Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Amazon Web Services Japan
PDF, PPTX
5,977 views
[CTO Night & Day 2019] AWS で構築するデータレイク基盤と amazon.com での導入事例 #ctonight
2019年10月に京都で開催された CTO Night & Day 2019 Fall Day1 モーニングセッションでの講演資料です
Technology
◦
Read more
8
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 47
2
/ 47
3
/ 47
4
/ 47
5
/ 47
6
/ 47
7
/ 47
8
/ 47
9
/ 47
10
/ 47
11
/ 47
12
/ 47
13
/ 47
14
/ 47
15
/ 47
16
/ 47
17
/ 47
18
/ 47
19
/ 47
20
/ 47
21
/ 47
22
/ 47
23
/ 47
24
/ 47
25
/ 47
26
/ 47
27
/ 47
28
/ 47
29
/ 47
30
/ 47
31
/ 47
32
/ 47
33
/ 47
34
/ 47
35
/ 47
36
/ 47
37
/ 47
38
/ 47
39
/ 47
40
/ 47
41
/ 47
42
/ 47
43
/ 47
44
/ 47
45
/ 47
46
/ 47
47
/ 47
More Related Content
PDF
データ活用を加速するAWS分析サービスのご紹介
by
Amazon Web Services Japan
PDF
20210330 AWS Black Belt Online Seminar AWS Glue -Glue Studioを使ったデータ変換のベストプラクティス-
by
Amazon Web Services Japan
PPTX
[20220126] JAWS-UG 2022初頭までに葬ったAWSアンチパターン大紹介
by
Amazon Web Services Japan
PDF
20190522 AWS Black Belt Online Seminar AWS Step Functions
by
Amazon Web Services Japan
PDF
20200630 AWS Black Belt Online Seminar Amazon Cognito
by
Amazon Web Services Japan
PDF
20190206 AWS Black Belt Online Seminar Amazon SageMaker Basic Session
by
Amazon Web Services Japan
PPTX
Amazon Athena で実現する データ分析の広がり
by
Amazon Web Services Japan
PDF
Infrastructure as Code (IaC) 談義 2022
by
Amazon Web Services Japan
データ活用を加速するAWS分析サービスのご紹介
by
Amazon Web Services Japan
20210330 AWS Black Belt Online Seminar AWS Glue -Glue Studioを使ったデータ変換のベストプラクティス-
by
Amazon Web Services Japan
[20220126] JAWS-UG 2022初頭までに葬ったAWSアンチパターン大紹介
by
Amazon Web Services Japan
20190522 AWS Black Belt Online Seminar AWS Step Functions
by
Amazon Web Services Japan
20200630 AWS Black Belt Online Seminar Amazon Cognito
by
Amazon Web Services Japan
20190206 AWS Black Belt Online Seminar Amazon SageMaker Basic Session
by
Amazon Web Services Japan
Amazon Athena で実現する データ分析の広がり
by
Amazon Web Services Japan
Infrastructure as Code (IaC) 談義 2022
by
Amazon Web Services Japan
What's hot
PDF
Kinesis + Elasticsearchでつくるさいきょうのログ分析基盤
by
Amazon Web Services Japan
PDF
AWSではじめるMLOps
by
MariOhbuchi
PDF
20191001 AWS Black Belt Online Seminar AWS Lake Formation
by
Amazon Web Services Japan
PDF
20201118 AWS Black Belt Online Seminar 形で考えるサーバーレス設計 サーバーレスユースケースパターン解説
by
Amazon Web Services Japan
PDF
20210127 AWS Black Belt Online Seminar Amazon Redshift 運用管理
by
Amazon Web Services Japan
PDF
20200422 AWS Black Belt Online Seminar Amazon Elastic Container Service (Amaz...
by
Amazon Web Services Japan
PDF
20210216 AWS Black Belt Online Seminar AWS Database Migration Service
by
Amazon Web Services Japan
PDF
DevOps with Database on AWS
by
Amazon Web Services Japan
PDF
20190821 AWS Black Belt Online Seminar AWS AppSync
by
Amazon Web Services Japan
PDF
IAM Roles Anywhereのない世界とある世界(2022年のAWSアップデートを振り返ろう ~Season 4~ 発表資料)
by
NTT DATA Technology & Innovation
PDF
Amazon Athena 初心者向けハンズオン
by
Amazon Web Services Japan
PPTX
AWSで作る分析基盤
by
Yu Otsubo
PDF
202205 AWS Black Belt Online Seminar Amazon VPC IP Address Manager (IPAM)
by
Amazon Web Services Japan
PPTX
20220409 AWS BLEA 開発にあたって検討したこと
by
Amazon Web Services Japan
PDF
20191023 AWS Black Belt Online Seminar Amazon EMR
by
Amazon Web Services Japan
PDF
AWS BlackBelt AWS上でのDDoS対策
by
Amazon Web Services Japan
PDF
[AWS EXpert Online for JAWS-UG 18] 見せてやるよ、Step Functions の本気ってやつをな
by
Amazon Web Services Japan
PDF
20190911 AWS Black Belt Online Seminar AWS Batch
by
Amazon Web Services Japan
PDF
20191016 AWS Black Belt Online Seminar Amazon Route 53 Resolver
by
Amazon Web Services Japan
PDF
Apache Sparkに手を出してヤケドしないための基本 ~「Apache Spark入門より」~ (デブサミ 2016 講演資料)
