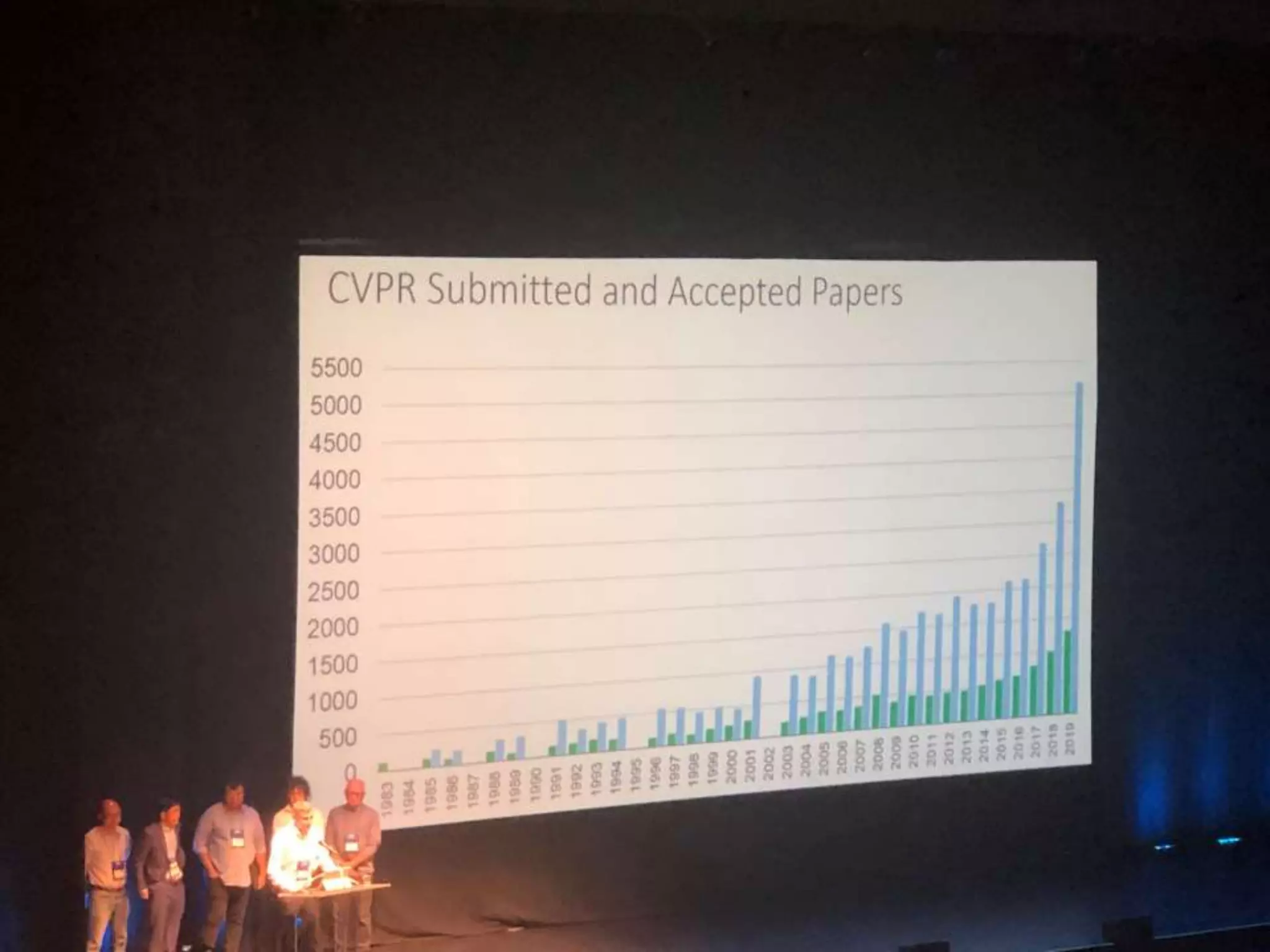
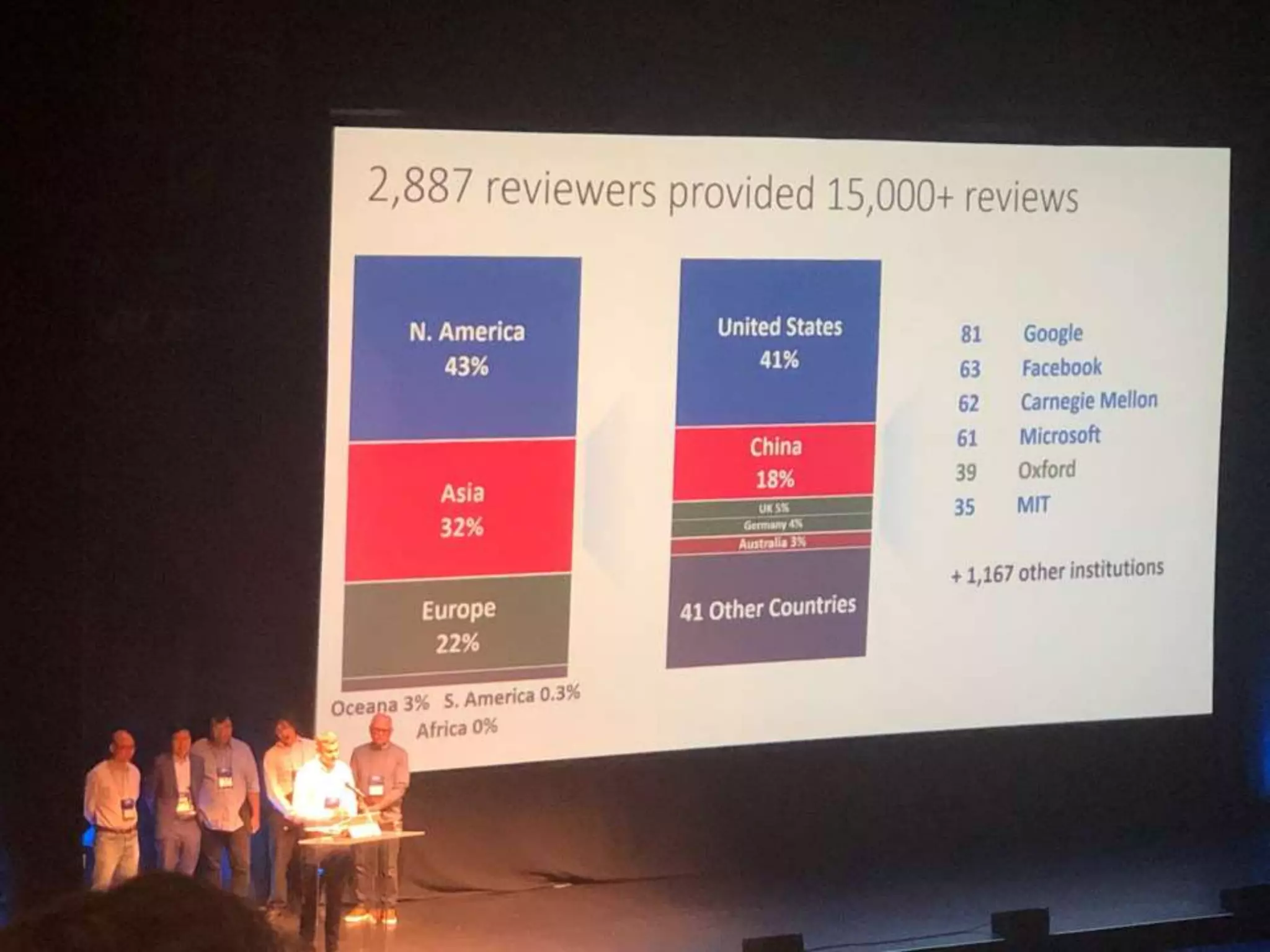
Downloaded 36 times












![自己紹介
2014.4 博士(情報理工学)、東京大学
2014.4~2016.3 NTT CS研 研究員
2016.4~ 東京大学 講師 (原田・牛久研究室)
2016.9~ 産業技術総合研究所 協力研究員
2016.12~ 国立国語研究所 共同研究員
2018.4~ オムロンサイニックエックス株式会社
技術アドバイザ(NEW!!)
[Ushiku+, ACMMM 2012]
[Ushiku+, ICCV 2015]
画像キャプション生成 主観的な感性表現を持つ
画像キャプション生成
動画の特定区間と
キャプションの相互検索
[Yamaguchi+, ICCV 2017]
A guy is skiing with no shirt on and
yellow snow pants.
A zebra standing in a field with a
tree in the dirty background.
[Shin+, BMVC 2016]
A yellow train on the tracks near a
train station.](https://image.slidesharecdn.com/20190630kantocvcvpr-190630035854/75/Reinforced-Cross-Modal-Matching-and-Self-Supervised-Imitation-Learning-for-Vision-Language-Navigation-CV-CVPR-2019-16-2048.jpg)
![自己紹介
2014.3 博士(情報理工学)、東京大学
2014.4~2016.3 NTTコミュニケーション科学基礎研究所 研究員
2016.4~2018.9 東京大学 講師 (原田・牛久研究室)
2016.9~ 産業技術総合研究所 協力研究員
2016.12~2018.9 国立国語研究所 共同研究員
2018.4~2018.9 オムロンサイニックエックス株式会社 技術アドバイザ
2018.10~ オムロンサイニックエックス株式会社
Principal Investigator
2019.1~ 株式会社Ridge-I 社外 Chief Research Officer
[Ushiku+, ACMMM 2012]
[Ushiku+, ICCV 2015]
画像キャプション生成 主観的な感性表現を持つ
画像キャプション生成
動画の特定区間と
キャプションの相互検索
[Yamaguchi+, ICCV 2017]
A guy is skiing with no shirt on and
yellow snow pants.
A zebra standing in a field with a
tree in the dirty background.
[Shin+, BMVC 2016]
A yellow train on the tracks near a
train station.](https://image.slidesharecdn.com/20190630kantocvcvpr-190630035854/75/Reinforced-Cross-Modal-Matching-and-Self-Supervised-Imitation-Learning-for-Vision-Language-Navigation-CV-CVPR-2019-17-2048.jpg)
![自己紹介
2014.3 博士(情報理工学)、東京大学
2014.4~2016.3 NTTコミュニケーション科学基礎研究所 研究員
2016.4~2018.9 東京大学 講師 (原田・牛久研究室)
2016.9~ 産業技術総合研究所 協力研究員
2016.12~2018.9 国立国語研究所 共同研究員
2018.4~2018.9 オムロンサイニックエックス株式会社 技術アドバイザ
2018.10~ オムロンサイニックエックス株式会社
Principal Investigator
2019.1~ 株式会社Ridge-I 社外 Chief Research Officer
[Ushiku+, ACMMM 2012]
[Ushiku+, ICCV 2015]
画像キャプション生成 主観的な感性表現を持つ
画像キャプション生成
動画の特定区間と
キャプションの相互検索
[Yamaguchi+, ICCV 2017]
A guy is skiing with no shirt on and
yellow snow pants.
A zebra standing in a field with a
tree in the dirty background.
[Shin+, BMVC 2016]
A yellow train on the tracks near a
train station.
