Download to read offline










![Conclusion and Future work
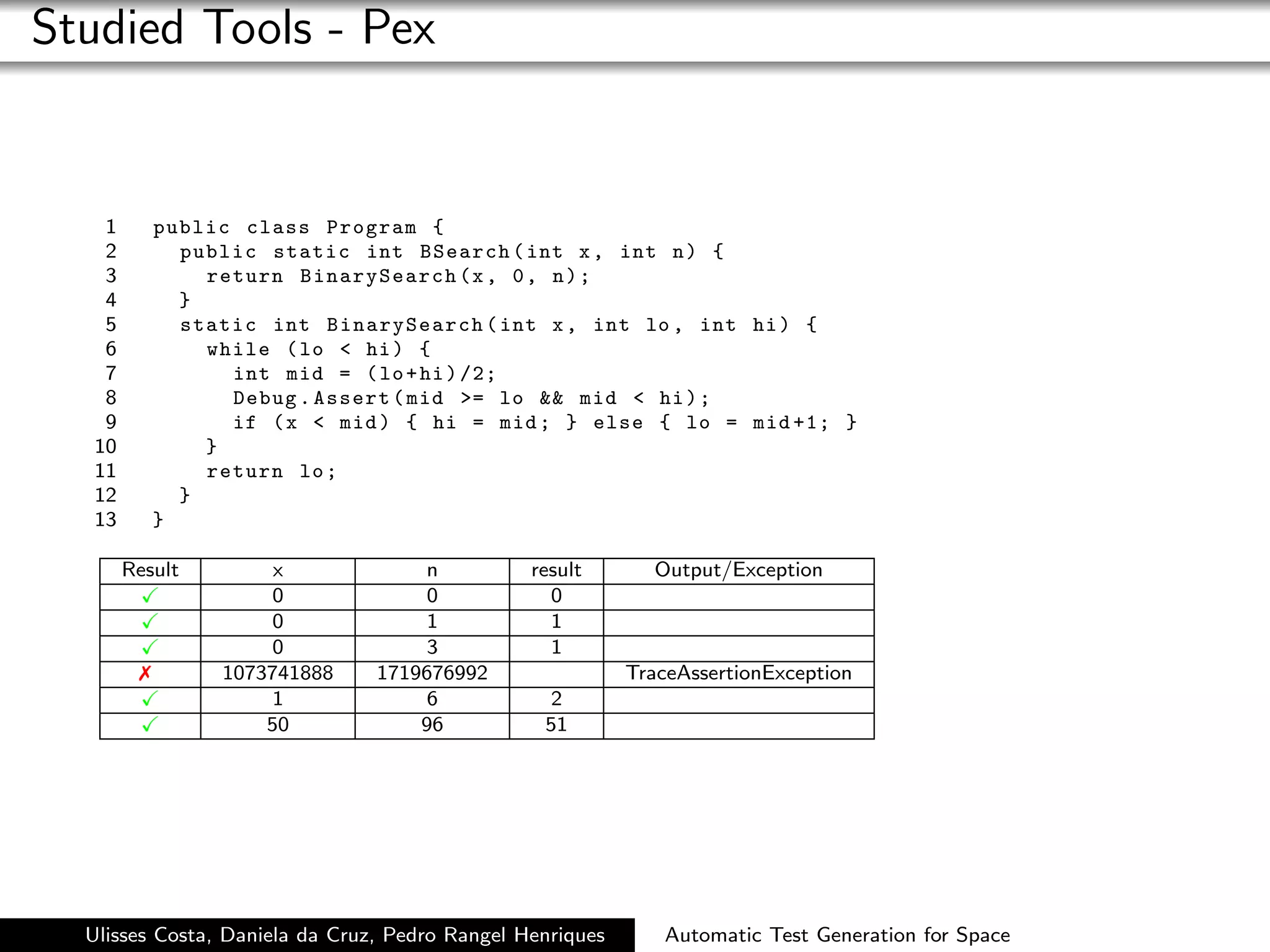
