Data Lake Storage
AZURE
DATA SOURCES
Event Hub
IoT Hub
Synapse Analytics
Cosmos DB
Azure Data Factory
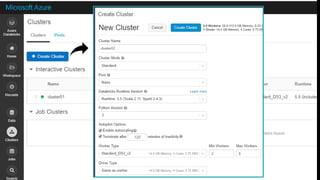
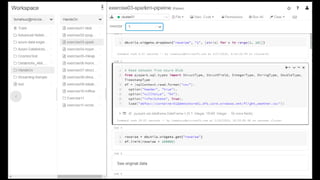
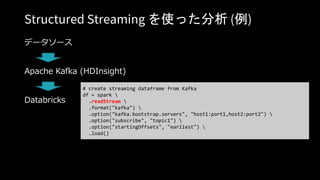
# Read Configuration
readConfig = {
"Endpoint": "https://doctorwho.documents.azure.com:443/",
"Masterkey": "YOUR-KEY-HERE",
"Database": "DepartureDelays",
"Collection": "flights_pcoll",
"query_custom": "SELECT c.date, c.delay, c.origin, c.destination FROM c WHERE c.origin
= 'SEA'" // Optional
}
# Connect via azure-cosmosdb-spark to create Spark DataFrame
flights = spark.read.format(
"com.microsoft.azure.cosmosdb.spark").options(**readConfig).load()
flights.count()
20.
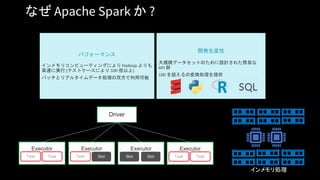
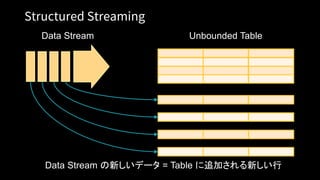
Unified Analytics Platform
DatabricksWorkspace
Collaborative Notebooks, Production Jobs
Databricks Runtime
Databricks Cloud Service
Transactions Indexing
ML Frameworks
Blob Storage
Data Lake Storage
AZURE
DATA SOURCES
Event Hub
IoT Hub
Synapse Analytics
Cosmos DB
Azure Data Factory
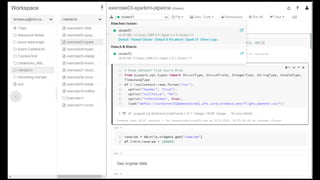
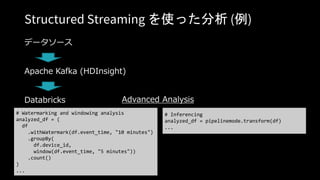
# Set up the Blob Storage account access key in the notebook session conf.
spark.conf.set(
"fs.azure.account.key.<your-storage-account-name>.blob.core.windows.net",
"<your-storage-account-access-key>")
# Load data from a Synapse Analytics query.
df = spark.read
.format("com.databricks.spark.sqldw")
.option("url", "jdbc:sqlserver://<the-rest-of-the-connection-string>")
.option("tempDir", "wasbs://<your-container-name>@<your-storage-account-
name>.blob.core.windows.net/<your-directory-name>")
.option("forwardSparkAzureStorageCredentials", "true")
.option("query", "select x, count(*) as cnt from my_table_in_dw group by x")
.load()
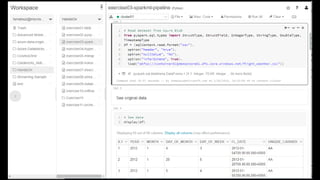
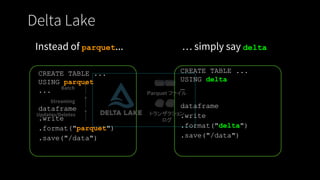
Delta Lake –Reliability
Streaming
● ACID トランザクション
● スキーマエンフォース
● 統合 Batch & Streaming
● Time Travel / スナップショット
主要機能
高品質で高信頼な
データ
いつでも分析に
活用可能
Batch
Updates/Deletes トランザクション
ログ
Parquet ファイル
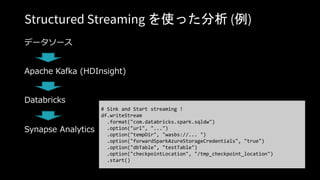
SELECT count(*) FROM events
TIMESTAMP AS OF timestamp
SELECT count(*) FROM events
VERSION AS OF version
spark.read.format("delta").option("timestampAsOf",
timestamp_string).load("/events/")
INSERT INTO my_table
SELECT * FROM my_table TIMESTAMP AS OF
• date_sub(current_date(), 1)
過去のデータの再生成 誤った書き込み時のロールバック
Analytics & AIis the #1 investment for business
leaders, however they struggle to maximize ROI
80% 55%
From : “Understanding Why Analytics Strategies Fall Short for Some, but Not Others”
https://azure.microsoft.com/en-us/resources/why-analytics-strategies-fall-short-for-some-but-not-others/
38.
Apache Spark を内包する製品やサービス
•Azure Synapse Analytics
• Azure Data Factory - Mapping Data Flow *
• Azure Data Factory - Wrangling Data Flow
• SQL Server 2019 Big Data Cluster
* : Azure Databricks を使用
39.
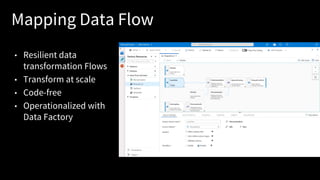
Mapping Data Flow
•Resilient data
transformation Flows
• Transform at scale
• Code-free
• Operationalized with
Data Factory
40.
Apache Spark を内包する製品やサービス
•Azure Cosmos DB
• Azure Synapse Analytics
• Azure Data Factory - Mapping Data Flow *
• Azure Data Factory - Wrangling Data Flow
• SQL Server 2019 Big Data Cluster
* : Azure Databricks を使用

























