Download as PDF, PPTX






























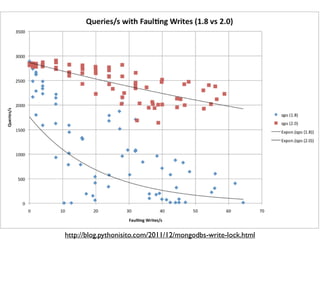
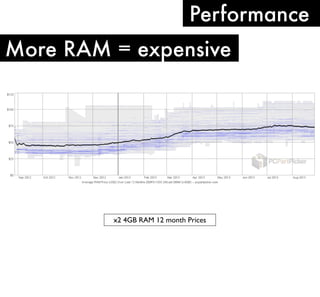



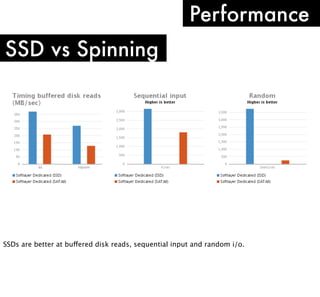
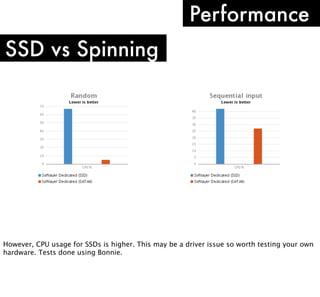






















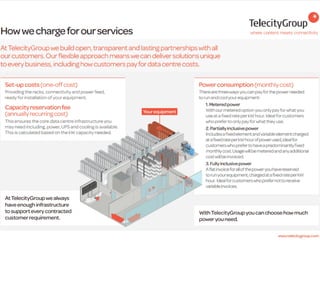






















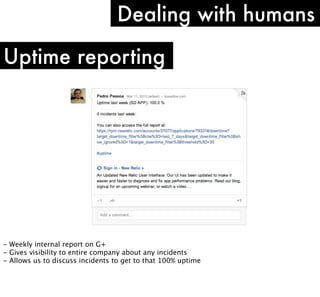









The document discusses high performance infrastructure for Server Density which includes 150 servers that have been running since June 2009 and migrated from MySQL to MongoDB. It stores 25TB of data per month. Key aspects of performance discussed are using fast networks like 10 Gigabit Ethernet on AWS, ensuring high memory, using SSDs over spinning disks for performance, and factors like replication lag based on location. The document also compares options like using cloud, dedicated servers, or colocation and discusses monitoring, backups, dealing with outages, and other operational aspects.
































![Oracle Open World 2014: Lies, Damned Lies, and I/O Statistics [ CON3671]](https://cdn.slidesharecdn.com/ss_thumbnails/thursday115ionfs-141107125307-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)


