by
NTT DATA OSS Professional Services
Kinesis + Elasticsearchでつくるさいきょうのログ分析基盤
by
Amazon Web Services Japan
AWSではじめるMLOps
by
MariOhbuchi
20191001 AWS Black Belt Online Seminar AWS Lake Formation
by
Amazon Web Services Japan
20201118 AWS Black Belt Online Seminar 形で考えるサーバーレス設計 サーバーレスユースケースパターン解説
by
Amazon Web Services Japan
20210127 AWS Black Belt Online Seminar Amazon Redshift 運用管理
by
Amazon Web Services Japan
20200422 AWS Black Belt Online Seminar Amazon Elastic Container Service (Amaz...
by
Amazon Web Services Japan
20210216 AWS Black Belt Online Seminar AWS Database Migration Service
by
Amazon Web Services Japan
DevOps with Database on AWS
by
Amazon Web Services Japan
20190821 AWS Black Belt Online Seminar AWS AppSync
by
Amazon Web Services Japan
IAM Roles Anywhereのない世界とある世界(2022年のAWSアップデートを振り返ろう ~Season 4~ 発表資料)
by
NTT DATA Technology & Innovation
Amazon Athena 初心者向けハンズオン
by
Amazon Web Services Japan
AWSで作る分析基盤
by
Yu Otsubo
202205 AWS Black Belt Online Seminar Amazon VPC IP Address Manager (IPAM)
by
Amazon Web Services Japan
20220409 AWS BLEA 開発にあたって検討したこと
by
Amazon Web Services Japan
20191023 AWS Black Belt Online Seminar Amazon EMR
by
Amazon Web Services Japan
AWS BlackBelt AWS上でのDDoS対策
by
Amazon Web Services Japan
[AWS EXpert Online for JAWS-UG 18] 見せてやるよ、Step Functions の本気ってやつをな
by
Amazon Web Services Japan
20190911 AWS Black Belt Online Seminar AWS Batch
by
Amazon Web Services Japan
20191016 AWS Black Belt Online Seminar Amazon Route 53 Resolver
by
Amazon Web Services Japan
Apache Sparkに手を出してヤケドしないための基本 ~「Apache Spark入門より」~ (デブサミ 2016 講演資料)
