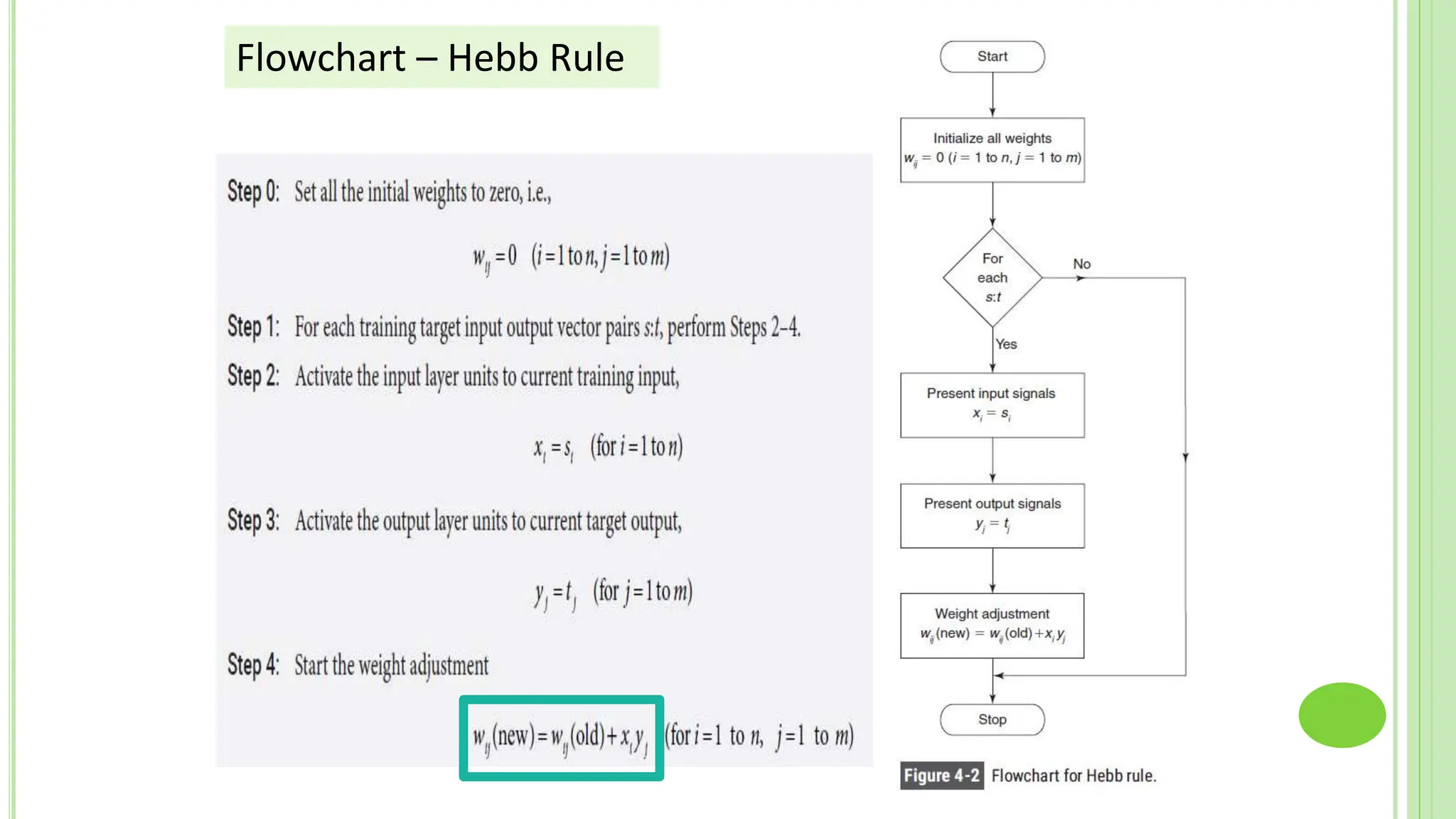
