Downloaded 43 times


![Related Work
• Applications on computer vision
– Domain transfer + Generative Adversarial Networks
– This paper: a novel approach w/o generative models
• Training CNN for domain adaptation
– Matching hidden features
of different domains
[Long+, ICML 2015][Ganin+, ICML 2014]
Real faces to illusts [Taigman+, ICLR 2017] Artificial images to real images [Bousmalis+, CVPR 2017]
No Adapt AdaptedSource Target
Class A
Class B](https://image.slidesharecdn.com/icmlpresentationmiruushiku-170815102008/75/Asymmetric-Tri-training-for-Unsupervised-Domain-Adaptation-3-2048.jpg)
![Theorem [Ben David+, Machine Learning 2010]
•
– Related work: regard as being sufficiently small
• Distribution matching approaches aim to minimize
• There is no guarantee that is small enough
– Proposed method: minimizes by reducing error on target samples
• absence of labeled samples
→ We propose to give pseudo-labels to target samples
Theoretical Insight
How much features are discriminative
: Divergence between domains
Error on source domainError on target domain
?](https://image.slidesharecdn.com/icmlpresentationmiruushiku-170815102008/75/Asymmetric-Tri-training-for-Unsupervised-Domain-Adaptation-4-2048.jpg)
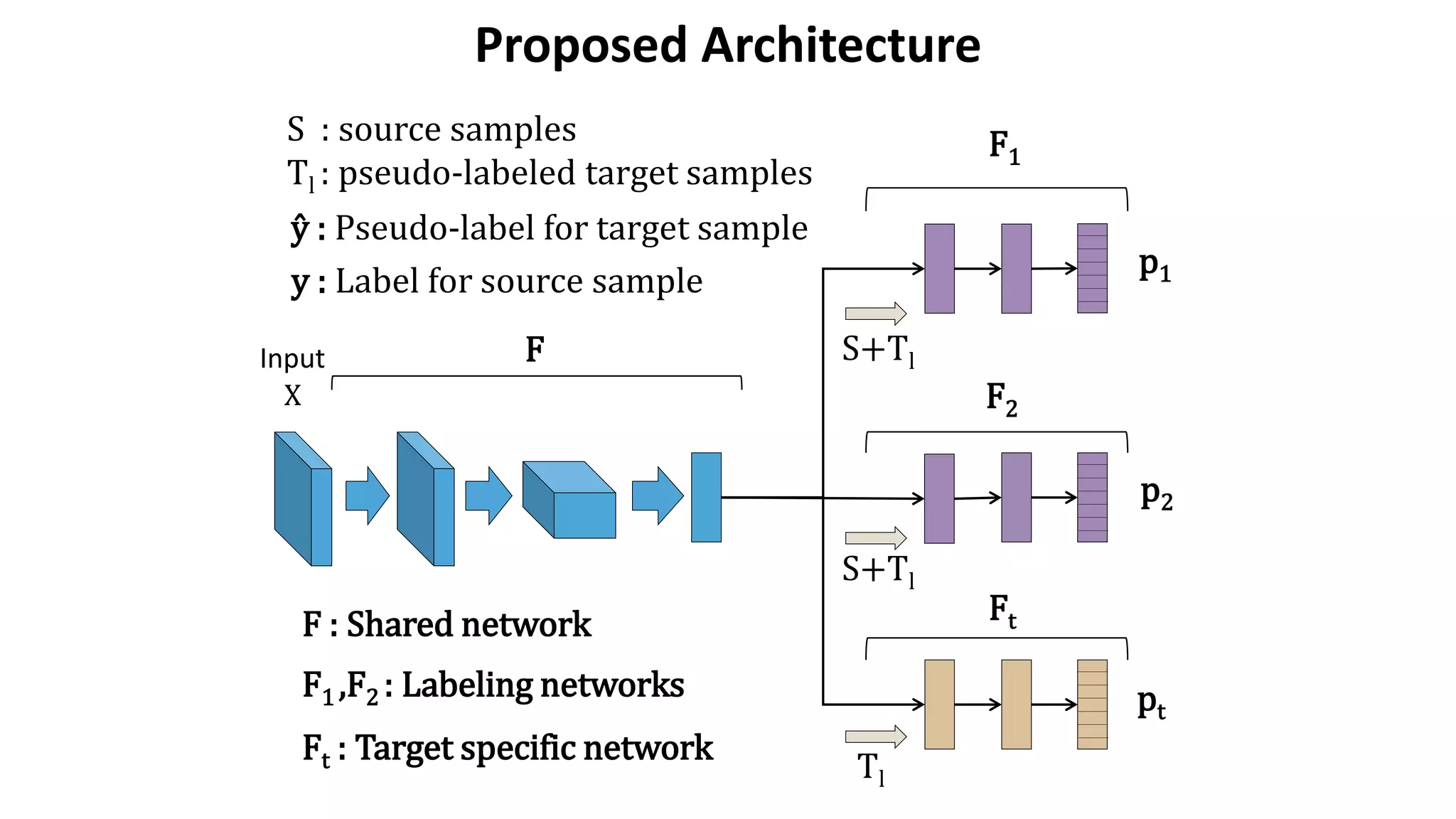
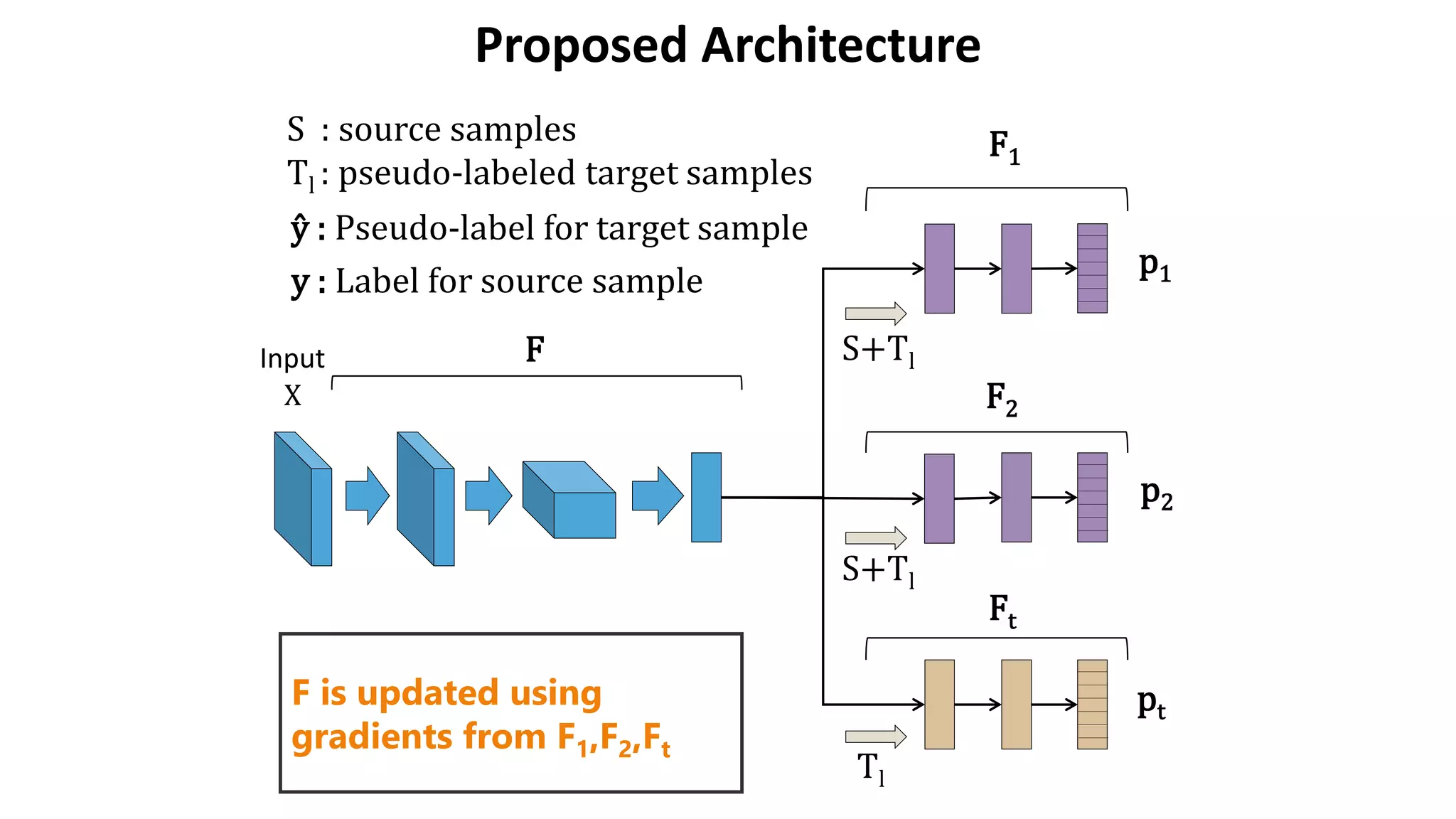
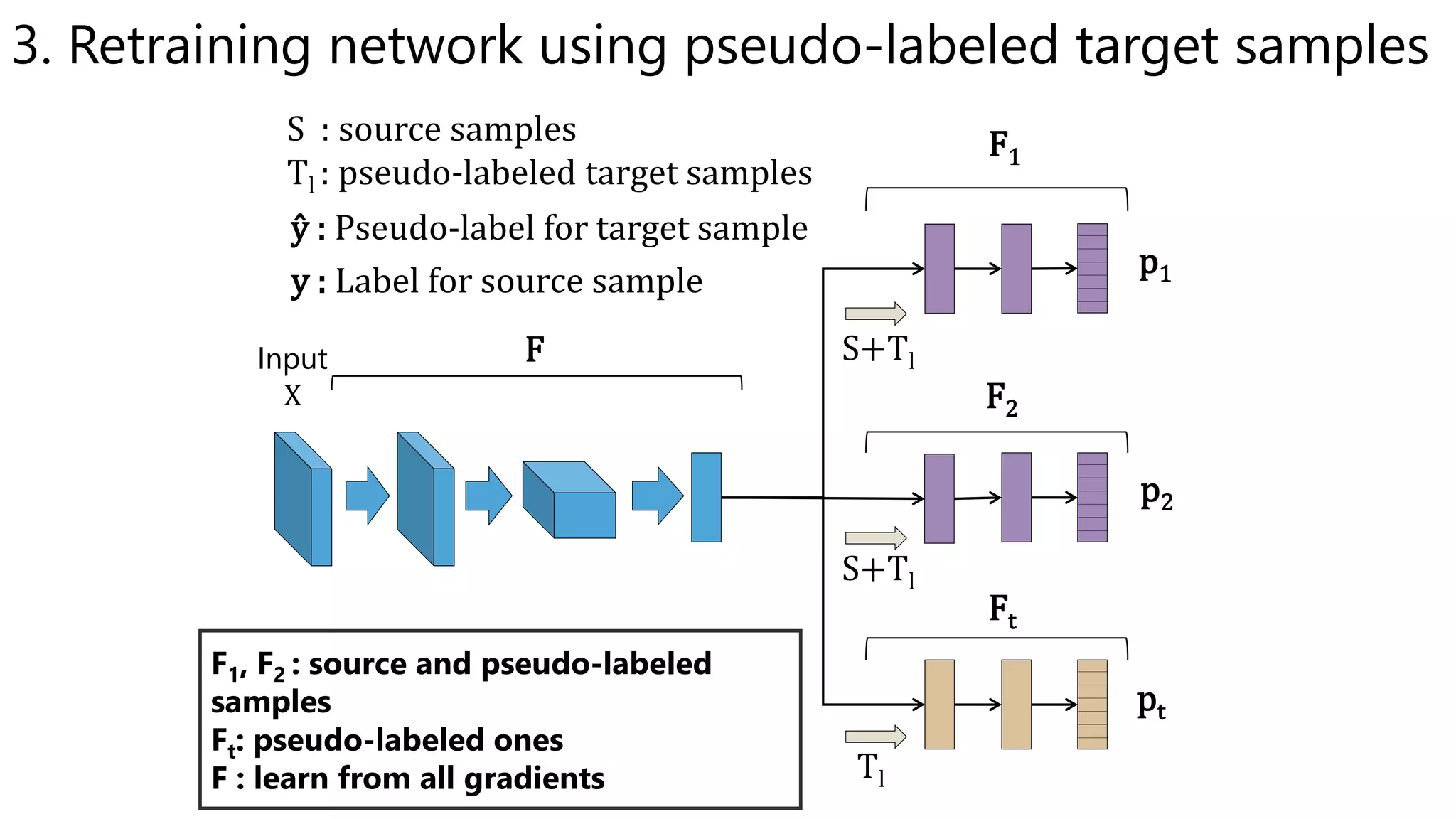
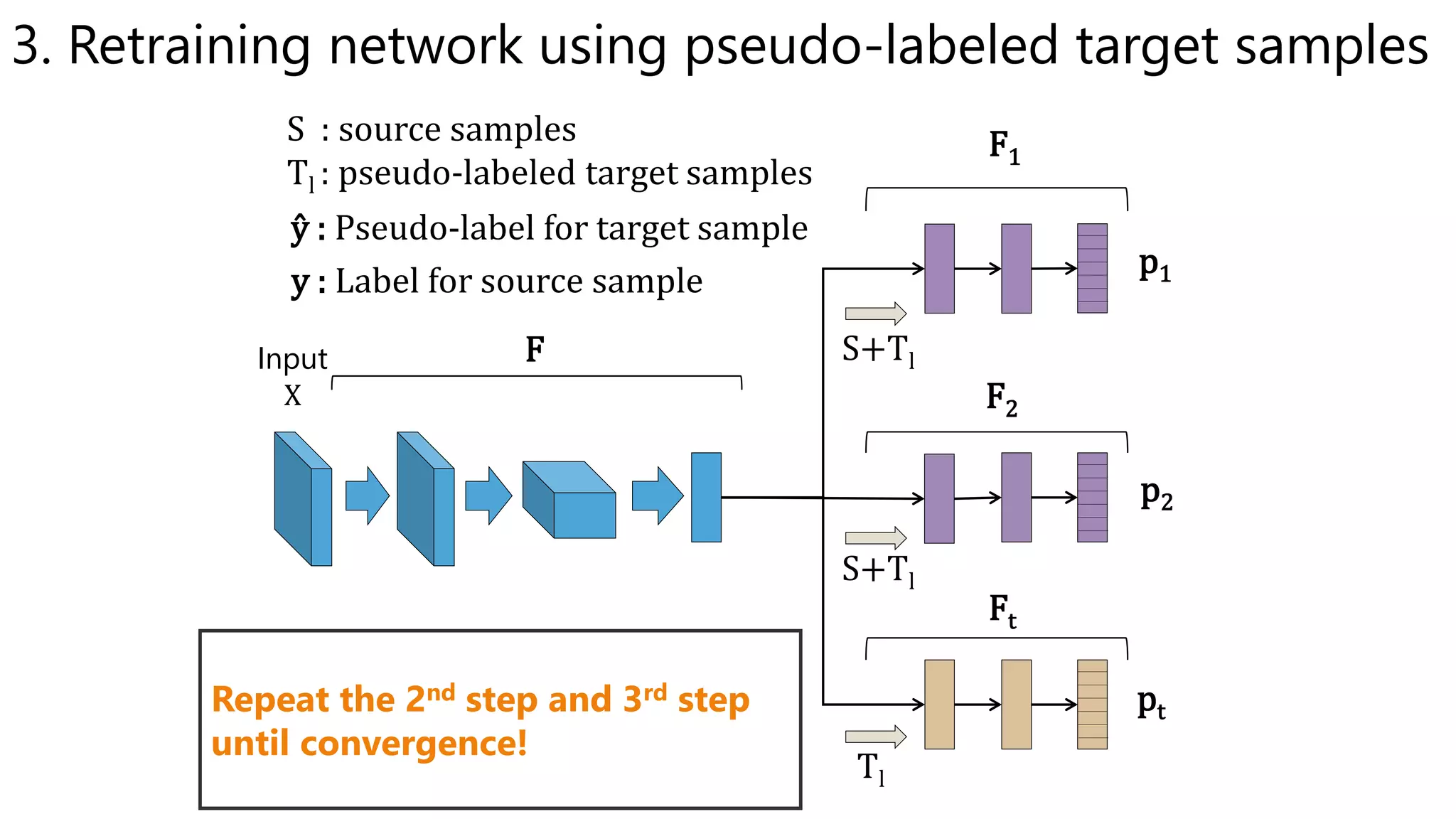