いよっ!job-hopp…
関東CV勉強会のおかげで
転職も兼職もできました!](https://image.slidesharecdn.com/20190630kantocvcvpr-190630035854/75/Reinforced-Cross-Modal-Matching-and-Self-Supervised-Imitation-Learning-for-Vision-Language-Navigation-CV-CVPR-2019-18-2048.jpg)






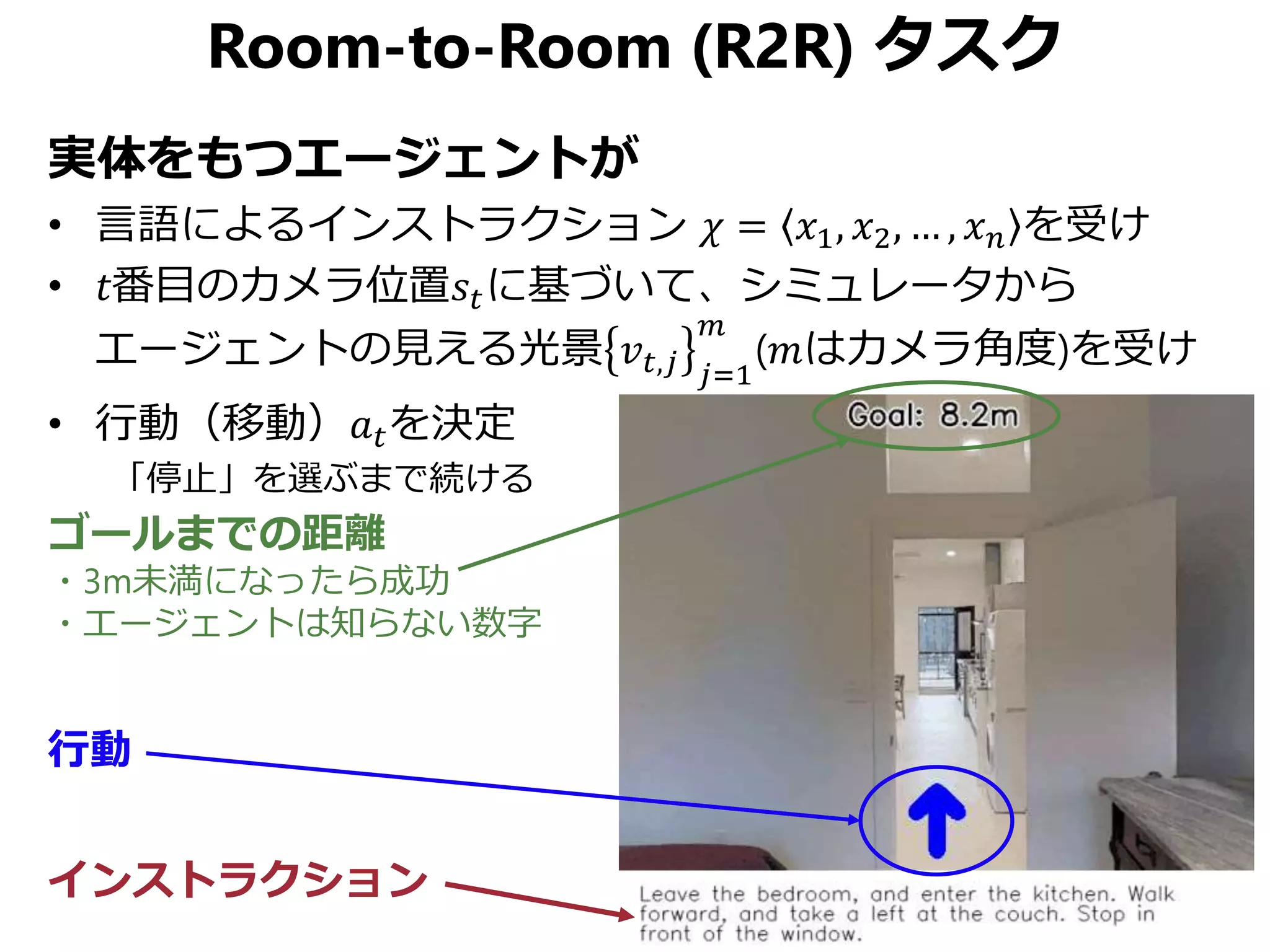
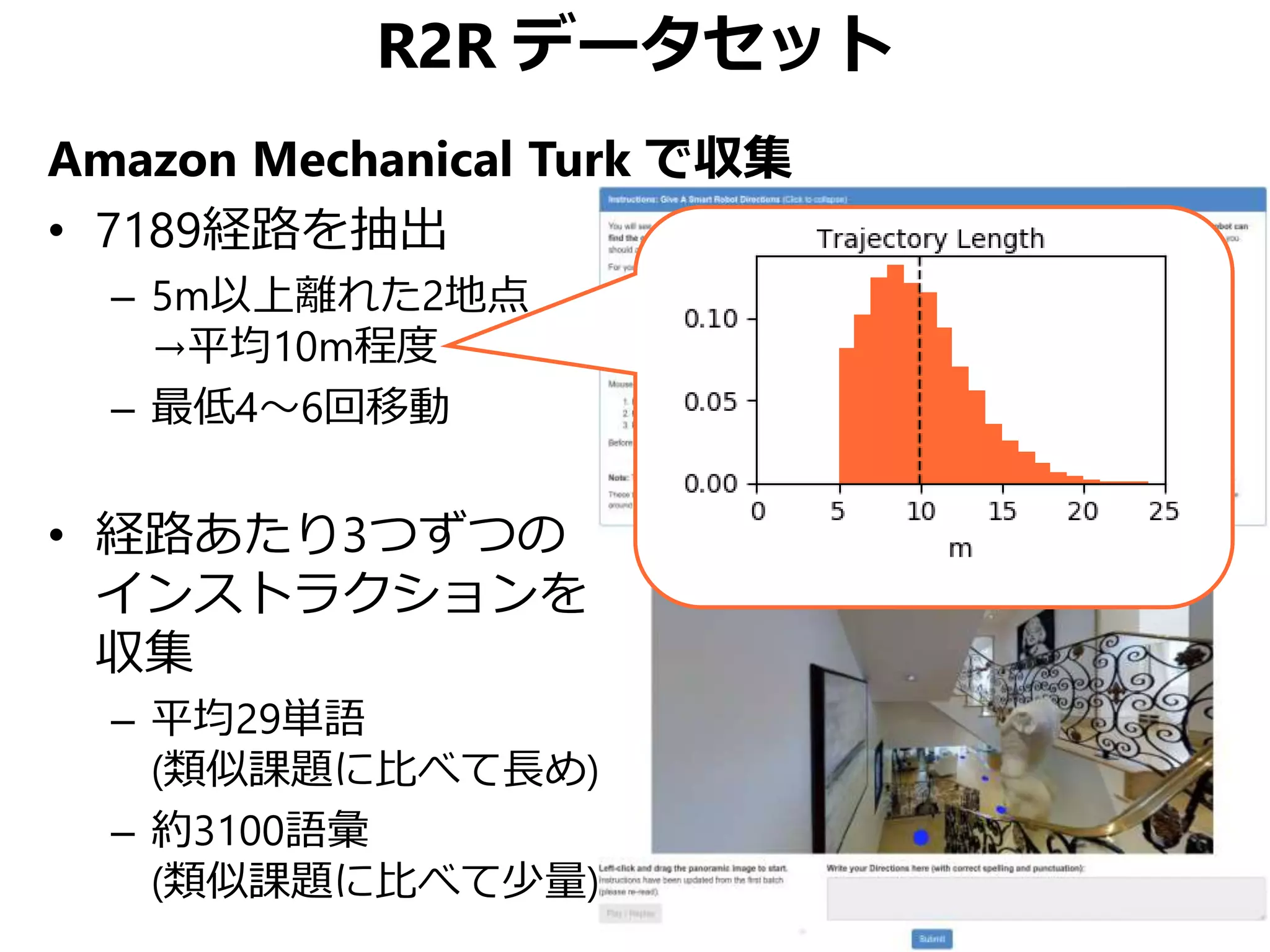
![実世界3次元データセットの活用
• 他のRGBDデータだと…
– NYUv2, SUN RGB-D, ScanNet
– 動画像なのでパスの選択肢がほとんどない
• Matterport 3D [Chang+, 3DV 2017]
– 90の建造物で総計10,800点のパノラマRGBD画像を収集
– 各点で18方向のRGBD画像を収集→パノラマ化
– 平均2.25m間隔、人の目線の高さ、カメラポーズも記録](https://image.slidesharecdn.com/20190630kantocvcvpr-190630035854/75/Reinforced-Cross-Modal-Matching-and-Self-Supervised-Imitation-Learning-for-Vision-Language-Navigation-CV-CVPR-2019-26-2048.jpg)