![[DI12] あらゆるデータをビジネスに活用! Azure Data Lake を中心としたビックデータ処理基盤のアーキテクチャと実装](https://cdn.slidesharecdn.com/ss_thumbnails/di12-170616053736-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DI03] DWH スペシャリストが語る! Azure SQL Data Warehouse チューニングの勘所](https://cdn.slidesharecdn.com/ss_thumbnails/di03-170605023803-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DI10] IoT を実践する最新のプラクティス ~ Azure IoT Hub 、SDK 、Azure IoT Suite ~](https://cdn.slidesharecdn.com/ss_thumbnails/di10-170616053735-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Microsoft Tech Summit 2018] Azure Machine Learning サービスと Azure Databricks で実...](https://cdn.slidesharecdn.com/ss_thumbnails/20181107techsummitazuremldatabricks-181108015121-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DI07] あらゆるデータに価値がある! アンチ断捨離ストのための Azure Data Lake](https://cdn.slidesharecdn.com/ss_thumbnails/di07-170605024557-thumbnail.jpg?width=640&height=640&fit=bounds)
![【ウェブ セミナー】AI 時代のクラウド データ ウェアハウス Azure SQL Data Warehouse [実践編]](https://cdn.slidesharecdn.com/ss_thumbnails/webinarsqldw20170726-180220004900-thumbnail.jpg?width=640&height=640&fit=bounds)

![[ウェビナー] Build 2018 アップデート ~ データ プラットフォーム/IoT編 ~](https://cdn.slidesharecdn.com/ss_thumbnails/20180614azuredataiotwebinar-180614083401-thumbnail.jpg?width=640&height=640&fit=bounds)


![[Microsoft Cognitive Toolkit (CNTK) on Azure ハンズオン] Microsoft Azure の AI 関連サービス](https://cdn.slidesharecdn.com/ss_thumbnails/20170805cntkhandsonmsai-170805043722-thumbnail.jpg?width=640&height=640&fit=bounds)




