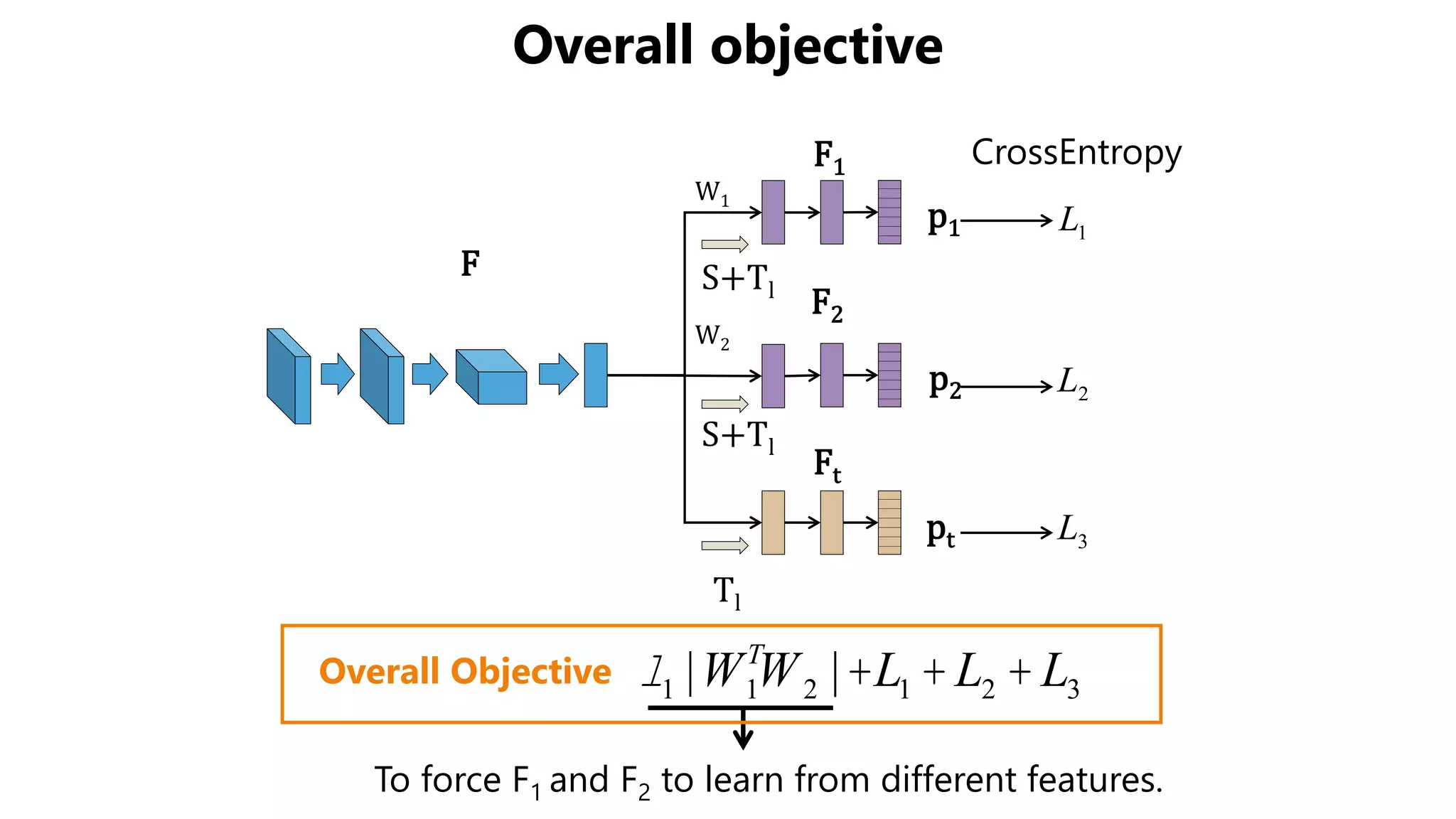

![Accuracy on Target Domain
• Our method outperformed other methods.
– The effect of BN is obvious in some settings.
– The effect of weight constraint is not obvious.
Source MNIST MNIST SVHN SYNDIG SYN NUM
Method Target MN-M SVHN MNIST SVHN GTSRB
Source Only (w/o BN) 59.1 37.2 68.1 84.1 79.2
Source Only (with BN) 57.1 34.9 70.1 85.5 75.7
DANN [Ganin et al., 2014] 81.5 35.7 71.1 90.3 88.7
