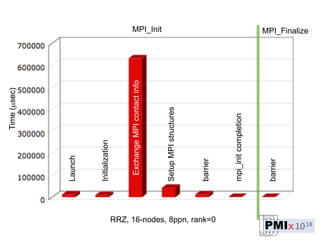
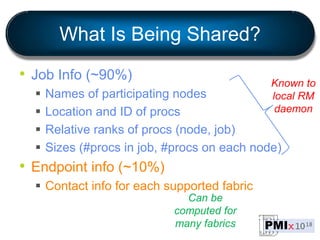
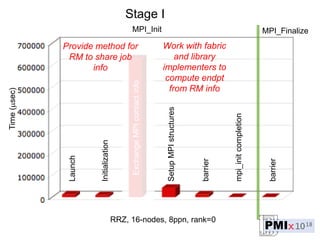
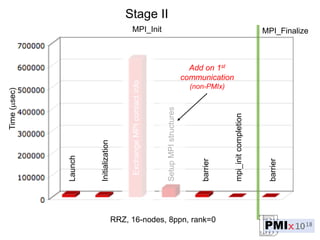
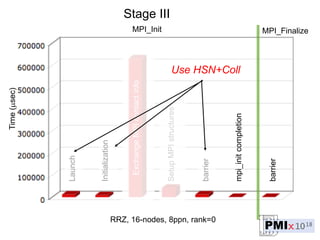
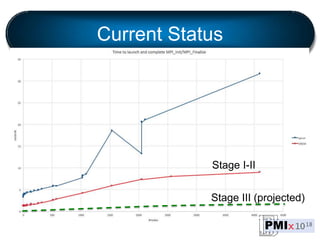
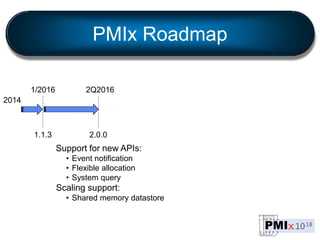
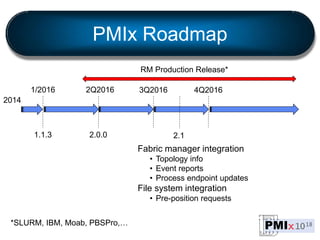
PMIx is an open source project led by several companies to develop a new process management interface for exascale systems. The goals are to reduce MPI initialization times from minutes to seconds for millions of processes, support new programming models, and enable "instant on" capabilities. Key areas of focus include launch scaling, flexible resource allocation, I/O support, fault tolerance, and workflow orchestration. The project aims to establish an independent community and provide standalone client/server libraries to ease adoption and support evolving requirements for exascale systems.