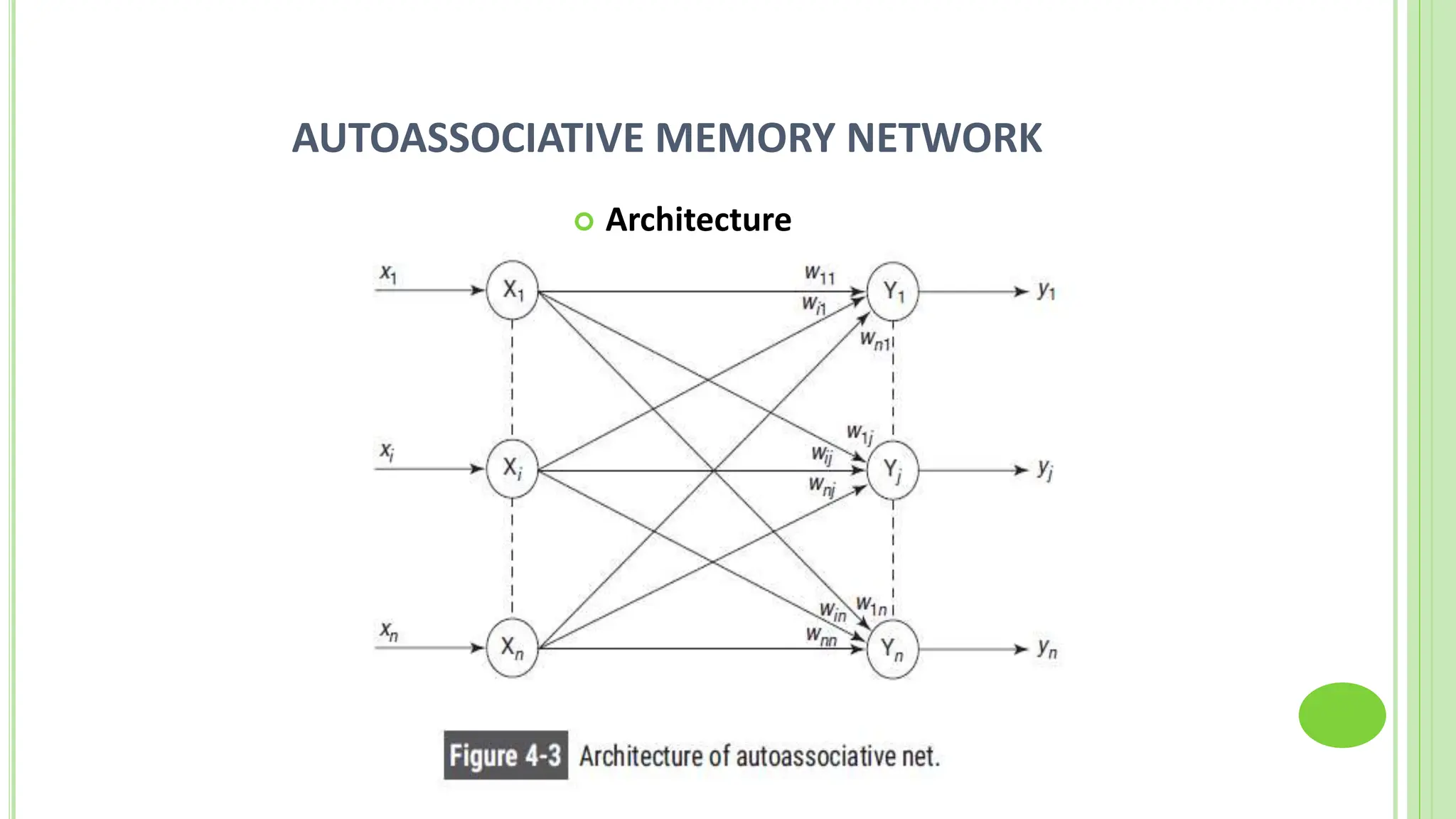