by
NTT DATA OSS Professional Services
Similar to [CTO Night & Day 2019] AWS で構築するデータレイク基盤と amazon.com での導入事例 #ctonight
PDF
AWS Black Belt - AWS Glue
by
Amazon Web Services Japan
PDF
20200617 AWS Black Belt Online Seminar Amazon Athena
by
Amazon Web Services Japan
PDF
AWS Glueを使った Serverless ETL の実装パターン
by
seiichi arai
PDF
Amazon S3を中心とするデータ分析のベストプラクティス
by
Amazon Web Services Japan
PDF
ビッグデータサービス群のおさらい & AWS Data Pipeline
by
Amazon Web Services Japan
PDF
Effective Data Lakes - ユースケースとデザインパターン
by
Noritaka Sekiyama
PDF
20180619 AWS Black Belt Online Seminar データレイク入門: AWSで様々な規模のデータレイクを分析する効率的な方法
by
Amazon Web Services Japan
PDF
AWS Black Belt Techシリーズ AWS Data Pipeline
by
Amazon Web Services Japan
PDF
AWSの様々なアーキテクチャ
by
Kameda Harunobu
PDF
Amazon Game Tech Night #22 AWSで実現するデータレイクとアナリティクス
by
Amazon Web Services Japan
PDF
データレイクを基盤としたAWS上での機械学習サービス構築
by
Amazon Web Services Japan
PDF
Serverless services on_aws_dmm_meetup_20170801
by
Amazon Web Services Japan
PPTX
AWS朝会2022/1 セッション① 数年間、レイクハウスを設計運用してみた
by
tatsuya 264
PDF
Serverless analytics on aws
by
Amazon Web Services Japan
PPTX
Security Operations and Automation on AWS
by
Noritaka Sekiyama
PDF
IoTデザインパターン 2015 JAWS沖縄
by
Toshiaki Enami
PDF
Data discoveryを支えるawsのbig data技術と最新事例
by
Takashi Koyanagawa
PDF
Developers.IO 2019 Effective Datalake
by
Satoru Ishikawa
PPTX
Game Architecture Trends in Tokyo Kansai Social Game Study#5
by
Yasuhiro Matsuo
PPTX
Glueの開発環境(zeppelin)をrancherで作ってみる
by
cloudfish
AWS Black Belt - AWS Glue
by
Amazon Web Services Japan
20200617 AWS Black Belt Online Seminar Amazon Athena
by
Amazon Web Services Japan
AWS Glueを使った Serverless ETL の実装パターン
by
seiichi arai
Amazon S3を中心とするデータ分析のベストプラクティス
by
Amazon Web Services Japan
ビッグデータサービス群のおさらい & AWS Data Pipeline
by
Amazon Web Services Japan
Effective Data Lakes - ユースケースとデザインパターン
by
Noritaka Sekiyama
20180619 AWS Black Belt Online Seminar データレイク入門: AWSで様々な規模のデータレイクを分析する効率的な方法
by
Amazon Web Services Japan
AWS Black Belt Techシリーズ AWS Data Pipeline
by
Amazon Web Services Japan
AWSの様々なアーキテクチャ
by
Kameda Harunobu
Amazon Game Tech Night #22 AWSで実現するデータレイクとアナリティクス
by
Amazon Web Services Japan
データレイクを基盤としたAWS上での機械学習サービス構築
by
Amazon Web Services Japan
Serverless services on_aws_dmm_meetup_20170801
by
Amazon Web Services Japan
AWS朝会2022/1 セッション① 数年間、レイクハウスを設計運用してみた
by
tatsuya 264
Serverless analytics on aws
by
Amazon Web Services Japan
Security Operations and Automation on AWS
by
Noritaka Sekiyama
IoTデザインパターン 2015 JAWS沖縄
by
Toshiaki Enami
Data discoveryを支えるawsのbig data技術と最新事例
by
Takashi Koyanagawa
Developers.IO 2019 Effective Datalake
by
Satoru Ishikawa
Game Architecture Trends in Tokyo Kansai Social Game Study#5
by
Yasuhiro Matsuo
Glueの開発環境(zeppelin)をrancherで作ってみる
by
cloudfish
More from Amazon Web Services Japan
PDF
20211203 AWS Black Belt Online Seminar AWS re:Invent 2021アップデート速報
by
Amazon Web Services Japan
PDF
マルチテナント化で知っておきたいデータベースのこと
by
Amazon Web Services Japan
PDF
Amazon Game Tech Night #25 ゲーム業界向け機械学習最新状況アップデート
by
Amazon Web Services Japan
PDF
202201 AWS Black Belt Online Seminar Apache Spark Performnace Tuning for AWS ...
by
Amazon Web Services Japan
PDF
機密データとSaaSは共存しうるのか!?セキュリティー重視のユーザー層を取り込む為のネットワーク通信のアプローチ
by
Amazon Web Services Japan
PDF
202202 AWS Black Belt Online Seminar AWS Managed Rules for AWS WAF の活用
by
Amazon Web Services Japan
PDF
202205 AWS Black Belt Online Seminar Amazon FSx for OpenZFS
by
Amazon Web Services Japan
PDF
202204 AWS Black Belt Online Seminar Amazon Connect を活用したオンコール対応の実現
by
Amazon Web Services Japan
PDF
SaaS テナント毎のコストを把握するための「AWS Application Cost Profiler」のご紹介
by
Amazon Web Services Japan
PDF
202112 AWS Black Belt Online Seminar 店内の「今」をお届けする小売業向けリアルタイム配信基盤のレシピ
by
Amazon Web Services Japan
PDF
パッケージソフトウェアを簡単にSaaS化!?既存の資産を使ったSaaS化手法のご紹介
by
Amazon Web Services Japan
PDF
202202 AWS Black Belt Online Seminar AWS SaaS Boost で始めるSaaS開発⼊⾨
by
Amazon Web Services Japan
PDF
Amazon QuickSight の組み込み方法をちょっぴりDD
by
Amazon Web Services Japan
PDF
202204 AWS Black Belt Online Seminar AWS IoT Device Defender
by
Amazon Web Services Japan
PDF
202204 AWS Black Belt Online Seminar Amazon Connect Salesforce連携(第1回 CTI Adap...