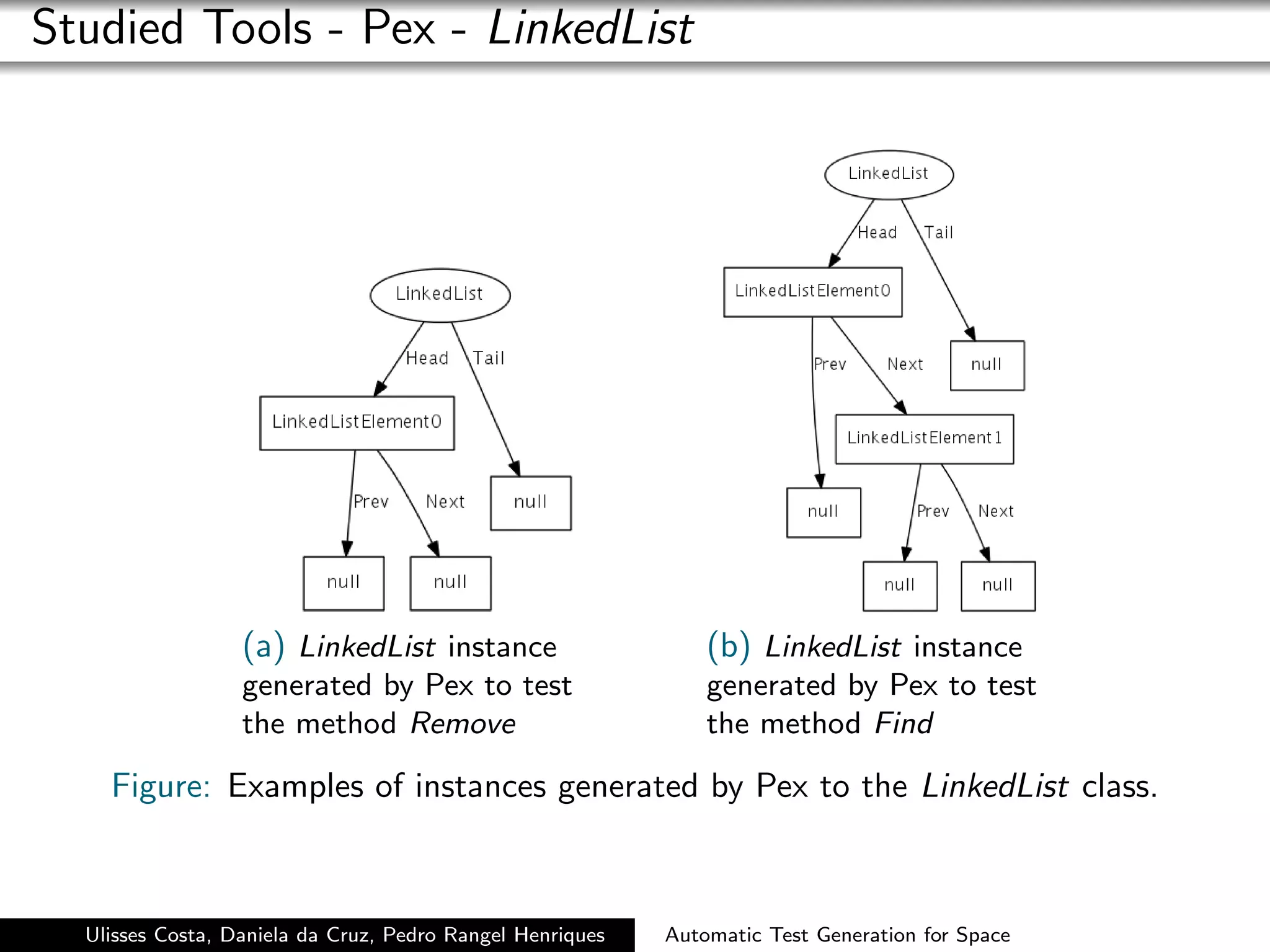
Pex has proved to be a powerful tool regarding full coverage.
