2018/10/5 に開催された Analytics Architecture Night - Tokyo の発表資料です https://analyticsarchitecturenighttoky.splashthat.com/





















































![© 2018, Amazon Web Services, Inc. or its Affiliates. All rights reserved.
62
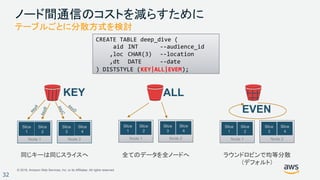
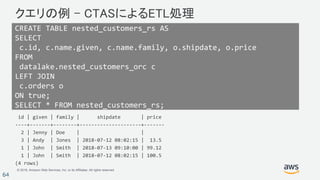
ORC ネスト化されたデータを使ったサンプル
{ Id: 1,
Name: {Given:"John", Family:"Smith"},
Phones: ["123-457789"],
Orders: [ {Shipdate: ”Jul 12,2018 11:59:59",
Price: 100.50}
{Shipdate: ”Jul 13,2018 09:10:00",
Price: 99.12} ]
}
{ Id: 2,
Name: {Given:"Jenny", Family:"Doe"},
Phones: ["858-8675309", "415-9876543"],
Orders: [ ]
}
{ Id: 3,
Name: {Given:"Andy", Family:"Jones"},
Phones: [ ]
Orders: [ {Shipdate: ”Jul 12,2018 08:02:15",
Price: 13.50} ]
}
create external table
datalake.nested_customers_orc(
id int,
name struct<given:varchar(20),
family:varchar(20)>,
phones array<varchar(20)>,
orders array<struct
<shipdate:timestamp,
price:double precision>>
)
STORED AS ORC
LOCATION 's3://mybucket/nested_orc/'
;
ORC データの構造 DDL](https://image.slidesharecdn.com/analyticsarchitecturenight-tokyo201810-redshift-181005125035/85/Amazon-Redshift-62-320.jpg)






![AWS Loft のイベントにご参加ください! #awsloft
9 (火) 18:30~ Machine Learning Night amzn.to/lofttokyo20181009
10 (水) 19:00~ AWS Startup Tech Meetup amzn.to/lofttokyo20181010
16 (火) 14:00~ UB Ventures 竹内氏による amzn.to/lofttokyo20181016
Startup Office Hour
19 (金) 19:00~ Amazon Tech Meetup #01 amzn.to/lofttokyo20181019
~Amazon Pay スペシャル!~
25 (木) 18:30~ [AWS Start-upゼミ] amzn.to/lofttokyo20181025
2018 秋季講習 秋のデモ祭り
26 (金) 18:00~ Code Happy Hour! amzn.to/lofttokyo20181026](https://image.slidesharecdn.com/analyticsarchitecturenight-tokyo201810-redshift-181005125035/85/Amazon-Redshift-71-320.jpg)




















![[AWS EXpert Online for JAWS-UG 18] 見せてやるよ、Step Functions の本気ってやつをな](https://cdn.slidesharecdn.com/ss_thumbnails/awsxon18howfarstepfunctionsgo-211124111849-thumbnail.jpg?width=640&height=640&fit=bounds)















![[AWSマイスターシリーズ] Amazon Redshift](https://cdn.slidesharecdn.com/ss_thumbnails/20130716aws-meister-regenerate-redshiftpublic-130719022907-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)








![[CTC Forum 2019/10/25] 事例から学ぶ!AWS 移行でデータベースの管理・コストを削減する方法](https://cdn.slidesharecdn.com/ss_thumbnails/ctcforum20191025learnfromexamplesawsmigrationmethodtoreducedatabasemanagementandcost-191107204532-thumbnail.jpg?width=640&height=640&fit=bounds)






![[20220126] JAWS-UG 2022初頭までに葬ったAWSアンチパターン大紹介](https://cdn.slidesharecdn.com/ss_thumbnails/20220126-anti-220126190603-thumbnail.jpg?width=640&height=640&fit=bounds)





