MMD [Long et al., 2015 ICML] 76.9 - 71.1 88.0 91.1
DSN [Bousmalis et al, 2016 NIPS] 83.2 - 82.7 91.2 93.1
K-NN Labeling [Sener et al., 2016 NIPS] 86.7 40.3 78.8 - -
Ours (w/o BN) 85.3 39.8 79.8 93.1 96.2
Ours (w/o Weight constraint) 94.2 49.7 86.0 92.4 94.0
Ours 94.0 52.8 86.8 92.9 96.2](https://image.slidesharecdn.com/icmlpresentationmiruushiku-170815102008/75/Asymmetric-Tri-training-for-Unsupervised-Domain-Adaptation-13-2048.jpg)


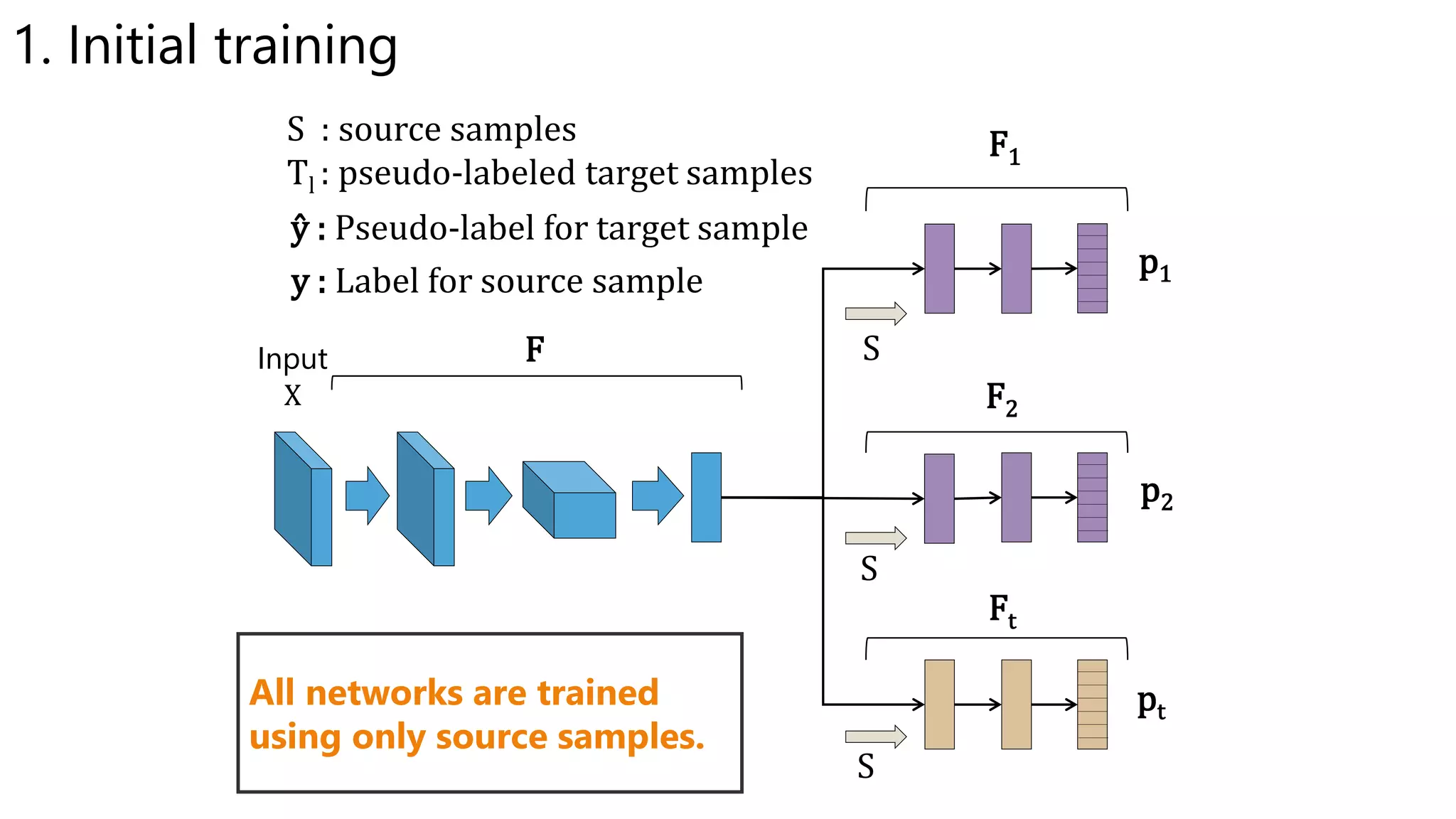