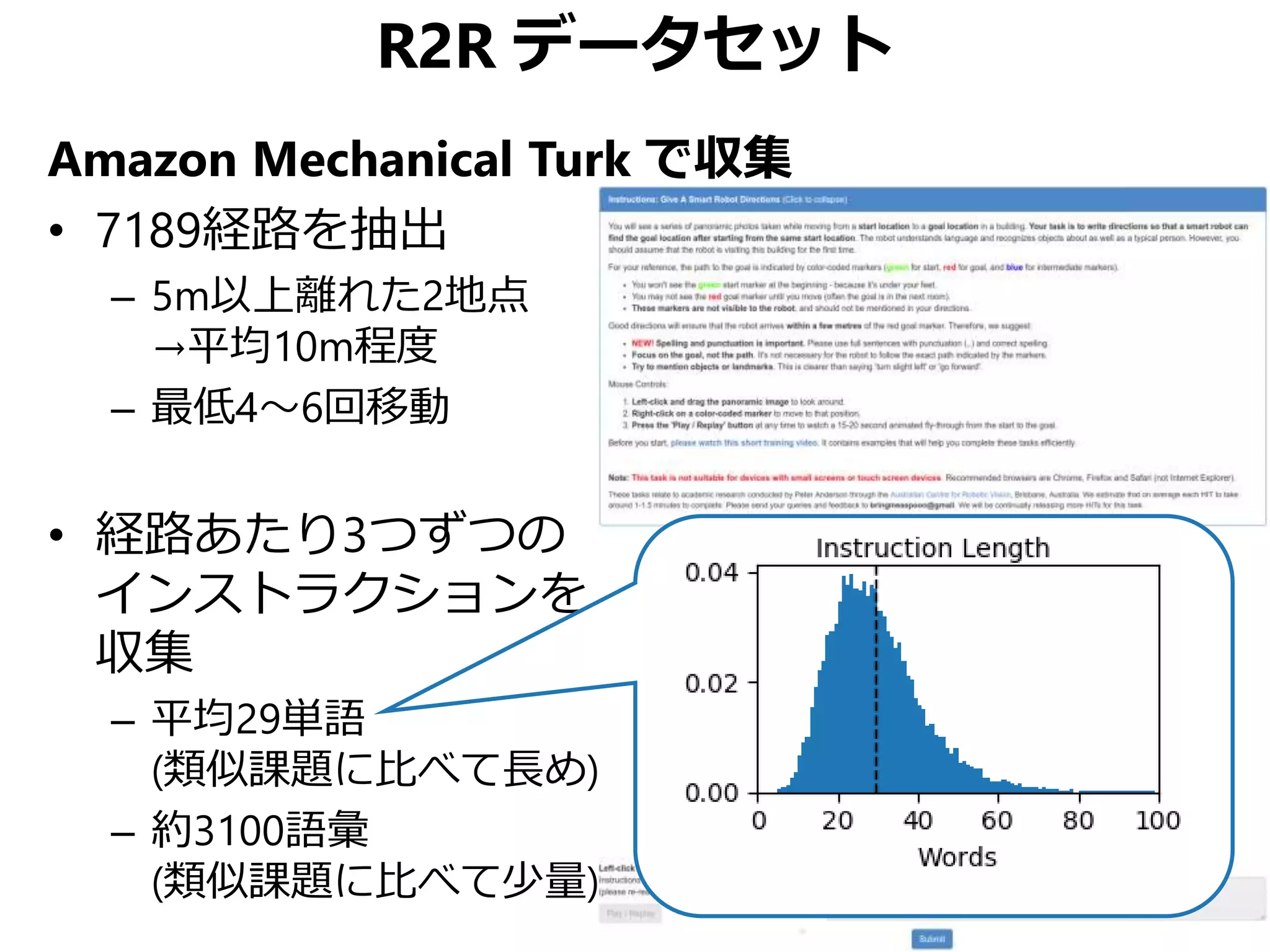

![Speaker-Follower モデル
• データセット提案論文 [Anderson+, CVPR 2018]:
– 道順を聞いて動くエージェント (Follower) のみモデル
– Follower は正面の画像のみ見ている設定
• 本研究:
– 道順そのものを新たな経路から生成できるエージェント
(Speaker) を用意→訓練データを拡張
– Follower は360°画像を利用
[Fried+, NeurIPS 2018]](https://image.slidesharecdn.com/20190630kantocvcvpr-190630035854/75/Reinforced-Cross-Modal-Matching-and-Self-Supervised-Imitation-Learning-for-Vision-Language-Navigation-CV-CVPR-2019-33-2048.jpg)


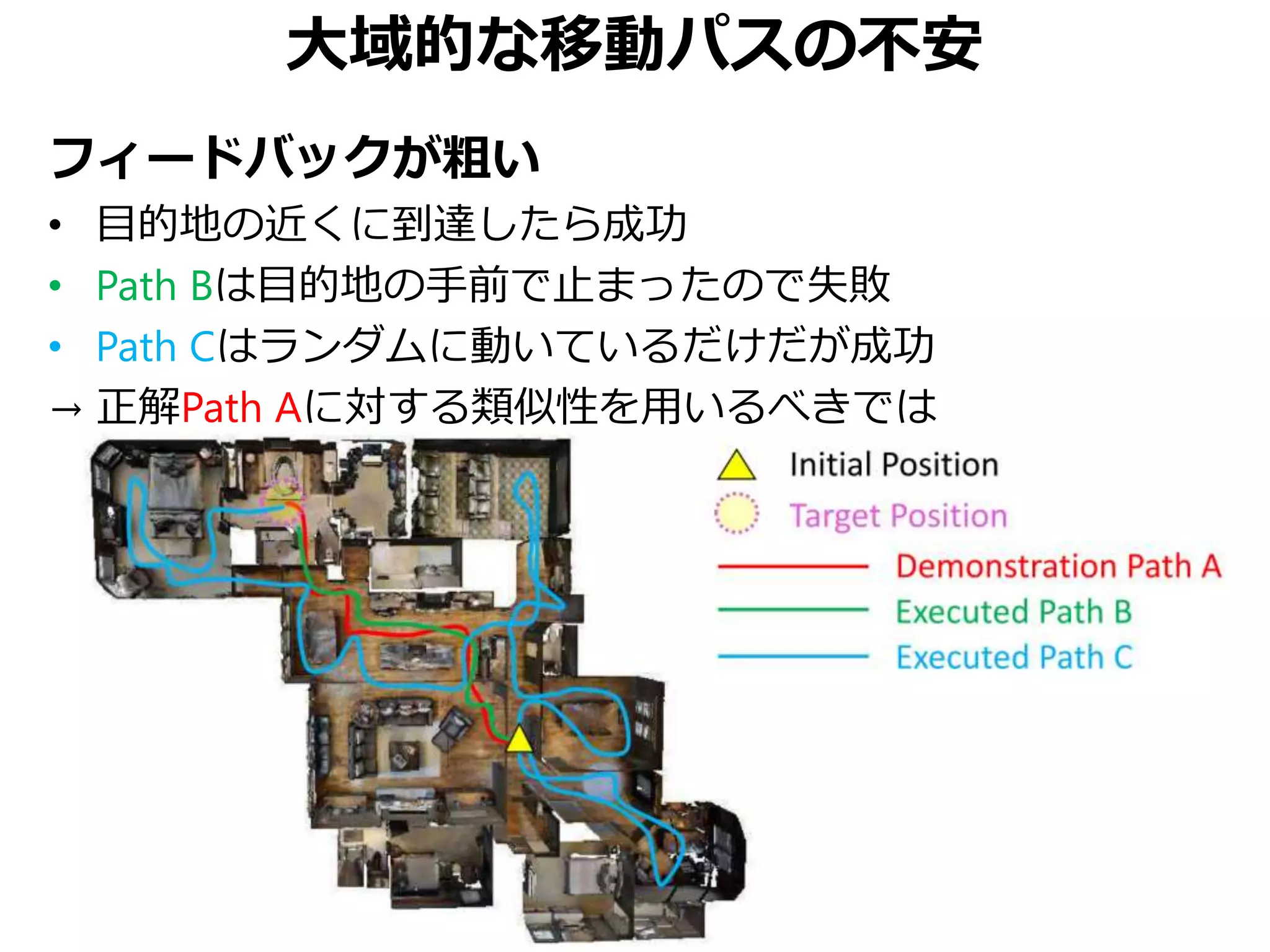
![未知の環境での移動に対する不安
未知の環境下だと既知の環境下の様に振舞えない
cf. [Tan+, NAACL 2019] ← arXiv 2019年4月公開
• 同様の動機からEnvironmental Dropoutを提案
• 実は本論文を少し上回る性能を達成している