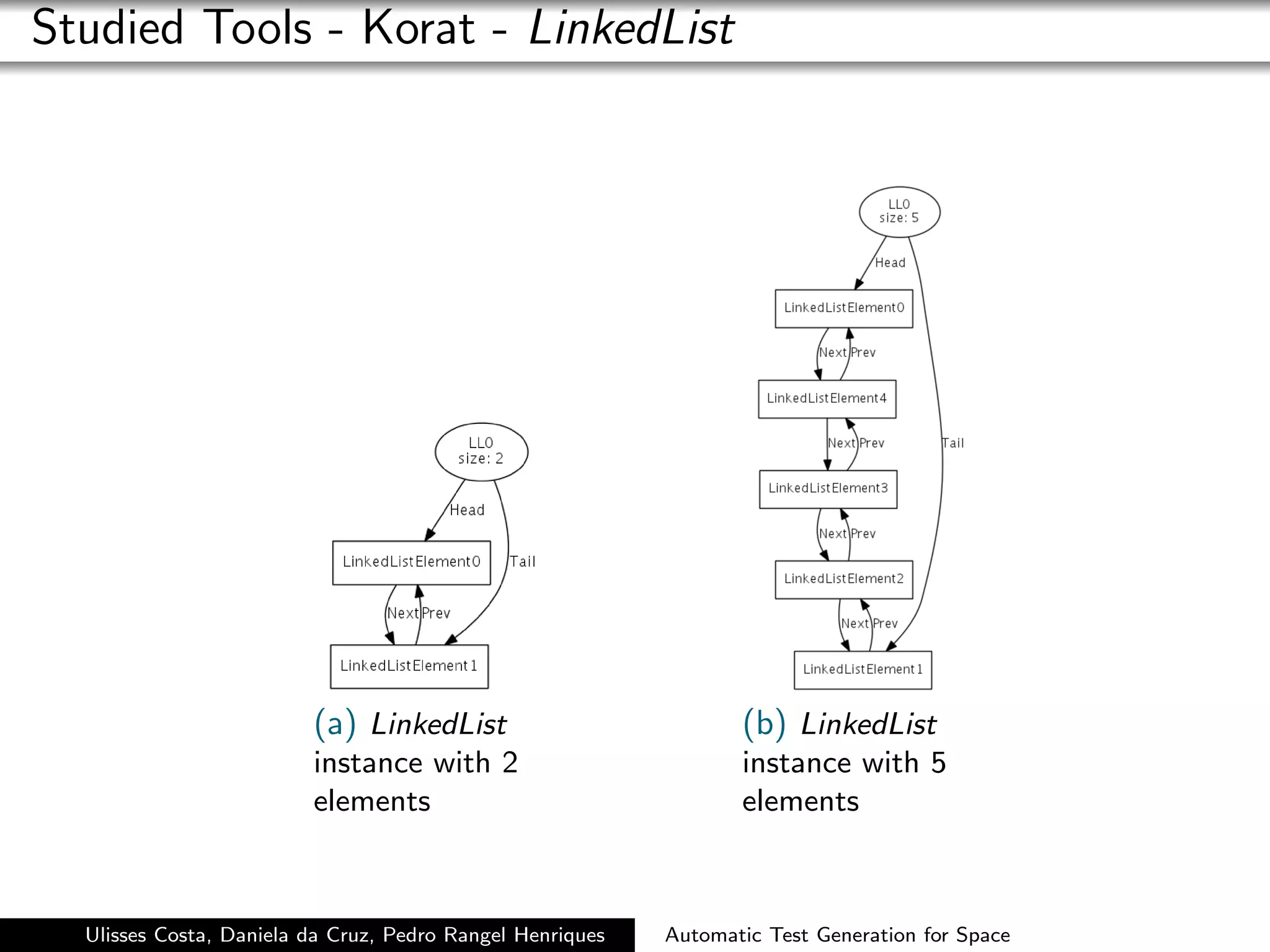
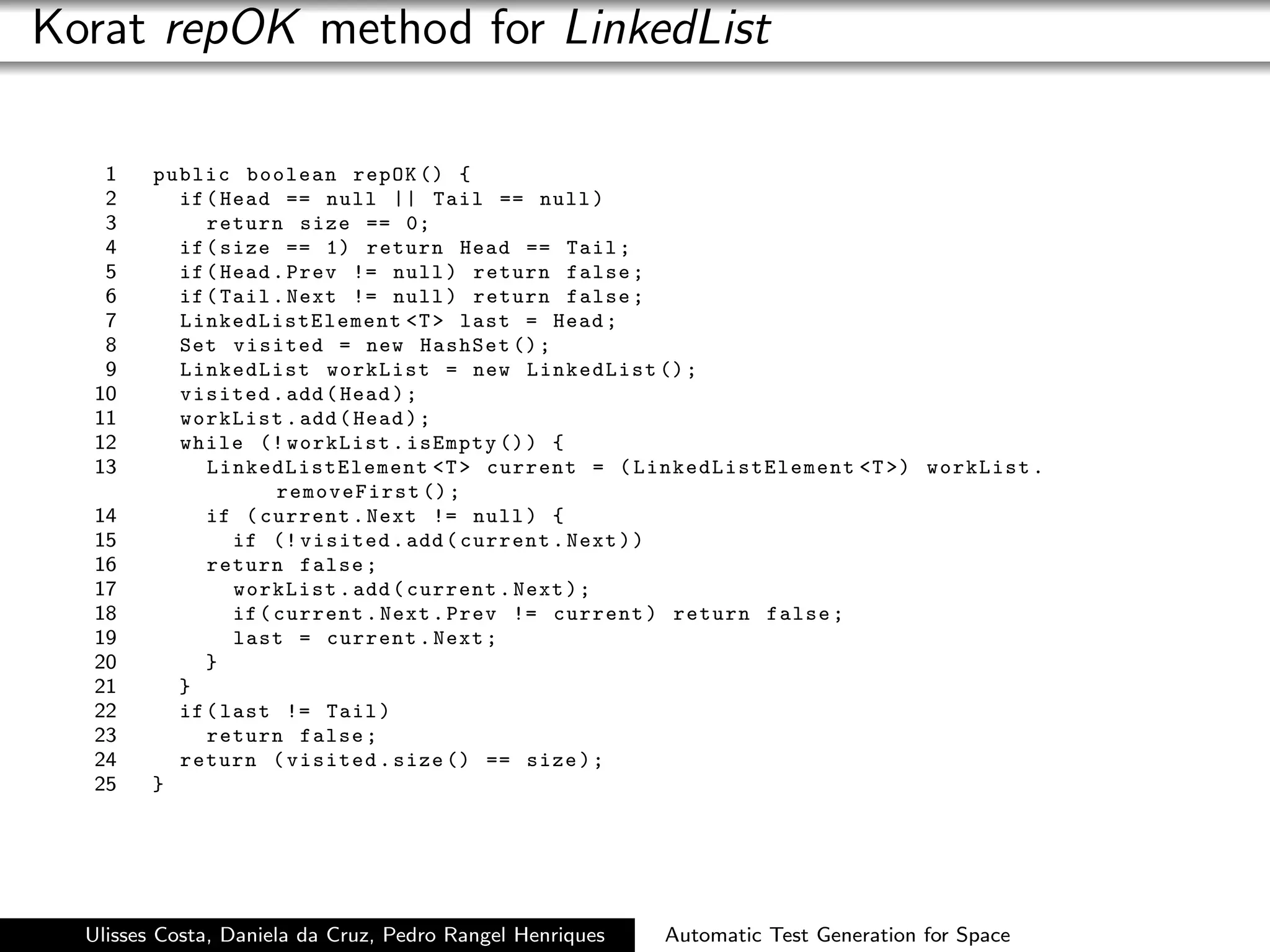
Korat is a very useful tool to generate complex data
structures.
A mix between the static analysis of Pex with Korat’s capability to
generate useful data structures is the path we will follow.
The study of pre- pos conditions inference using static analysis
[Moy 2009] will be useful to infer OCL rules.
Ulisses Costa, Daniela da Cruz, Pedro Rangel Henriques Automatic Test Generation for Space](https://image.slidesharecdn.com/slate12-ulisses-pres-120622174236-phpapp01/75/Automatic-Test-Generation-for-Space-14-2048.jpg)

The document discusses automatic test generation for space applications. It describes a master's thesis that aims to automatically generate tests for an operational simulator using model-based and constraint-based testing. The thesis will extract UML diagrams and invariants from existing code and relate them to requirements. Tools like Korat and Pex were studied, with Korat able to generate complex data structures that satisfy invariants, while Pex can achieve high code coverage but does not maintain data structure invariants. The work will combine static analysis and data structure generation to automatically test the operational simulator.















































