by
Amazon Web Services Japan
PDF
202202 AWS Black Belt Online Seminar Amazon Connect Customer Profiles
by
Amazon Web Services Japan
PDF
202203 AWS Black Belt Online Seminar Amazon Connect Tasks.pdf
by
Amazon Web Services Japan
PDF
20211209 Ops-JAWS Re invent2021re-cap-cloud operations
by
Amazon Web Services Japan
PDF
Amazon Game Tech Night #24 KPIダッシュボードを最速で用意するために
by
Amazon Web Services Japan
PDF
202111 AWS Black Belt Online Seminar AWSで構築するSmart Mirrorのご紹介
by
Amazon Web Services Japan
20211203 AWS Black Belt Online Seminar AWS re:Invent 2021アップデート速報
by
Amazon Web Services Japan
マルチテナント化で知っておきたいデータベースのこと
by
Amazon Web Services Japan
Amazon Game Tech Night #25 ゲーム業界向け機械学習最新状況アップデート
by
Amazon Web Services Japan
202201 AWS Black Belt Online Seminar Apache Spark Performnace Tuning for AWS ...
by
Amazon Web Services Japan
機密データとSaaSは共存しうるのか!?セキュリティー重視のユーザー層を取り込む為のネットワーク通信のアプローチ
by
Amazon Web Services Japan
202202 AWS Black Belt Online Seminar AWS Managed Rules for AWS WAF の活用
by
Amazon Web Services Japan
202205 AWS Black Belt Online Seminar Amazon FSx for OpenZFS
by
Amazon Web Services Japan
202204 AWS Black Belt Online Seminar Amazon Connect を活用したオンコール対応の実現
by
Amazon Web Services Japan
SaaS テナント毎のコストを把握するための「AWS Application Cost Profiler」のご紹介
by
Amazon Web Services Japan
202112 AWS Black Belt Online Seminar 店内の「今」をお届けする小売業向けリアルタイム配信基盤のレシピ
by
Amazon Web Services Japan
パッケージソフトウェアを簡単にSaaS化!?既存の資産を使ったSaaS化手法のご紹介
by
Amazon Web Services Japan
202202 AWS Black Belt Online Seminar AWS SaaS Boost で始めるSaaS開発⼊⾨
by
Amazon Web Services Japan
Amazon QuickSight の組み込み方法をちょっぴりDD
by
Amazon Web Services Japan
202204 AWS Black Belt Online Seminar AWS IoT Device Defender
by
Amazon Web Services Japan
202204 AWS Black Belt Online Seminar Amazon Connect Salesforce連携(第1回 CTI Adap...
by
Amazon Web Services Japan
202202 AWS Black Belt Online Seminar Amazon Connect Customer Profiles
by
Amazon Web Services Japan
202203 AWS Black Belt Online Seminar Amazon Connect Tasks.pdf
by
Amazon Web Services Japan
20211209 Ops-JAWS Re invent2021re-cap-cloud operations
by
Amazon Web Services Japan
Amazon Game Tech Night #24 KPIダッシュボードを最速で用意するために
by
Amazon Web Services Japan
202111 AWS Black Belt Online Seminar AWSで構築するSmart Mirrorのご紹介
by
Amazon Web Services Japan
[CTO Night & Day 2019] AWS で構築するデータレイク基盤と amazon.com での導入事例 #ctonight
1.
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved. Morning Session AWSで構築するデータレイク基盤と amazon.comでの導入事例
2.
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved. ⾃⼰紹介 • 北村 聖児 • Amazon Web Service Japan K.K. • Solution Architect • Media & Entertainment • 前職 • Server Side Engineer • 好きなAWSサービス • Amazon Connect
3.
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved. 本⽇お伝えしたいこと • データレイクとは • AWSで構築するデータレイクのアーキテクチャ • Amazonでのデータレイク事例
4.
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved. データレイクとは
5.
© 2019, Amazon
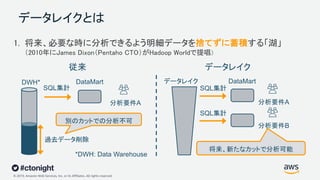
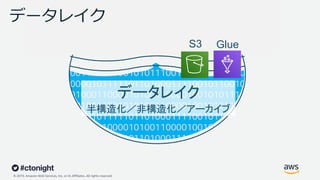
Web Services, Inc. or its Affiliates. All rights reserved. データレイクとは 1. 将来、必要な時に分析できるよう明細データを捨てずに蓄積する「湖」 (2010年にJames Dixon(Pentaho CTO)がHadoop Worldで提唱) 分析要件A 別のカットでの分析不可 分析要件A 分析要件B 将来、新たなカットで分析可能
6.
© 2019, Amazon
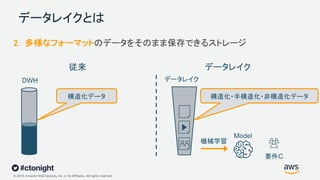
Web Services, Inc. or its Affiliates. All rights reserved. データレイクとは 2. 多様なフォーマットのデータをそのまま保存できるストレージ 構造化・半構造化・非構造化データ構造化データ 要件C
7.
© 2019, Amazon
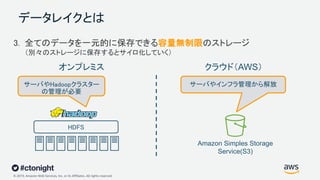
Web Services, Inc. or its Affiliates. All rights reserved. データレイクとは 3. 全てのデータを一元的に保存できる容量無制限のストレージ (別々のストレージに保存するとサイロ化していく) HDFS サーバやHadoopクラスター の管理が必要 Amazon Simples Storage Service(S3) サーバやインフラ管理から解放
8.
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved. ゴミ溜めになるのではないか? • データと共にメタデータを登録しないと後で活用できない • DWH でデータ・ディクショナリがないと分析できないのと同じ 出典:https://www.amazon.co.jp/Data-Lake-Architecture-Designing-Avoiding/dp/1634621174
9.
© 2019, Amazon
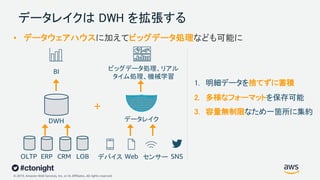
Web Services, Inc. or its Affiliates. All rights reserved. データレイクは DWH を拡張する • データウェアハウスに加えてビッグデータ処理なども可能に 1. 明細データを捨てずに蓄積 2. 多様なフォーマットを保存可能 3. 容量無制限なため一箇所に集約 DWH BI OLTP ERP CRM LOB SNSデバイス Web センサー ビッグデータ処理、リアル タイム処理、機械学習 データレイク +
10.