(本論文のarXiv公開は2018年11月)](https://image.slidesharecdn.com/20190630kantocvcvpr-190630035854/75/Reinforced-Cross-Modal-Matching-and-Self-Supervised-Imitation-Learning-for-Vision-Language-Navigation-CV-CVPR-2019-37-2048.jpg)
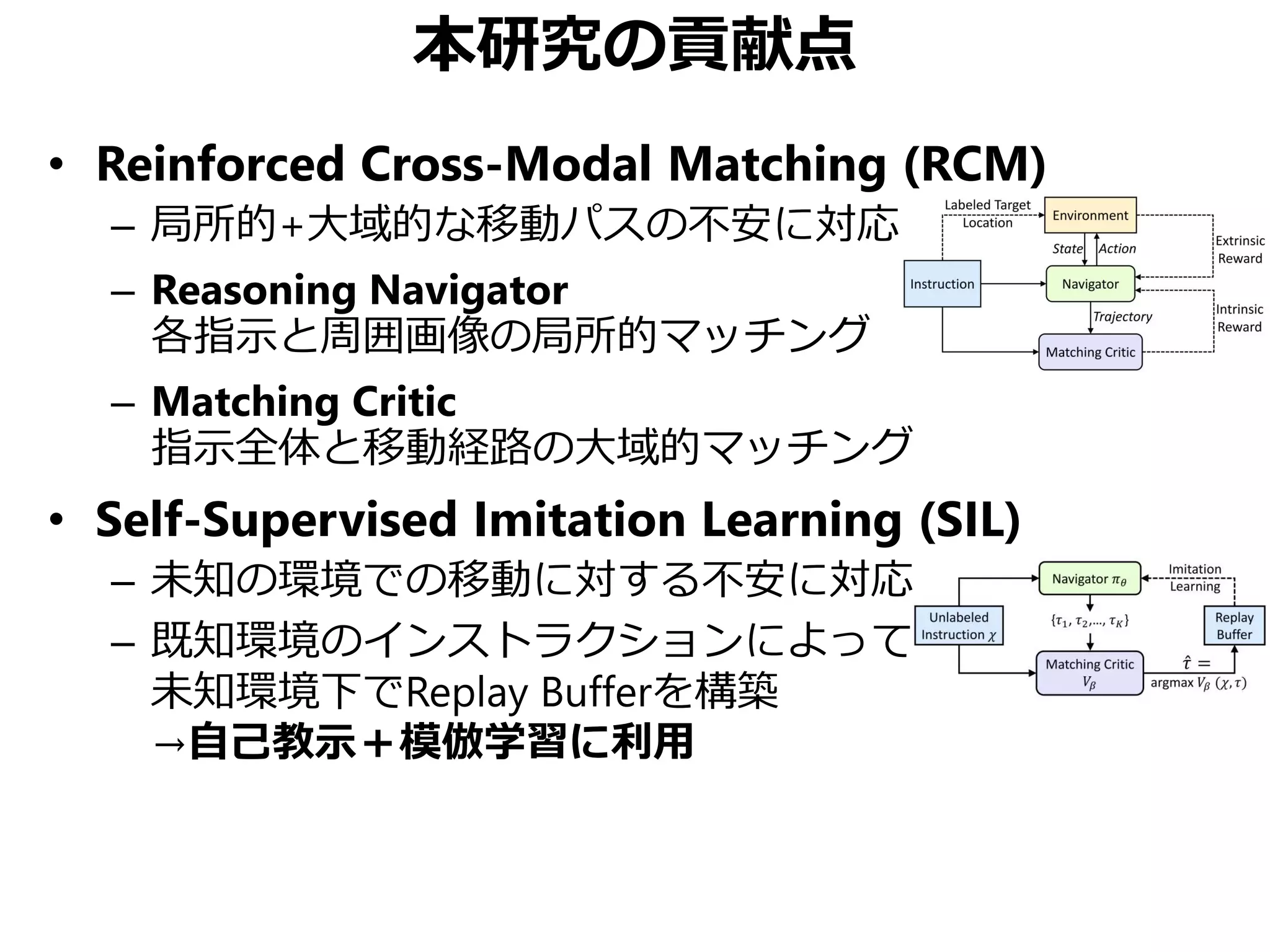
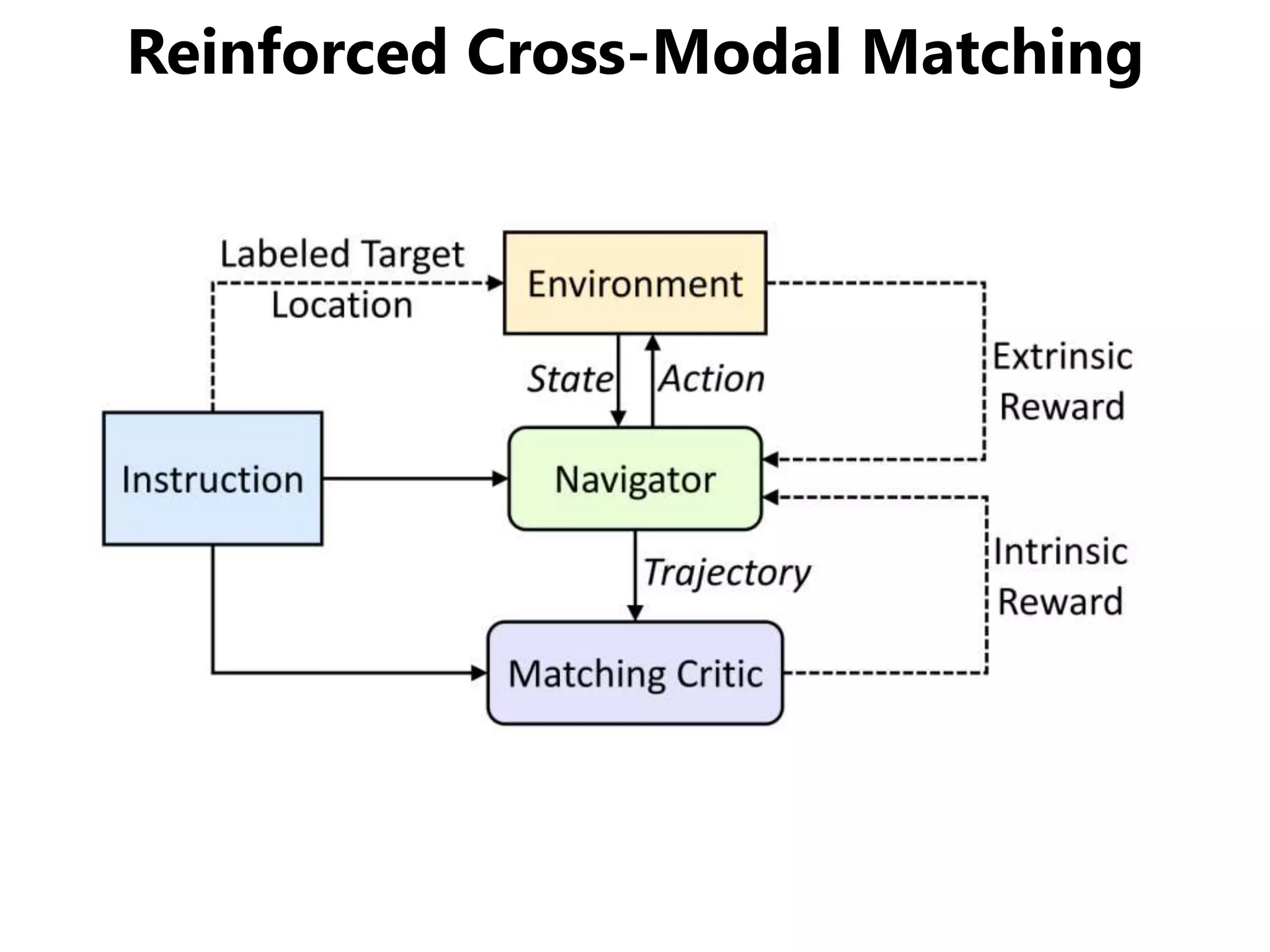
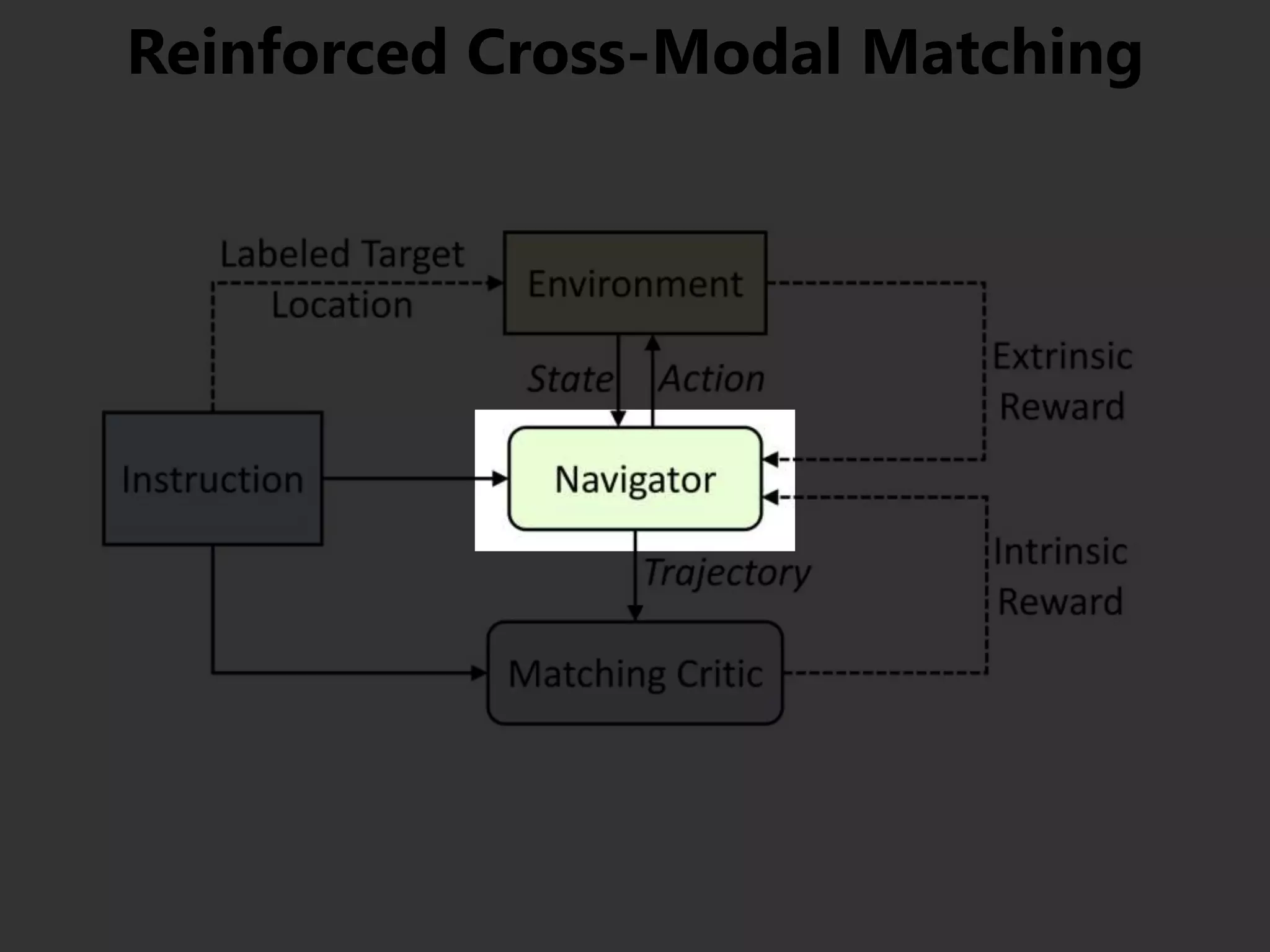
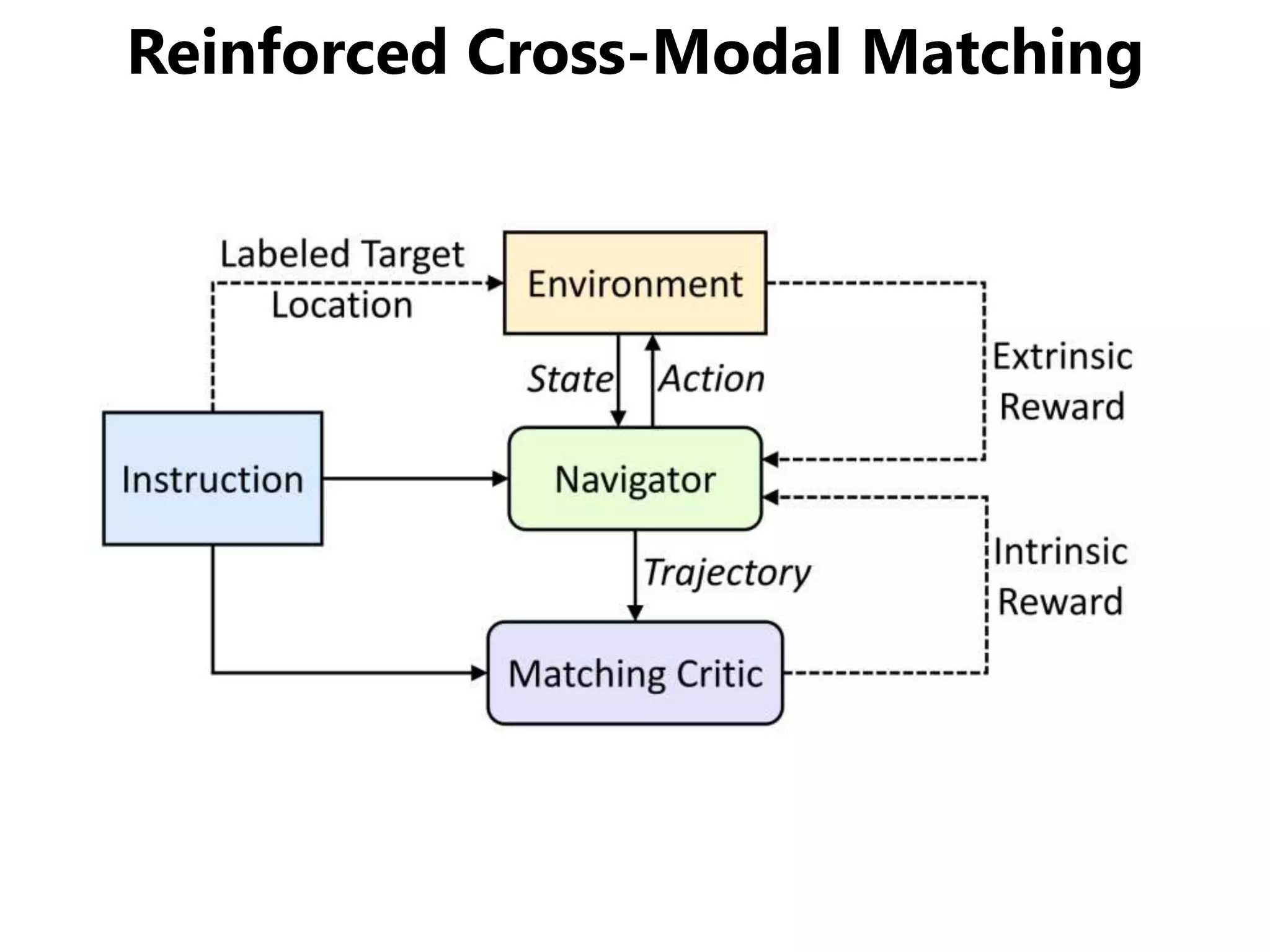


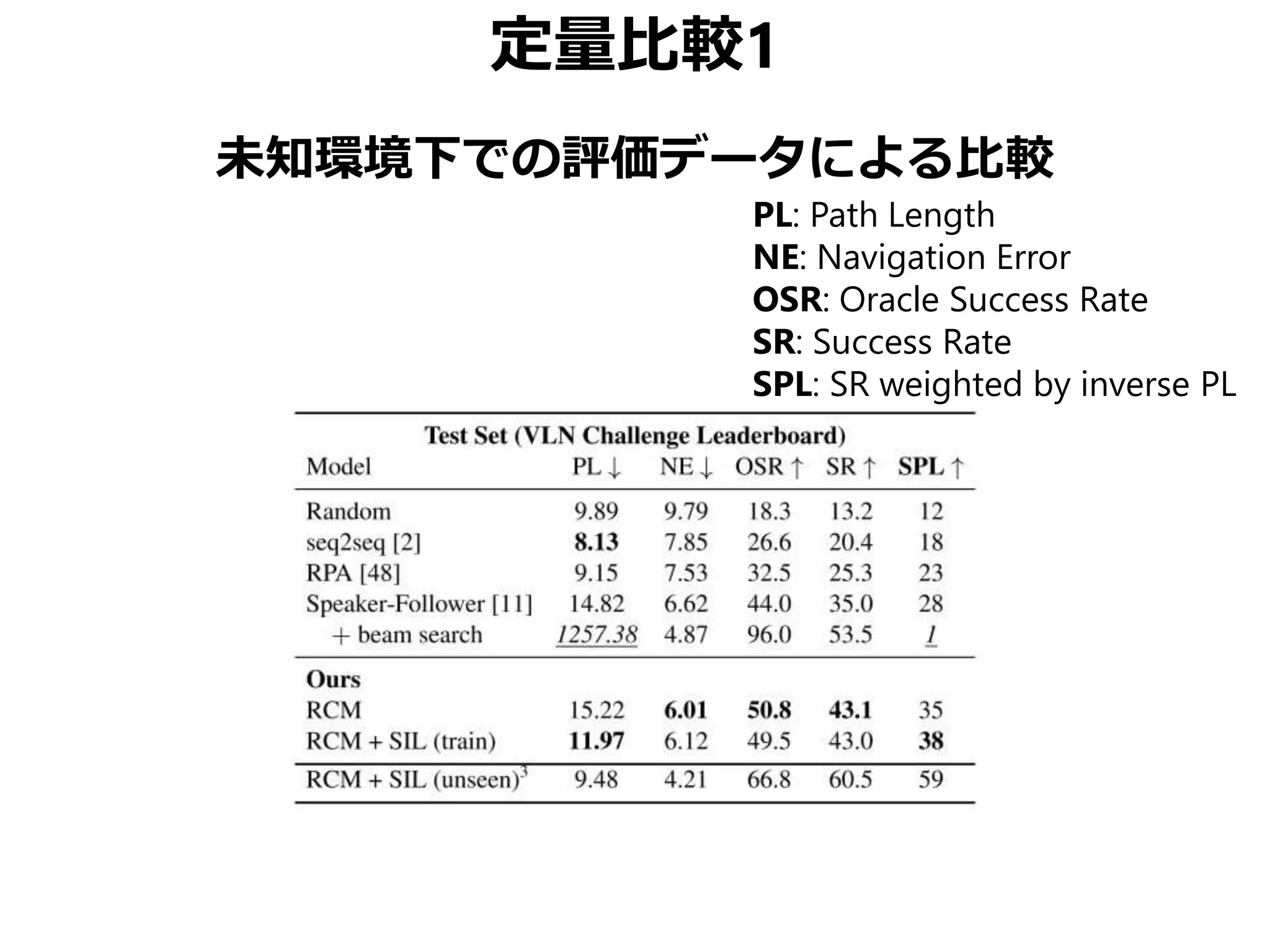
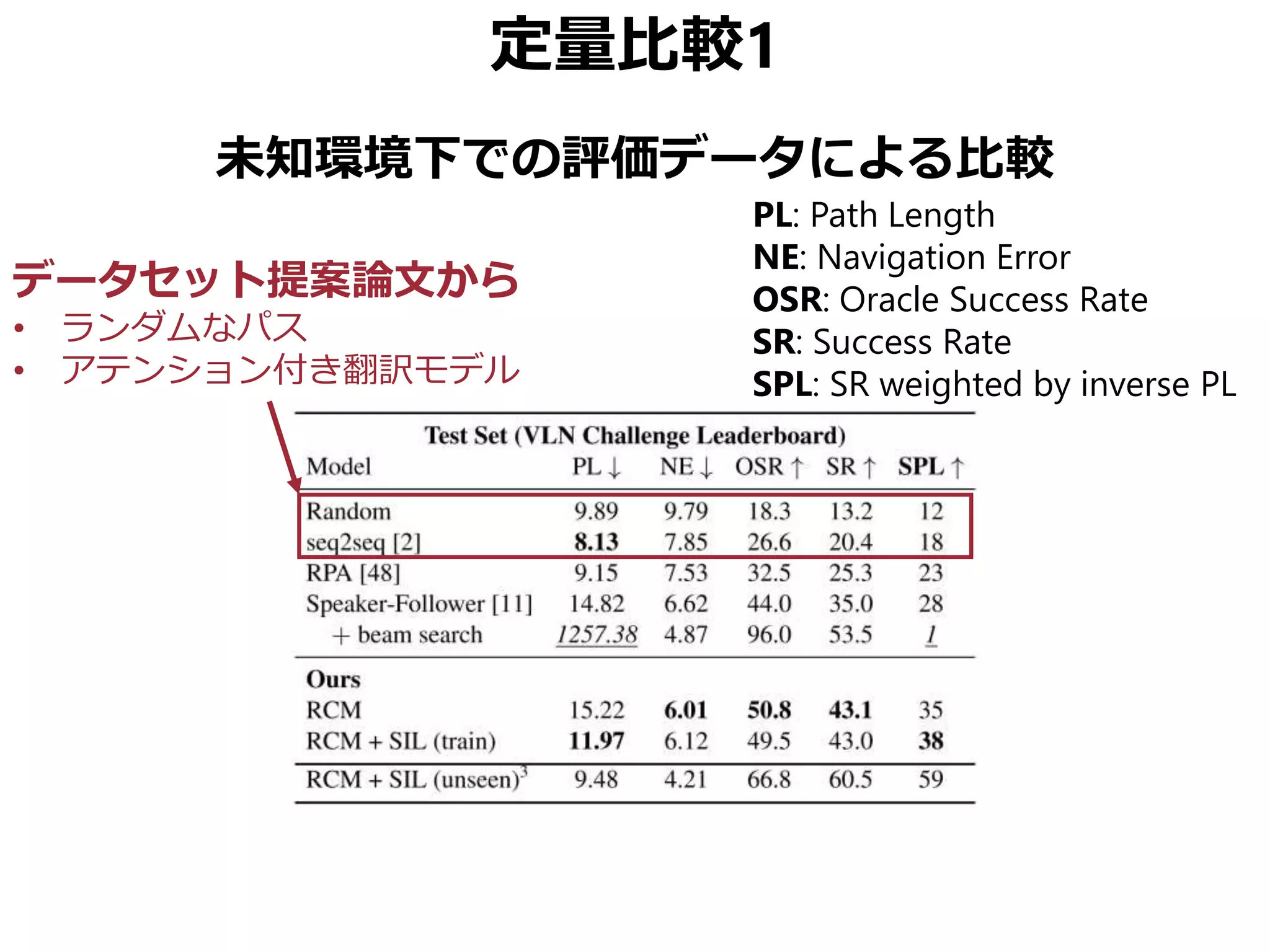
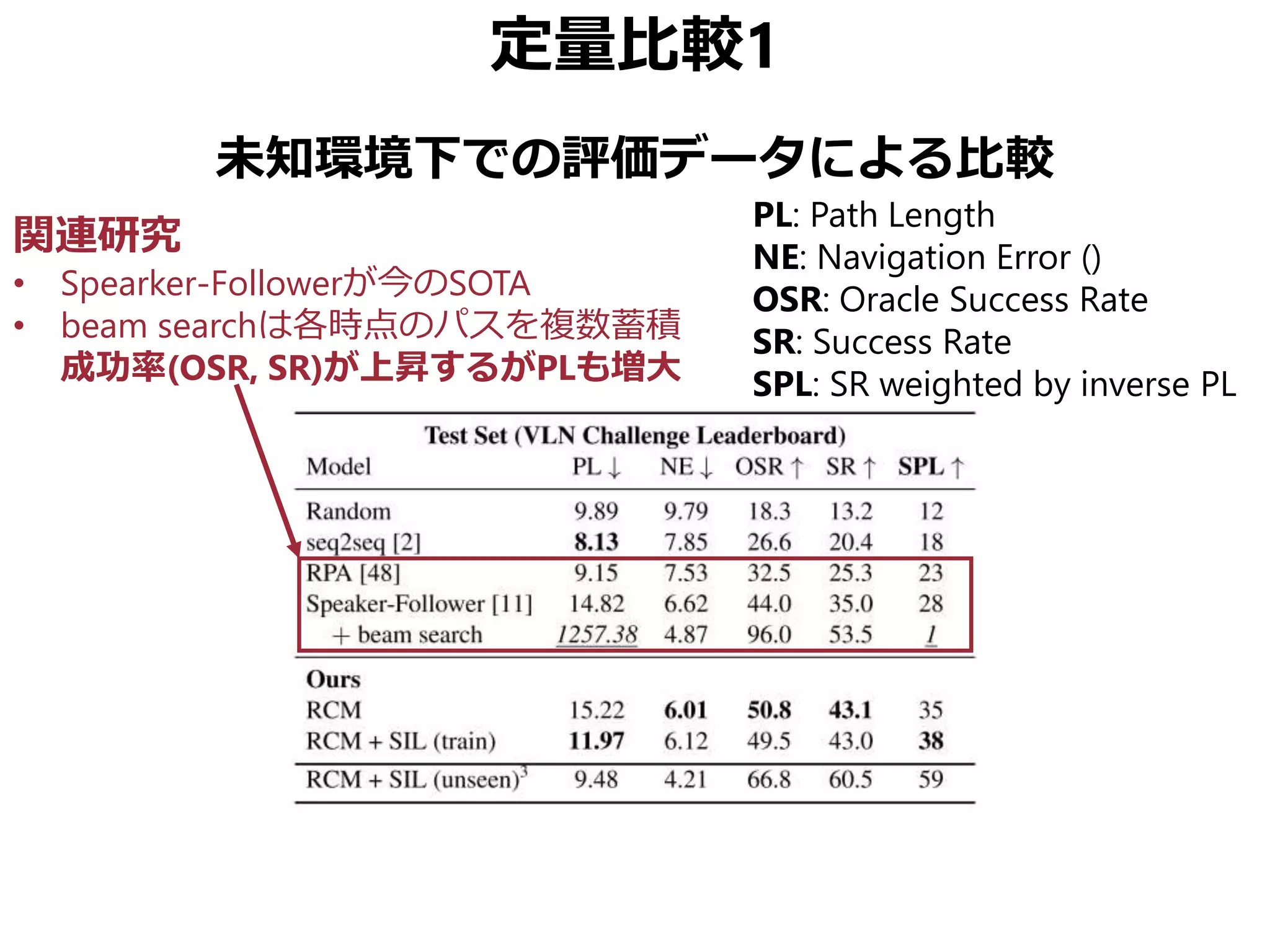

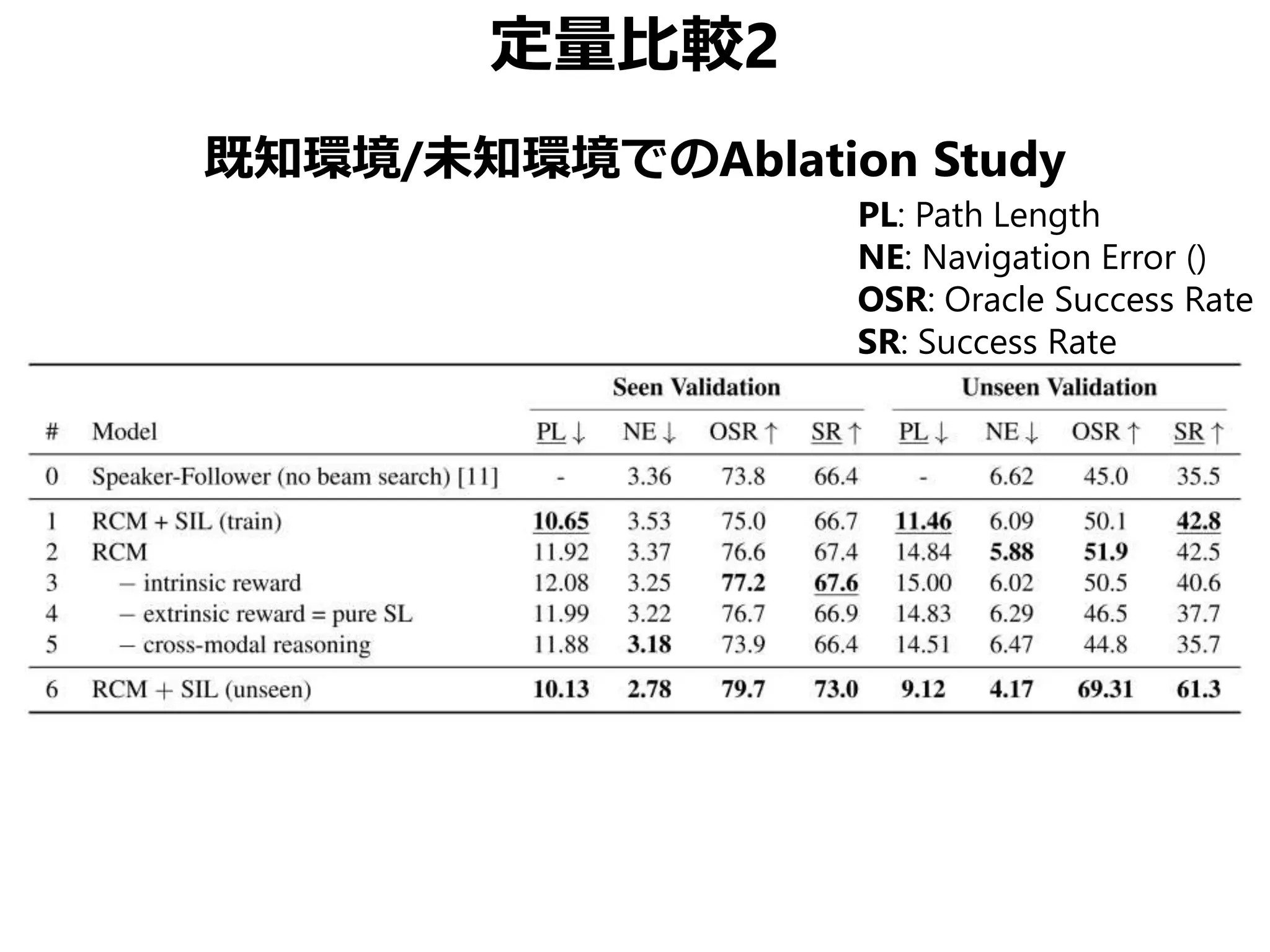
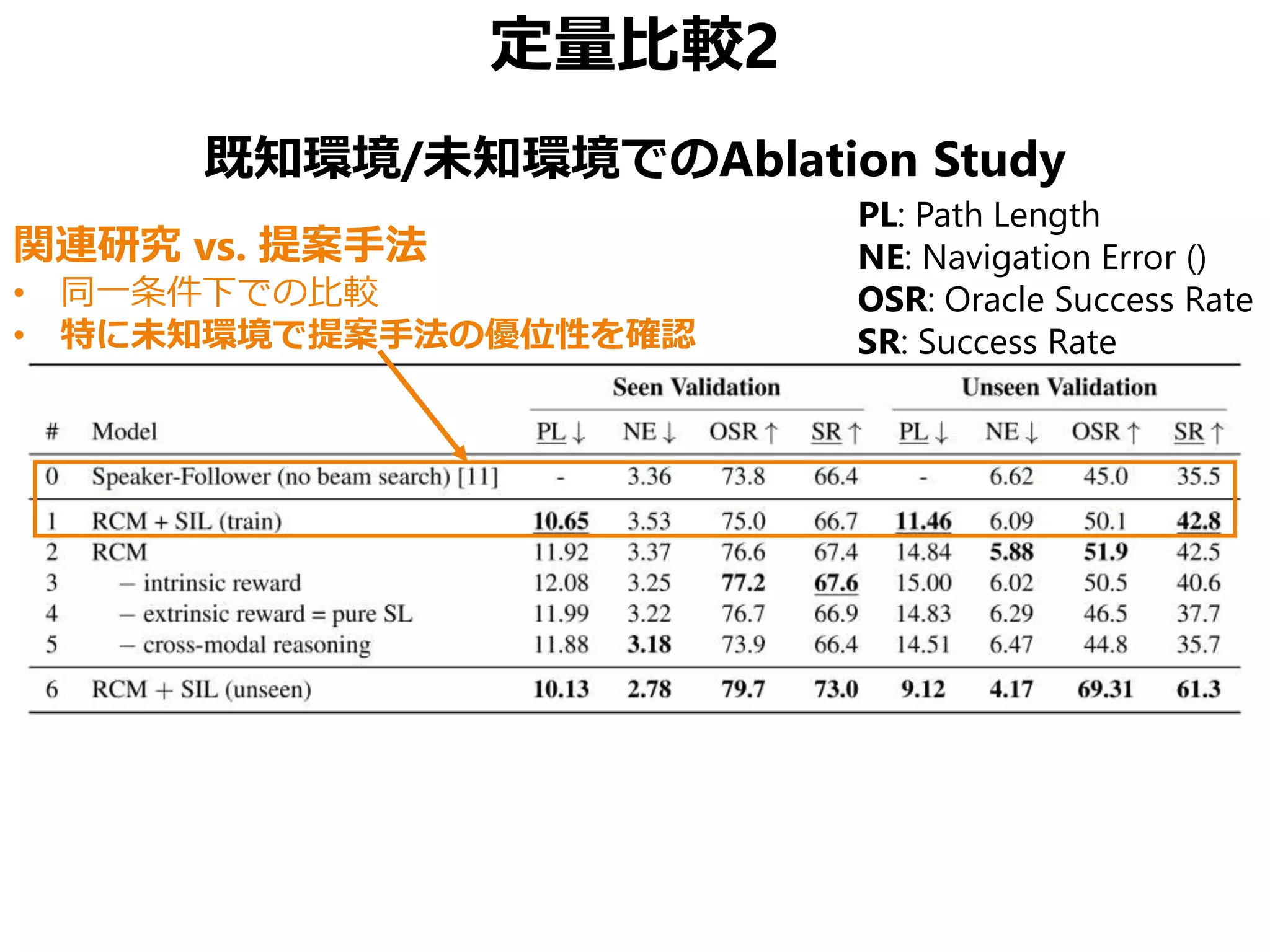
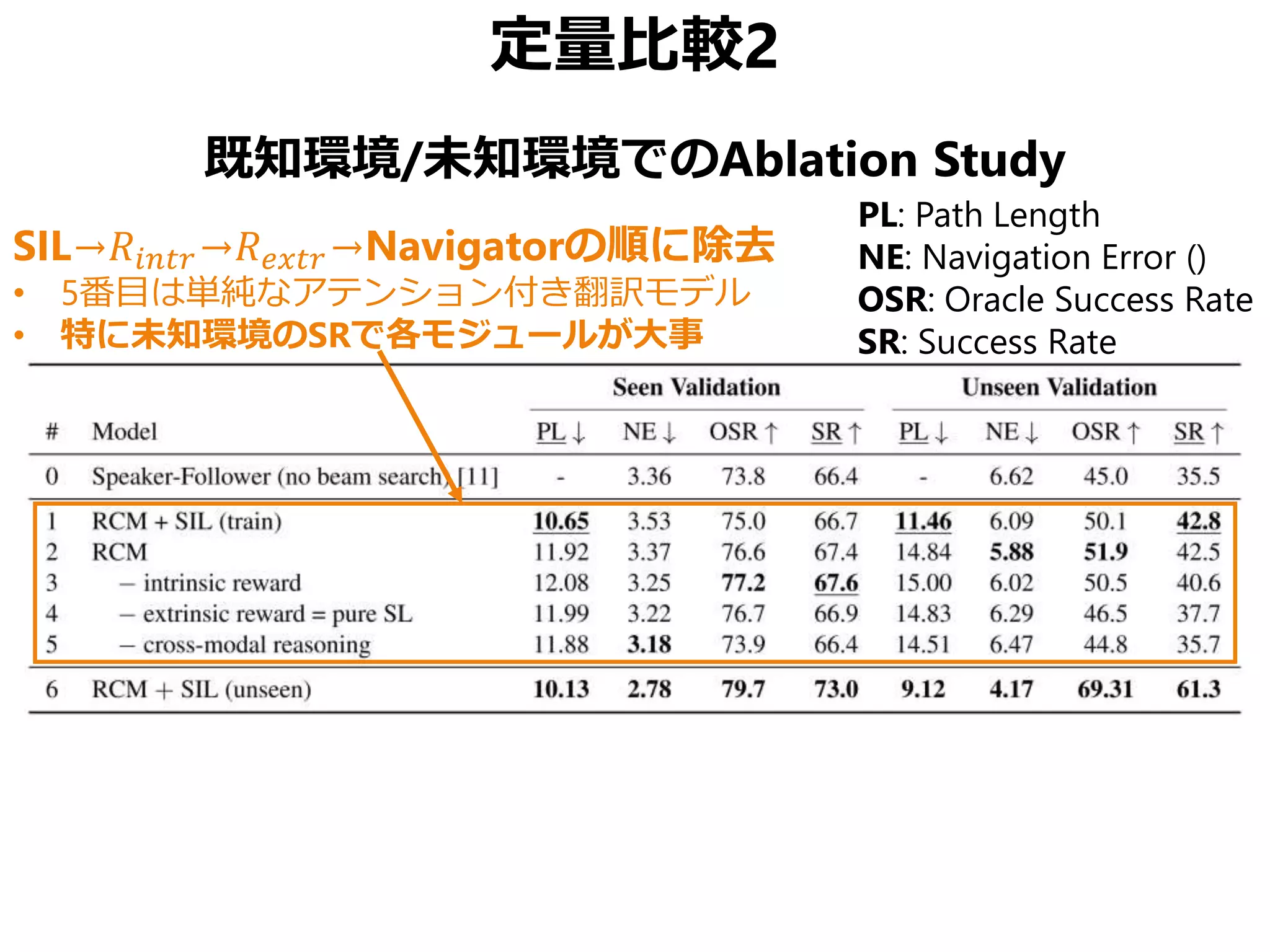
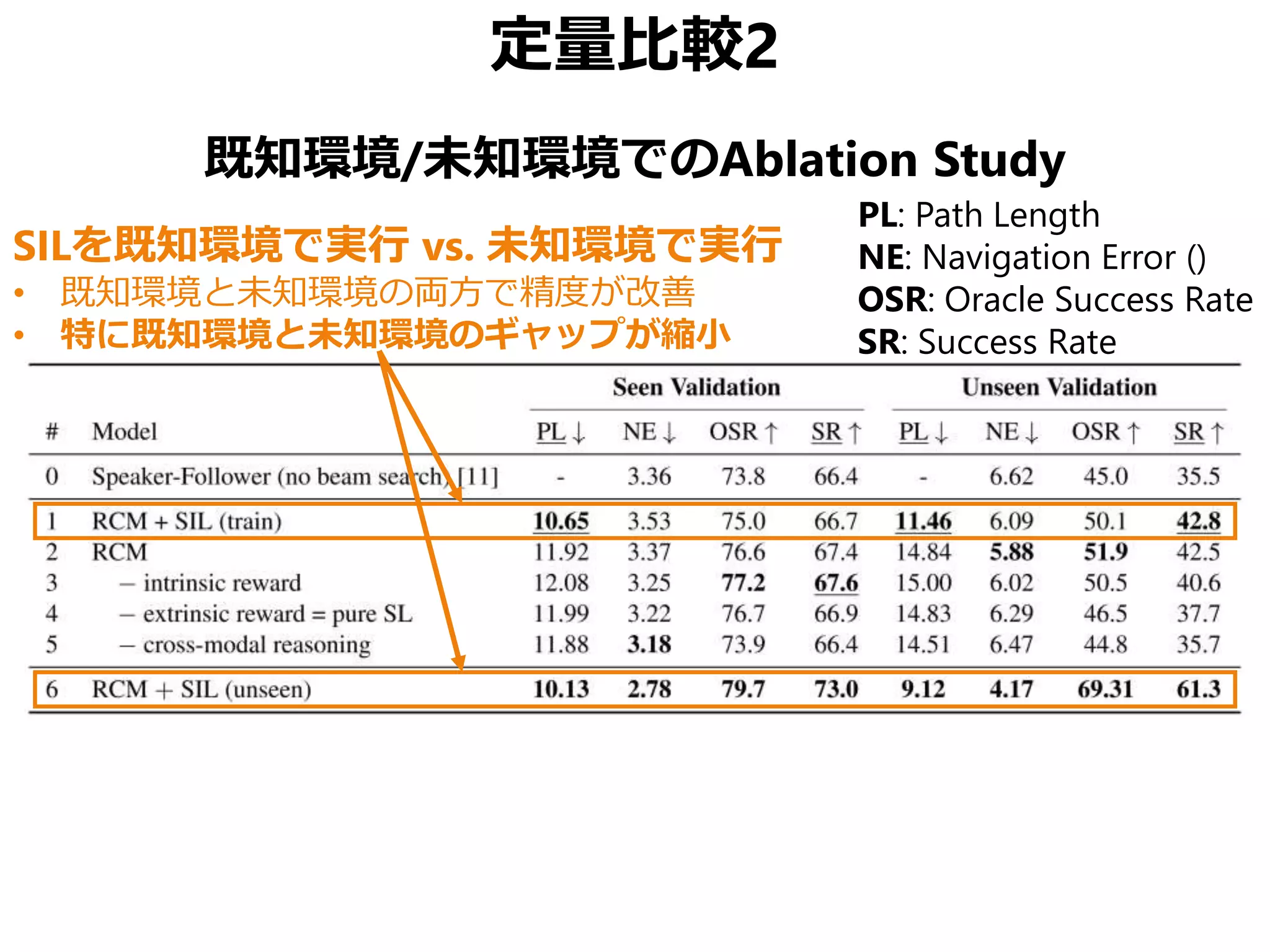












![まとめ
Vision-Language Navigation (VNL) のために
• Reinforced Cross-Modal Matching (RCM)
局所的/大域的な移動パスのマッチング
• Self-Supervised Imitation Learning (SIL)