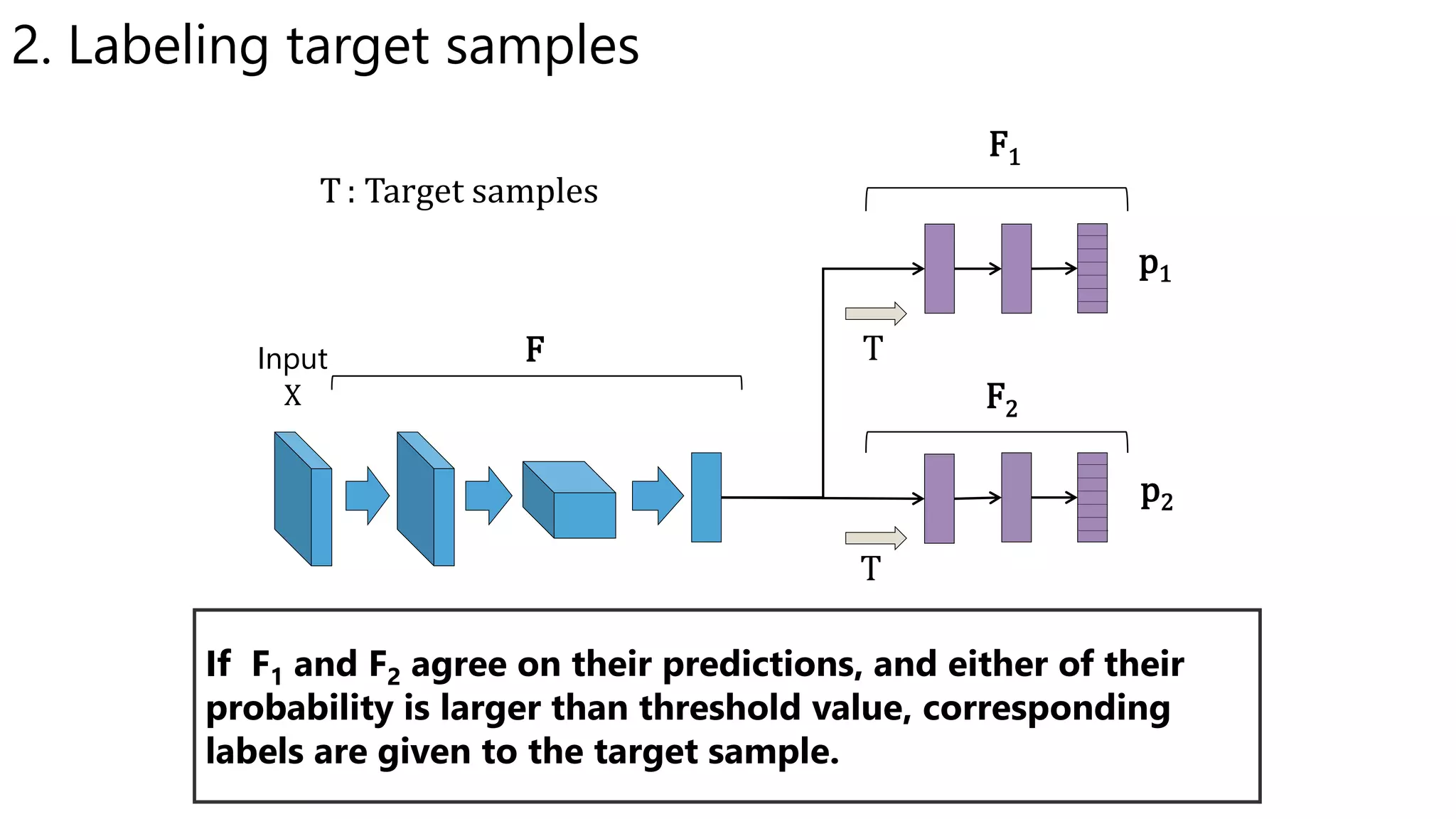
![Relationship with Tri-training
• Tri-training [Zhou et al., 2005]
– Use three classifiers equally
• Use two classifiers to give labels to unlabeled samples
• Train one classifiers by the labeled samples
• Repeat in all combination of classifiers
• Our proposed method
– Use three classifiers asymmetrically
• Use fixed two classifiers to give labels