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved. AWSで構築するデータレイクの アーキテクチャ
11.
© 2019, Amazon
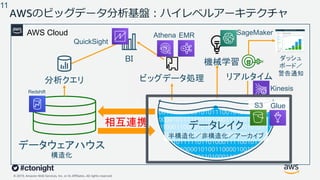
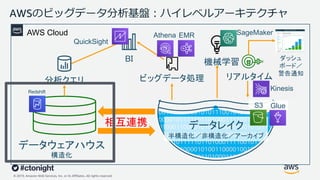
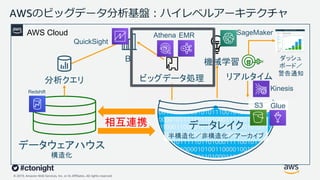
Web Services, Inc. or its Affiliates. All rights reserved. データレイク 半構造化/非構造化/アーカイブ AWSのビッグデータ分析基盤︓ハイレベルアーキテクチャ BI 機械学習 分析クエリ ビッグデータ処理 リアルタイム ダッシュ ボード/ 警告通知 AWS Cloud 相互連携 11 Redshift QuickSight EMR SageMaker Kinesis GlueS3 Athena データウェアハウス 構造化
12.
© 2019, Amazon
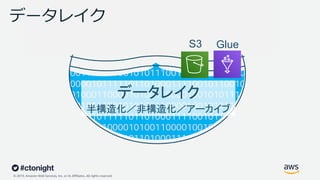
Web Services, Inc. or its Affiliates. All rights reserved. データレイク 半構造化/非構造化/アーカイブ データレイク GlueS3
13.
© 2019, Amazon
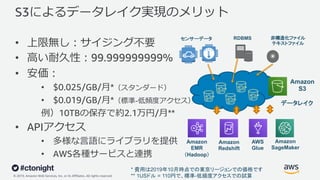
Web Services, Inc. or its Affiliates. All rights reserved. S3によるデータレイク実現のメリット • 上限無し︓サイジング不要 • ⾼い耐久性︓99.999999999% • 安価︓ • $0.025/GB/⽉*(スタンダード) • $0.019/GB/⽉*(標準-低頻度アクセス) 例)10TBの保存で約2.1万円/⽉** • APIアクセス • 多様な⾔語にライブラリを提供 • AWS各種サービスと連携 データレイク Amazon EMR (Hadoop) Amazon Redshift AWS Glue Amazon S3 センサーデータ 非構造化ファイル テキストファイル RDBMS * 費用は2019年10月時点での東京リージョンでの価格です ** 1USドル = 110円で、標準-低頻度アクセスでの試算 Amazon SageMaker
14.
© 2019, Amazon
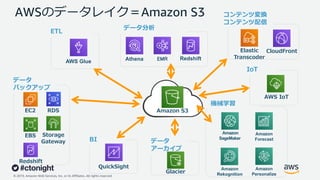
Web Services, Inc. or its Affiliates. All rights reserved. Amazon S3 データ分析 EMR Redshift データ バックアップ EC2 RDS Storage Gateway EBS Redshift ETL CloudFront コンテンツ変換 コンテンツ配信 Elastic Transcoder データ アーカイブ Glacier AWSのデータレイク=Amazon S3 Athena Amazon Forecast Amazon Personalize Amazon Rekognition Amazon SageMaker 機械学習 IoT AWS IoT BI QuickSight AWS Glue
15.
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved. データレイク 半構造化/非構造化/アーカイブ データレイク GlueS3
16.
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved. AWS GlueデータレイクのデータカタログとETL処理 データ カタログ § AWS Glue データカタログ︓Redshift Spectrum, Athena, EMRからS3上の半構造データにアクセスする場合 のデータカタログとして利⽤・連携可能 § AWS Glue ETL︓分散処理でETLジョブを⾏うフルマネー ジドでサーバーレスなサービス。コストは利⽤したリソー ス分だけの⽀払い ETL処理 16 データカタログとは︓データの構造(列、型など)やアクセス ⽅法を定義してあり検索などが可能 ETL処理とは︓複数のデータストア間でデータ連携する際の 取出し(Extract)、変換(Transform)、ロード(Load) 処理
17.
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved. AWS Glue データカタログ テーブル構造をHiveメタストア互換 の形式で管理 • 列・プロパティ・型 • データロケーション(S3のパス) • 更新情報 等 クローラーによる自動スキーマ推論 とデータカタログ登録 • Hiveパーティションを認識し登録を自 動化 /mydata /year=2017 /month=11/... 17/month=12/...
18.