未知環境下での自己教示模倣学習
CVPR 2019 Best Student Paper Award
• 同様の動機の論文でSOTA更新済み[Tan+, NAACL 2019]
• ただしこちらはBest Paperではない(よいこと)](https://image.slidesharecdn.com/20190630kantocvcvpr-190630035854/75/Reinforced-Cross-Modal-Matching-and-Self-Supervised-Imitation-Learning-for-Vision-Language-Navigation-CV-CVPR-2019-73-2048.jpg)












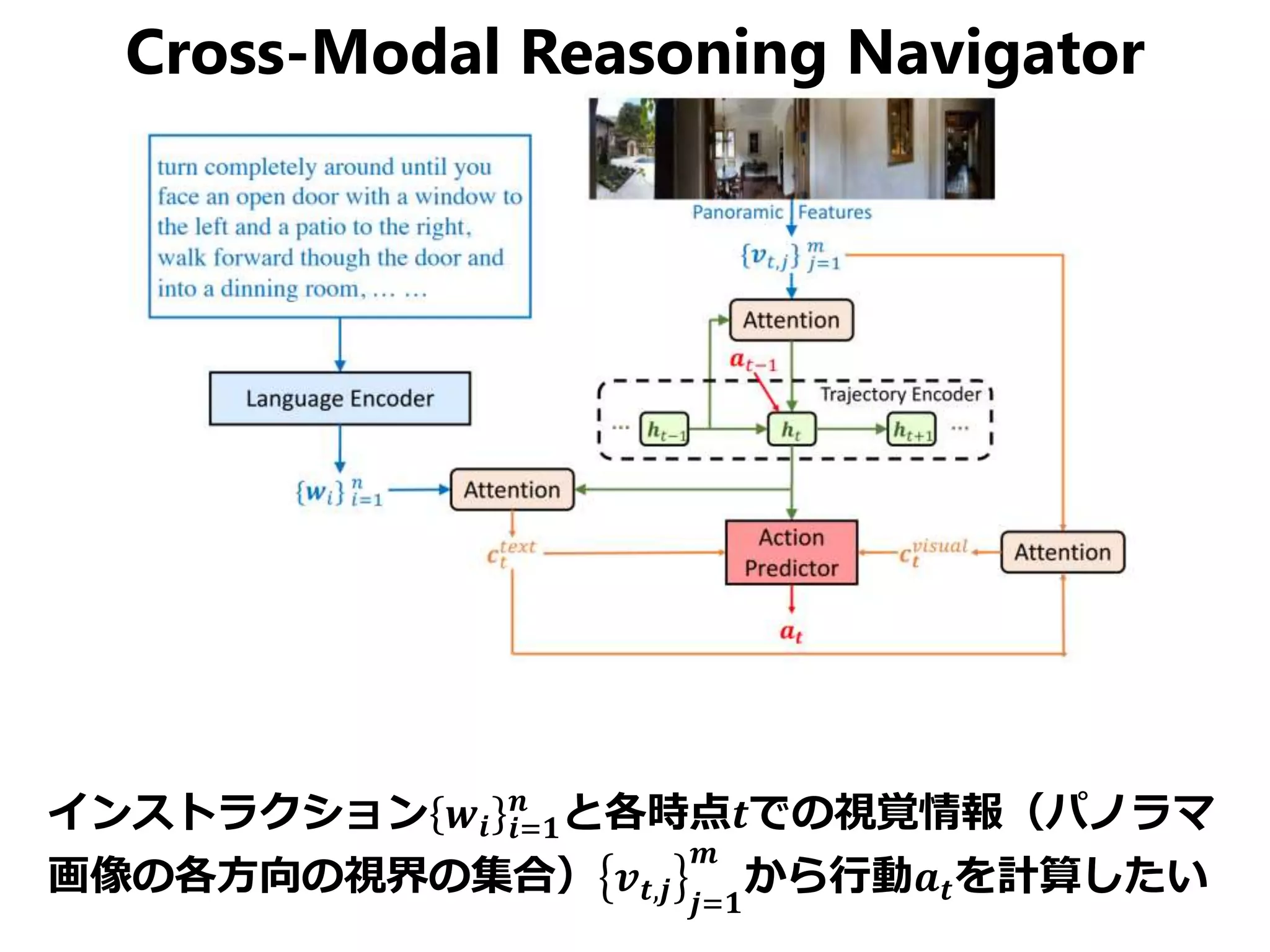
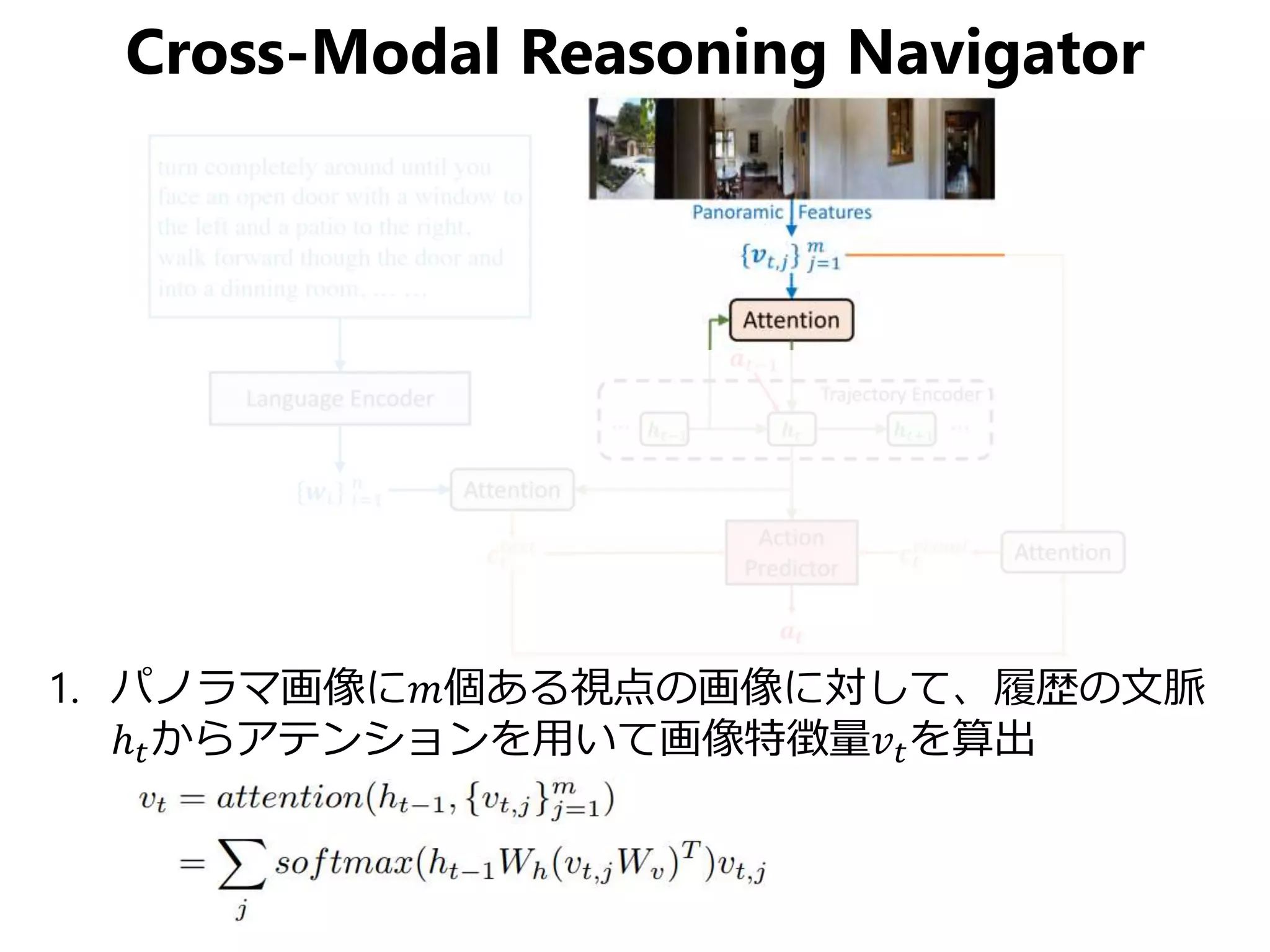
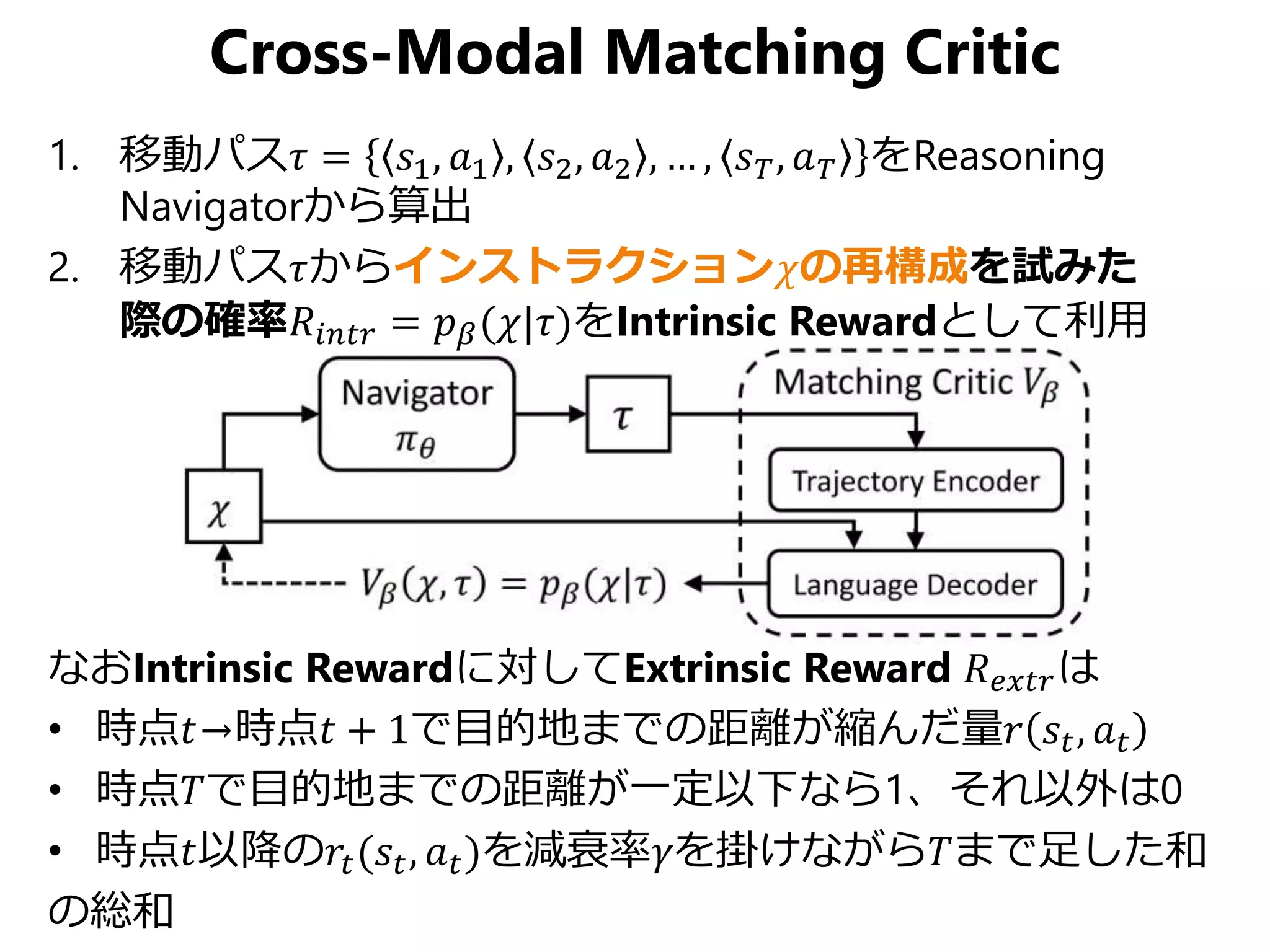
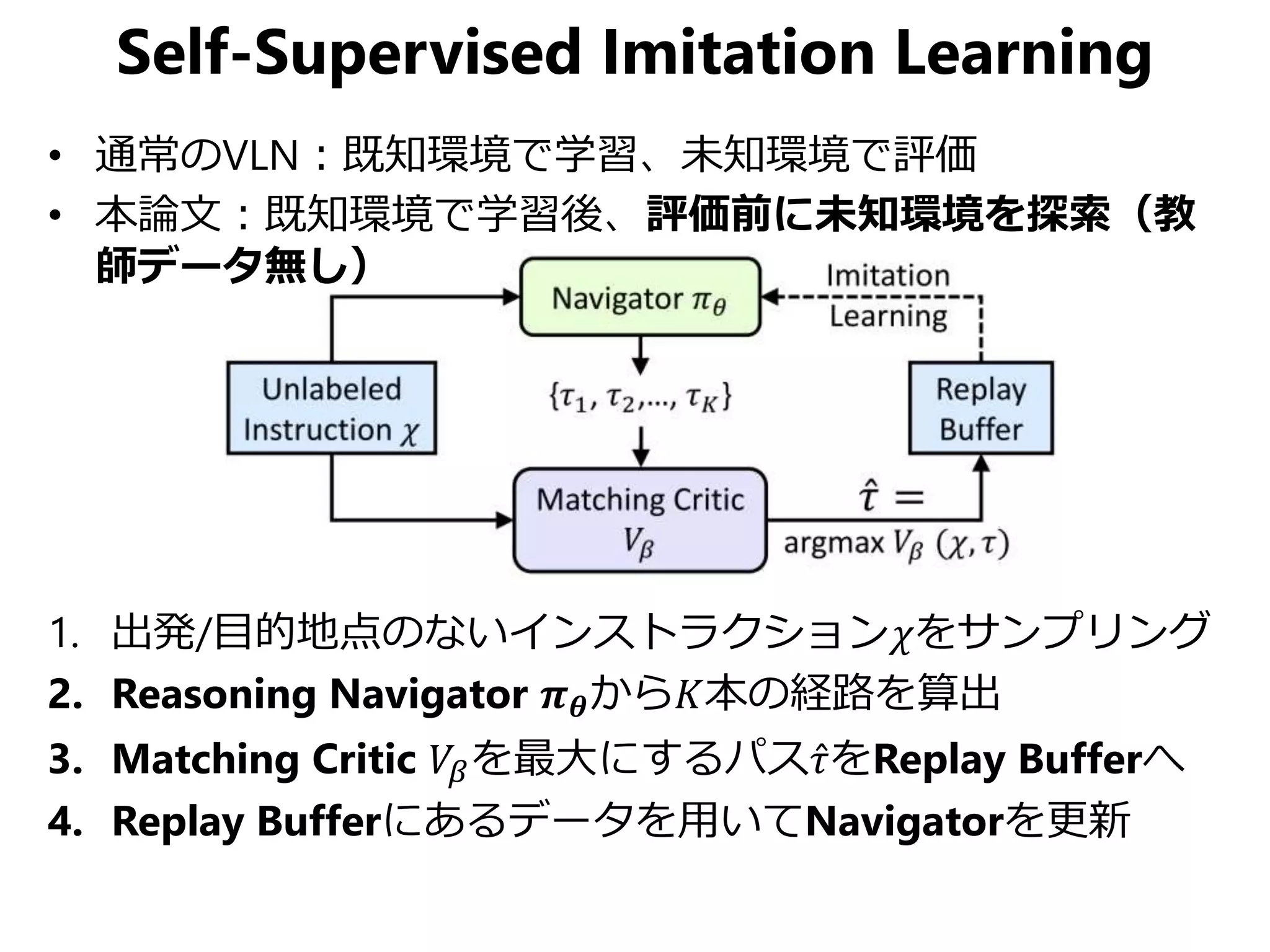
視覚を持ったエージェントに自然言語で屋内のある地点からある地点までの道順を教えると、エージェントが頑張って自力でゴールまでたどり着けるというのが Vision-Language Navigation の目的です。 この論文はCVPR 2019のStudent Best Paperに輝いた論文で、上記の問題に対して局所的パスと大局的パス両方にクロスモーダルなマッチングを与えるReinforced Cross-Modal Matchingと未知環境下で自己教示的に模倣学習するSelf-Supervised Imitation Learningを提案しています。