• Train a fixed one classifier using the pseudo-labeled samples](https://image.slidesharecdn.com/icmlpresentationmiruushiku-170815102008/75/Asymmetric-Tri-training-for-Unsupervised-Domain-Adaptation-16-2048.jpg)
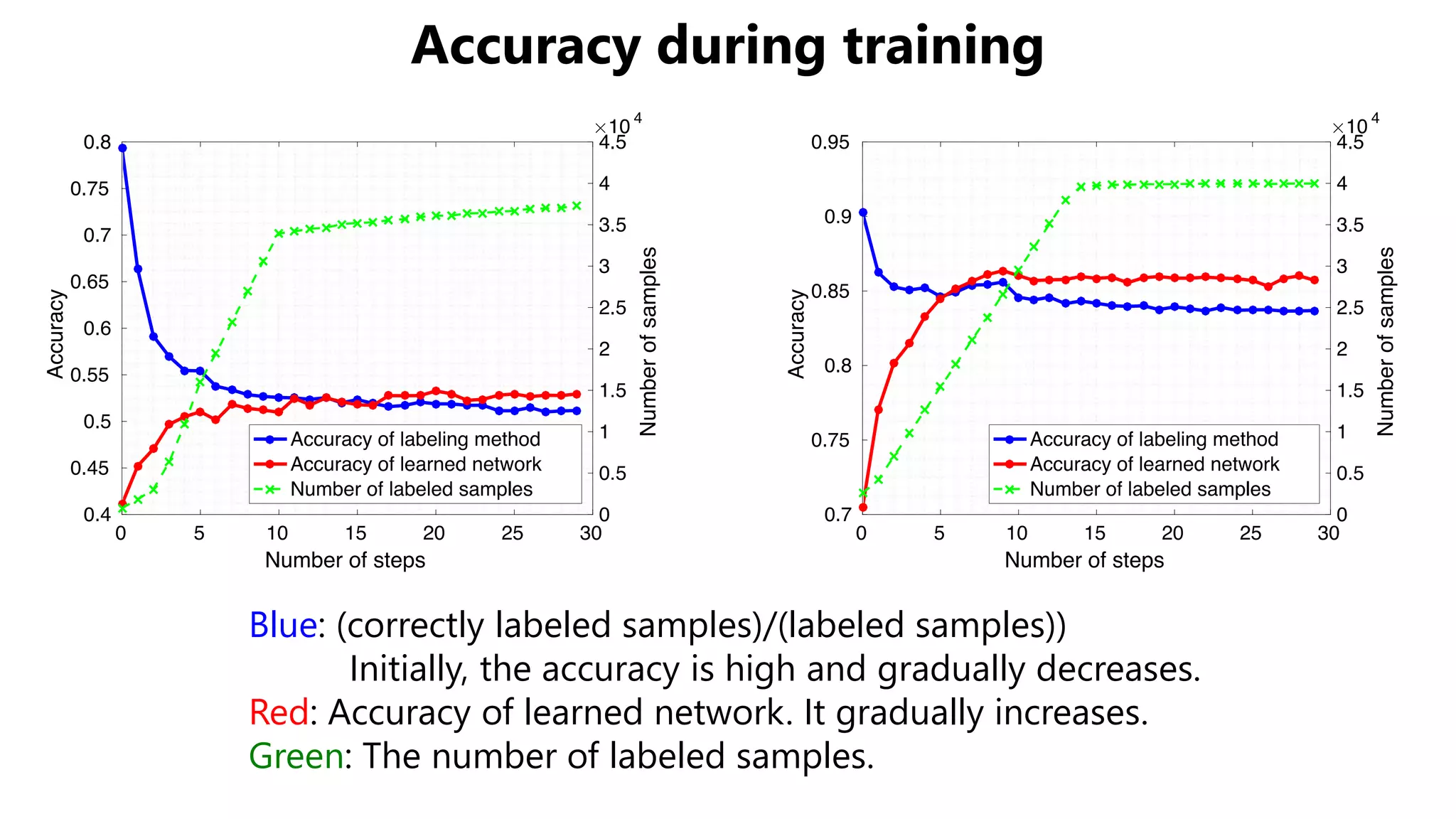

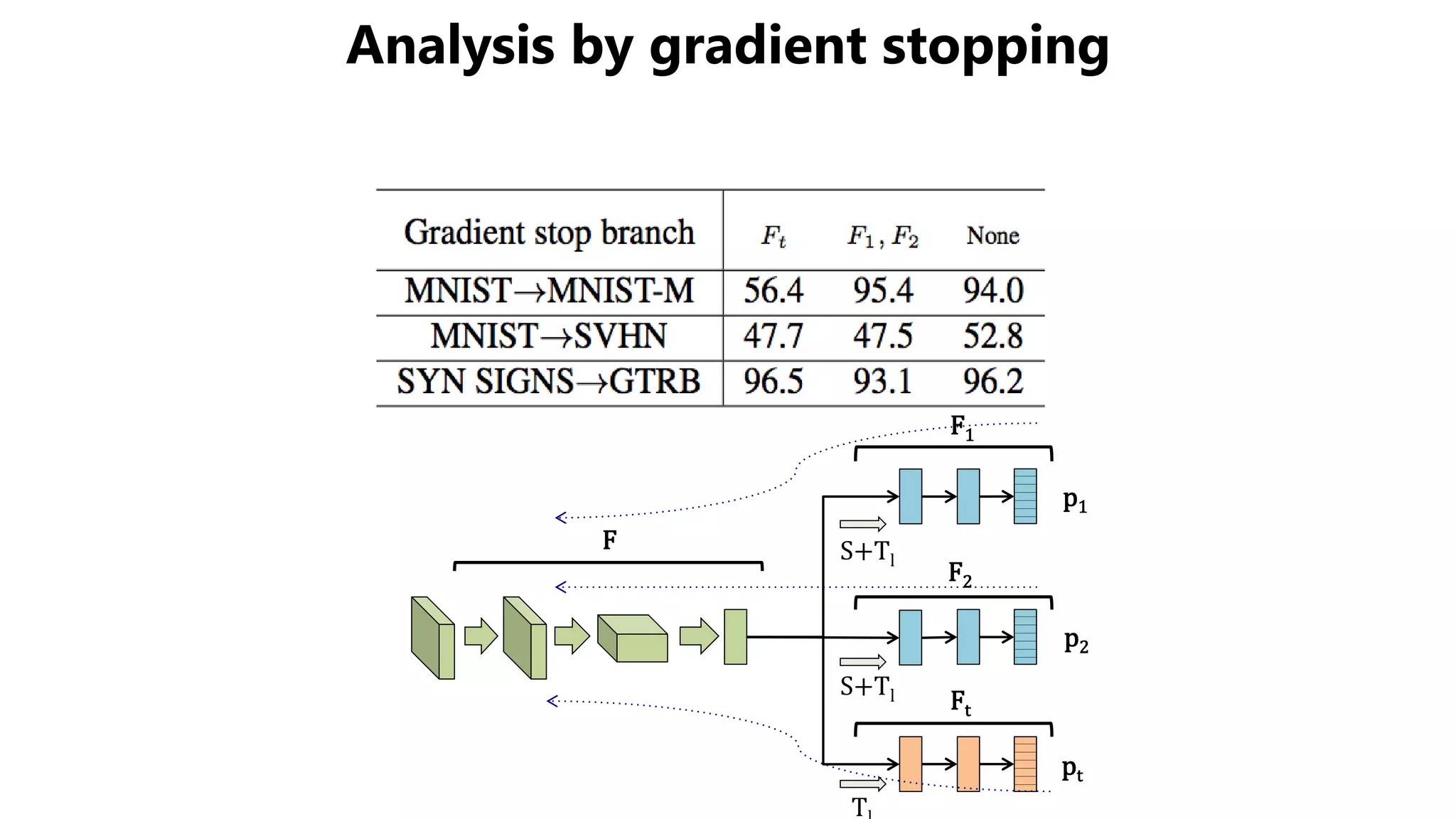
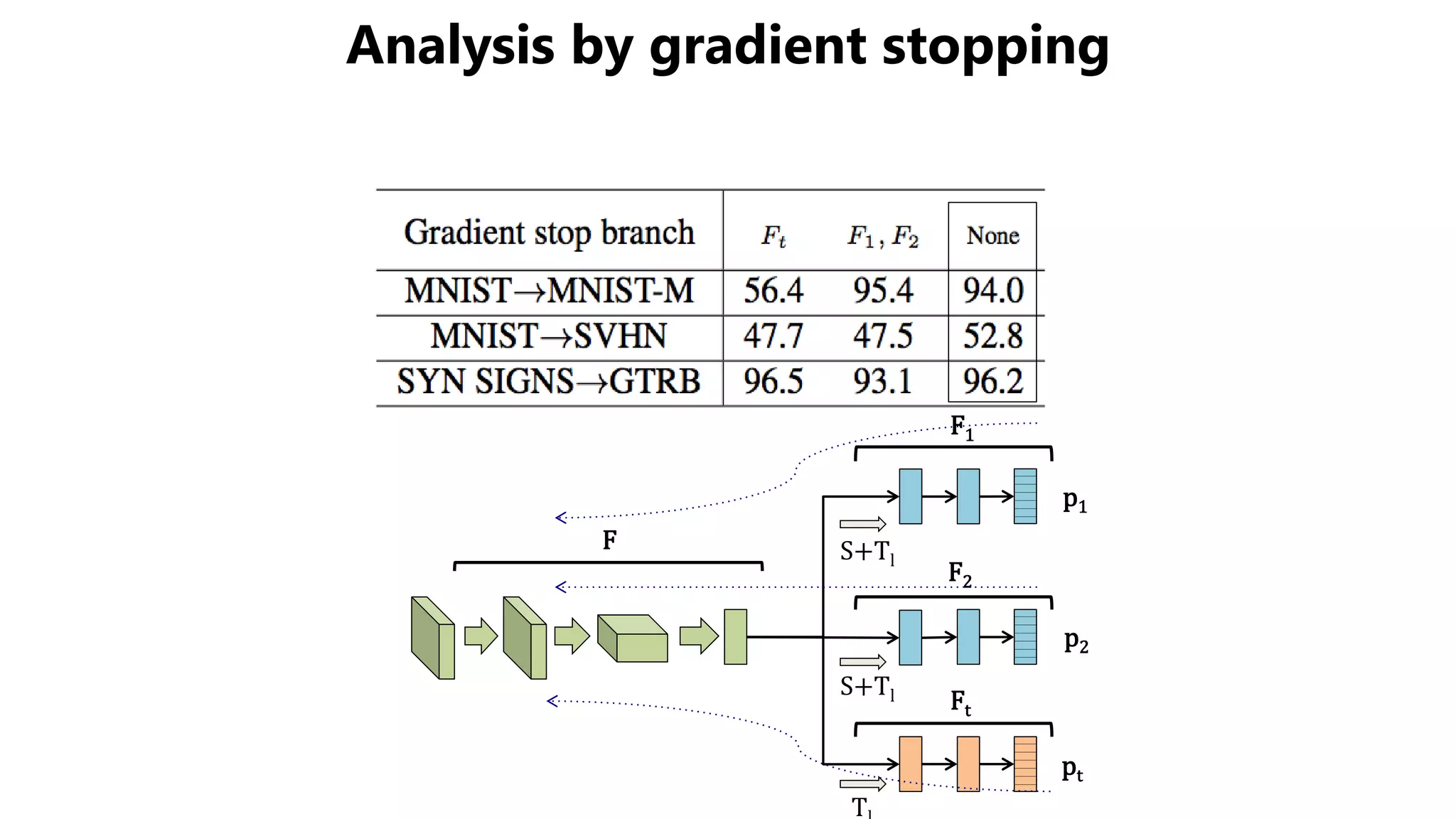
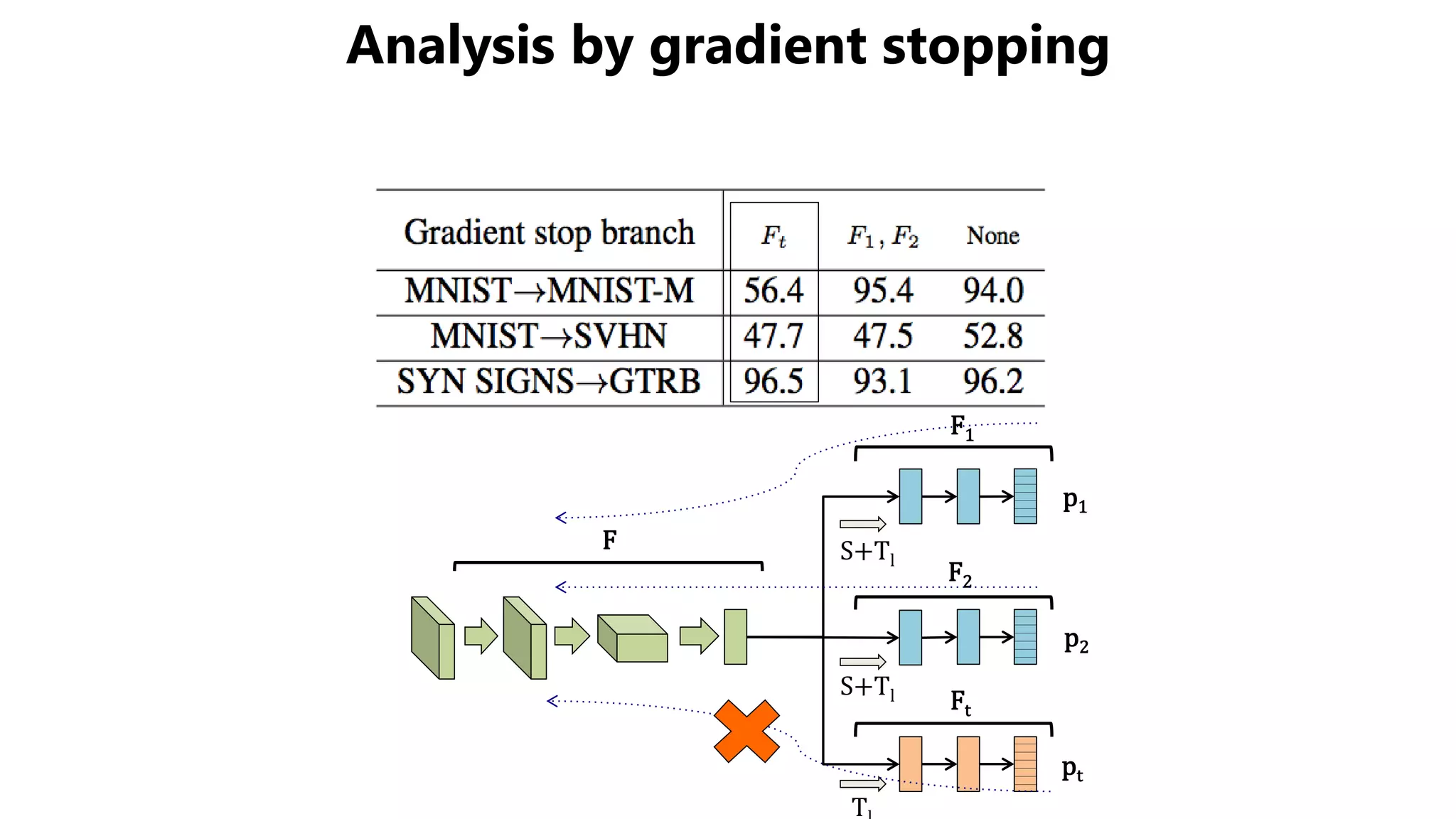
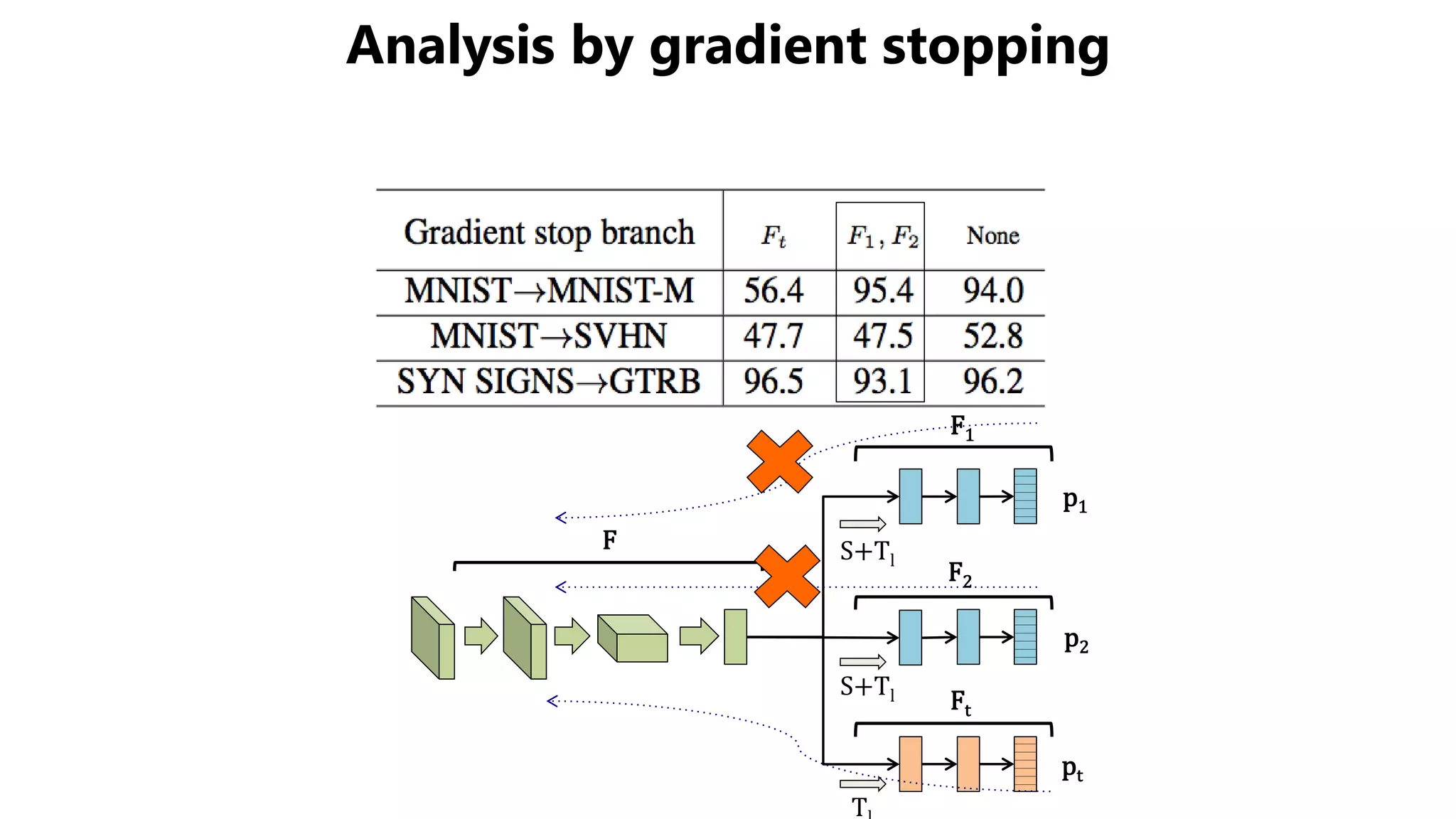

The document presents a novel asymmetric tri-training method for unsupervised domain adaptation, focusing on improving classifier performance when transferring knowledge from a labeled source domain to an unlabeled target domain. Experimental results demonstrate the effectiveness of this method over existing approaches in various adaptation scenarios. Future work includes evaluating this technique on fine-tuning pre-trained models.



































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)