© 2019, Amazon
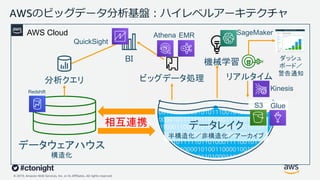
Web Services, Inc. or its Affiliates. All rights reserved. データレイク 半構造化/非構造化/アーカイブ AWSのビッグデータ分析基盤︓ハイレベルアーキテクチャ BI 機械学習 分析クエリ ビッグデータ処理 リアルタイム ダッシュ ボード/ 警告通知 AWS Cloud 相互連携 Redshift QuickSight EMR SageMaker Kinesis GlueS3 Athena データウェアハウス 構造化
19.
© 2019, Amazon
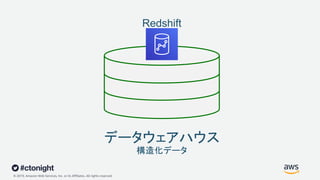
Web Services, Inc. or its Affiliates. All rights reserved. データウェアハウス 構造化データ Redshift
20.
© 2019, Amazon
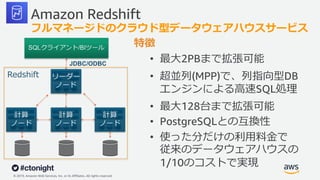
Web Services, Inc. or its Affiliates. All rights reserved. Amazon Redshift 特徴 • 最⼤2PBまで拡張可能 • 超並列(MPP)で、列指向型DB エンジンによる⾼速SQL処理 • 最⼤128台まで拡張可能 • PostgreSQLとの互換性 • 使った分だけの利⽤料⾦で 従来のデータウェアハウスの 1/10のコストで実現 フルマネージドのクラウド型データウェアハウスサービス JDBC/ODBC Redshift
21.
© 2019, Amazon
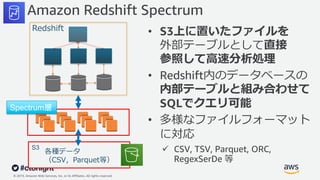
Web Services, Inc. or its Affiliates. All rights reserved. Amazon Redshift Spectrum • S3上に置いたファイルを 外部テーブルとして直接 参照して⾼速分析処理 • Redshift内のデータベースの 内部テーブルと組み合わせて SQLでクエリ可能 • 多様なファイルフォーマット に対応 ü CSV, TSV, Parquet, ORC, RegexSerDe 等 S3 各種データ (CSV,Parquet等) Spectrum層 Redshift
22.
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved. データレイク 半構造化/非構造化/アーカイブ AWSのビッグデータ分析基盤︓ハイレベルアーキテクチャ BI 機械学習 分析クエリ ビッグデータ処理 リアルタイム ダッシュ ボード/ 警告通知 AWS Cloud 相互連携 Redshift QuickSight EMR SageMaker Kinesis GlueS3 Athena データウェアハウス 構造化
23.
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved. データレイク ビッグデータ処理 Athena EMR
24.
© 2019, Amazon
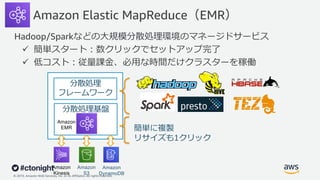
Web Services, Inc. or its Affiliates. All rights reserved. Amazon Elastic MapReduce(EMR) Hadoop/Sparkなどの⼤規模分散処理環境のマネージドサービス ü 簡単スタート︓数クリックでセットアップ完了 ü 低コスト︓従量課⾦、必⽤な時間だけクラスターを稼働 分散処理 フレームワーク 分散処理基盤 簡単に複製 リサイズも1クリック Amazon S3 Amazon DynamoDB Amazon Kinesis Amazon EMR
25.
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved. EMRFS: S3をHDFSの様に扱う “s3://” と指定するだけでHDFSと同様にS3にアクセス • 計算ノードとストレージを分離できる ü コスト⾯でもメリット⼤ • クラスタのシャットダウンが可能 ü クラスタを消してもデータをロストしない • 複数クラスタ間でデータ共有が簡単 • データの⾼い耐久性(S3) EMR EMR データレイクに直接並列でアクセスすることが可能 Amazon S3
26.
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved. Amazon Athena • S3上のファイルにSQLを実⾏可能 • PrestoベースでANSI SQL対応 • サーバ管理、データロード不要 • ⾃動で並列クエリ実⾏ • 結果はコンソールにストリーム (動的更新) • 結果はS3にも保存 • スキャンしたデータ量に対する課⾦ • JDBC/ODBC経由でBIツールから 可視化 S3に保存したファイルをサーバーレスでインタラクティブに直接クエリ 26
27.
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved. データレイク 半構造化/非構造化/アーカイブ AWSのビッグデータ分析基盤︓ハイレベルアーキテクチャ BI 機械学習 分析クエリ ビッグデータ処理 リアルタイム ダッシュ ボード/ 警告通知 AWS Cloud 相互連携 Redshift QuickSight EMR SageMaker Kinesis GlueS3 Athena データウェアハウス 構造化
28.
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved. データレイクの代表的なユースケース
29.