Vision & Languageや強化学習、模倣学習、自己教示など今注目をあびる要素の集大成みたいな論文ですね。








![[解説スライド] NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis](https://cdn.slidesharecdn.com/ss_thumbnails/nerf20200327slideshare-200326131430-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DL輪読会]GLEAN: Generative Latent Bank for Large-Factor Image Super-Resolution](https://cdn.slidesharecdn.com/ss_thumbnails/20220225akitarevised1-220225034636-thumbnail.jpg?width=640&height=640&fit=bounds)

![タクシーxAIを支えるKubernetesとAIデータパイプラインの信頼性の取り組みについて [SRE NEXT 2020]](https://cdn.slidesharecdn.com/ss_thumbnails/202001srenext-200125032719-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Adversarial Feature Matching for Text Generation](https://cdn.slidesharecdn.com/ss_thumbnails/dljp170707-170707035929-thumbnail.jpg?width=640&height=640&fit=bounds)



![[Dl輪読会]dl hacks輪読](https://cdn.slidesharecdn.com/ss_thumbnails/dldlhacks-161125051944-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]Temporal Abstraction in NeurIPS2019](https://cdn.slidesharecdn.com/ss_thumbnails/20191115-191112082849-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Temporal DifferenceVariationalAuto-Encoder](https://cdn.slidesharecdn.com/ss_thumbnails/20181130new-190205051636-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Peeking into the Future: Predicting Future Person Activities and Locat...](https://cdn.slidesharecdn.com/ss_thumbnails/dl0531-190531000833-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会] “Asymmetric Tri-training for Unsupervised Domain Adaptation (ICML2017...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacks20170728-170728025901-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Imagination-Augmented Agents for Deep Reinforcement Learning / Learnin...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacksshioya201707281-170728054152-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]“SimPLe”,“Improved Dynamics Model”,“PlaNet” 近年のVAEベース系列モデルの進展とそのモデルベース...](https://cdn.slidesharecdn.com/ss_thumbnails/20190426akuzawa-190426020057-thumbnail.jpg?width=640&height=640&fit=bounds)



