© 2019, Amazon
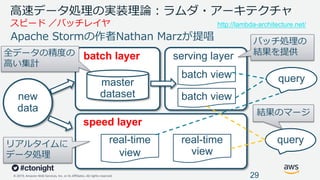
Web Services, Inc. or its Affiliates. All rights reserved. ⾼速データ処理の実装理論︓ラムダ・アーキテクチャ スピード /バッチレイヤ 29 http://lambda-architecture.net/ new data batch layer speed layer master dataset real-time view real-time view serving layer batch view batch view query query 全データの精度の ⾼い集計 リアルタイムに データ処理 結果のマージ バッチ処理の 結果を提供
30.
© 2019, Amazon
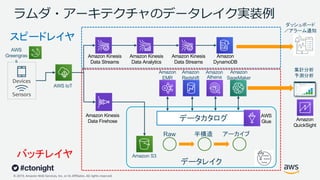
Web Services, Inc. or its Affiliates. All rights reserved. ラムダ・アーキテクチャのデータレイク実装例 Amazon S3 Amazon DynamoDB Devices Sensors AWS IoT Amazon Kinesis Data Streams AWS Greengras s Amazon Kinesis Data Firehose Amazon Kinesis Data Analytics Amazon Kinesis Data Streams データレイク AWS Glue Amazon EMR Amazon Redshift Amazon Athena Amazon SageMaker スピードレイヤ バッチレイヤ Amazon QuickSight
31.
© 2019, Amazon
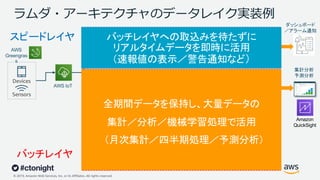
Web Services, Inc. or its Affiliates. All rights reserved. ラムダ・アーキテクチャのデータレイク実装例 Amazon S3 Amazon DynamoDB Devices Sensors AWS IoT Amazon Kinesis Data Streams AWS Greengras s Amazon Kinesis Data Firehose Amazon Kinesis Data Analytics Amazon Kinesis Data Streams データレイク AWS Glue Amazon EMR Amazon Redshift Amazon Athena Amazon SageMaker スピードレイヤ バッチレイヤ Amazon QuickSight バッチレイヤへの取込みを待たずに リアルタイムデータを即時に活用 (速報値の表示/警告通知など)
32.
© 2019, Amazon
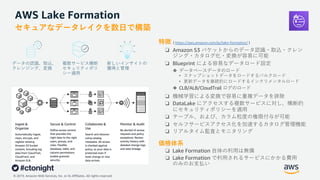
Web Services, Inc. or its Affiliates. All rights reserved. セキュアなデータレイクを数⽇で構築 特徴 ( https://aws.amazon.com/jp/lake-formation/ ) ❏ Amazon S3 バケットからのデータ認識・取込・クレン ジング・カタログ化・変換が容易に可能 ❏ Blueprint による容易なデータロード設定 ❖ データベースデータのロード • スナップショットデータをロードするバルクロード • 更新データを継続的にロードするインクリメンタルロード ❖ CLB/ALB/CloudTrail ログのロード ❏ 機械学習による変換で容易に重複データを排除 ❏ DataLake にアクセスする複数サービスに対し、横断的 にセキュリティポリシーを適⽤ ❏ テーブル、および、カラム粒度の権限付与が可能 ❏ セルフサービスアクセス化を加速するカタログ管理機能 ❏ リアルタイム監査とモニタリング 価格体系 ❏ Lake Formation ⾃体の利⽤は無償 ❏ Lake Formation で利⽤されるサービスにかかる費⽤ のみのお⽀払い 新しいインサイトの 獲得と管理 複数サービス横断 セキュリティポリ シー適⽤ データの認識、取込、 クレンジング、変換 AWS Lake Formation
33.
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved. Amazonのデータレイク事例
34.
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved. Amazon のビジネスとデータ活用 Amazon Data Warehouse • Amazon はグローバルに様々なビジネスを展開 • そこから生まれる大量のデータを分析してビジネス判断
35.
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved. 多様な分析要件と大きなワークロード 80,000 ユーザー 900,000 ジョブ/日 38,000 のデータセット分析ユーザーとユース ケースは多種多様
36.
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved. Amazon のデータウェアハウスの課題
37.
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved. “Andes” –データレイク・プロジェクト– • Amazonの成長に合わせて 拡張可能なエコシステムを 提供 • オープンなシステムアーキ テクチャで、多様なデータ 分析の選択肢を提供 • AWSを利用してフィードバ ック、サービス改善に貢献
38.
© 2019, Amazon
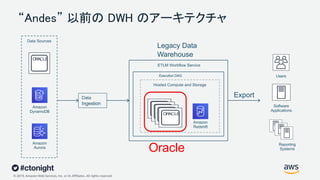
Web Services, Inc. or its Affiliates. All rights reserved. “Andes” 以前の DWH のアーキテクチャ Legacy Data Warehouse ETLM Workflow Service Export Hosted Compute and Storage Execution DAG Data Ingestion Data Sources Users Reporting Systems Software Applications Amazon DynamoDB Amazon Aurora Amazon Redshift Oracle
39.
© 2019, Amazon
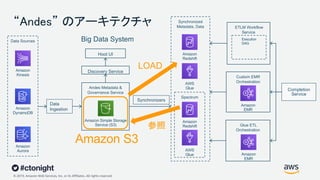
Web Services, Inc. or its Affiliates. All rights reserved. “Andes” のアーキテクチャ Synchronized Metadata, Data Amazon Redshift Amazon Redshift AWS Glue AWS Glue Amazon Aurora Amazon DynamoDB Big Data System Discovery Service Synchronizers ETLM Workflow Service Execution DAG Data Ingestion Hoot UI Data Sources Glue ETL Orchestration Spectrum Andes Metadata & Governance Service Completion Service Custom EMR Orchestration Amazon Kinesis Amazon Simple Storage Service (S3) Amazon EMR Amazon EMR Amazon S3 LOAD 参照
40.
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved. “Andes” 完成(2018年1月移行完了) • PBクラスの DWH を AWS に移行 • DWH に加えてビッグデータ処理も可能に 動画:https://www.youtube.com/watch?v=PitJL9vOotc スライド:https://www.slideshare.net/AmazonWebServices/under-the-hood-how-amazon-uses-aws-services-for-analytics-at-a-massive-scale-ant206-aws-reinvent-2018
41.
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved. • 収集と後続処理が分離され、収集側がデータレイクにデータを 置くだけで良い構成 • セルフサービスを促進するために「発⾒」「登録」層を導⼊ セルフサービスを実現するための仕組み 収集 蓄積 データ レイク 分析 可視化・ 応⽤ 発⾒ 登録 Discover Subscribe セルフサービス化
42.
© 2019, Amazon
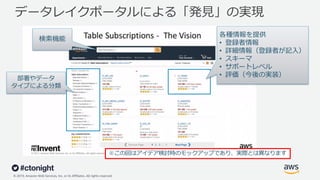
Web Services, Inc. or its Affiliates. All rights reserved. データレイクポータルによる「発⾒」の実現 各種情報を提供 • 登録者情報 • 詳細情報(登録者が記⼊) • スキーマ • サポートレベル • 評価(今後の実装) 部署やデータ タイプによる分類 検索機能 ※この図はアイデア検討時のモックアップであり、実際とは異なります
43.
© 2019, Amazon
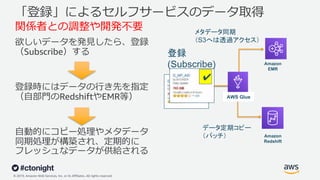
Web Services, Inc. or its Affiliates. All rights reserved. ✔ 「登録」によるセルフサービスのデータ取得 関係者との調整や開発不要 欲しいデータを発⾒したら、登録 (Subscribe)する 登録時にはデータの⾏き先を指定 (⾃部⾨のRedshiftやEMR等) ⾃動的にコピー処理やメタデータ 同期処理が構築され、定期的に フレッシュなデータが供給される ✔ 登録 (Subscribe) Amazon Redshift Amazon EMR データ定期コピー (バッチ) メタデータ同期 (S3へは透過アクセス) AWS Glue
44.
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved. 「登録」モデルの実現とその効果 ユーザ調整が可能な設計 • 必要なデータ範囲や頻度を設定可能 • 独⾃のクエリを登録して、データ連携の タイミングで⾃動実⾏ ⾃動的なバリデーション(表⾏数チェック、 スキーマチェック等) 誰が何を使っているか把握できるため、データの 削除や変更時にも影響範囲が把握できるという 効果あり INSERT INTO .. SELECT ... User Query When ... ▼After data copy ID = ABC and ... Where Timing ▼ Once a day : 3AM
45.
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved. ⾮常に多くのお客様がデータレイク基盤をAWSに構築 10,000以上のデータレイクがAWS上で稼働
46.
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved. AWS Data Lake ハンズオンセミナーのご紹介 参考:https://aws.amazon.com/jp/blogs/news/20190405-aws-datalake-handson-seminor/ • 目黒の AWS Japan オフィスで不定期開催(無償セミナー) • 2018年から過去9回開催、参加者は100名程度 • イベント開催予定:https://aws.amazon.com/jp/about-aws/events/
47.
© 2019, Amazon
Web Services, Inc. or its Affiliates. All rights reserved. Thank you!
Download


























![[20220126] JAWS-UG 2022初頭までに葬ったAWSアンチパターン大紹介](https://cdn.slidesharecdn.com/ss_thumbnails/20220126-anti-220126190603-thumbnail.jpg?width=640&height=640&fit=bounds)





















![[AWS EXpert Online for JAWS-UG 18] 見せてやるよ、Step Functions の本気ってやつをな](https://cdn.slidesharecdn.com/ss_thumbnails/awsxon18howfarstepfunctionsgo-211124111849-thumbnail.jpg?width=640&height=640&fit=bounds)










