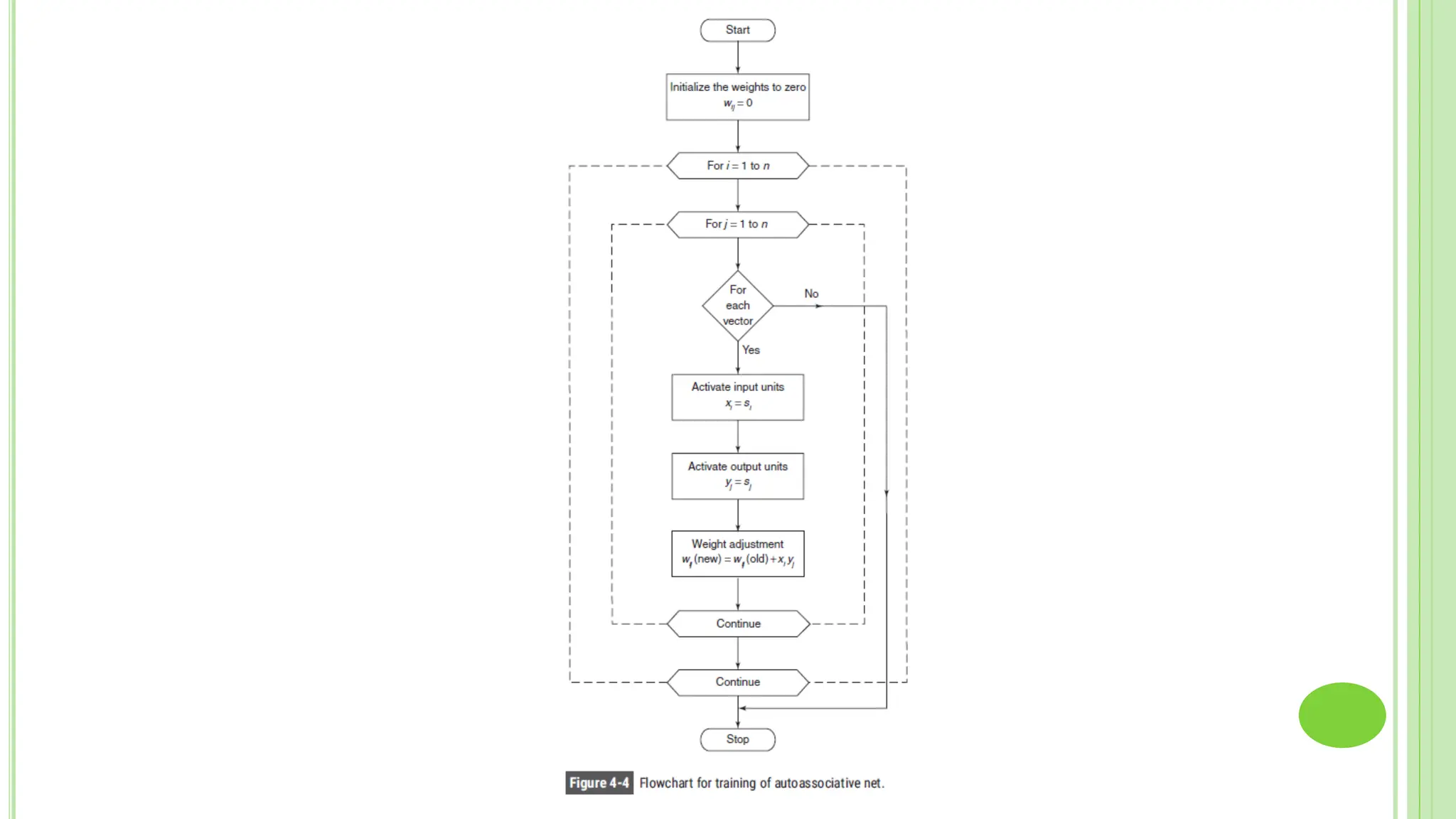
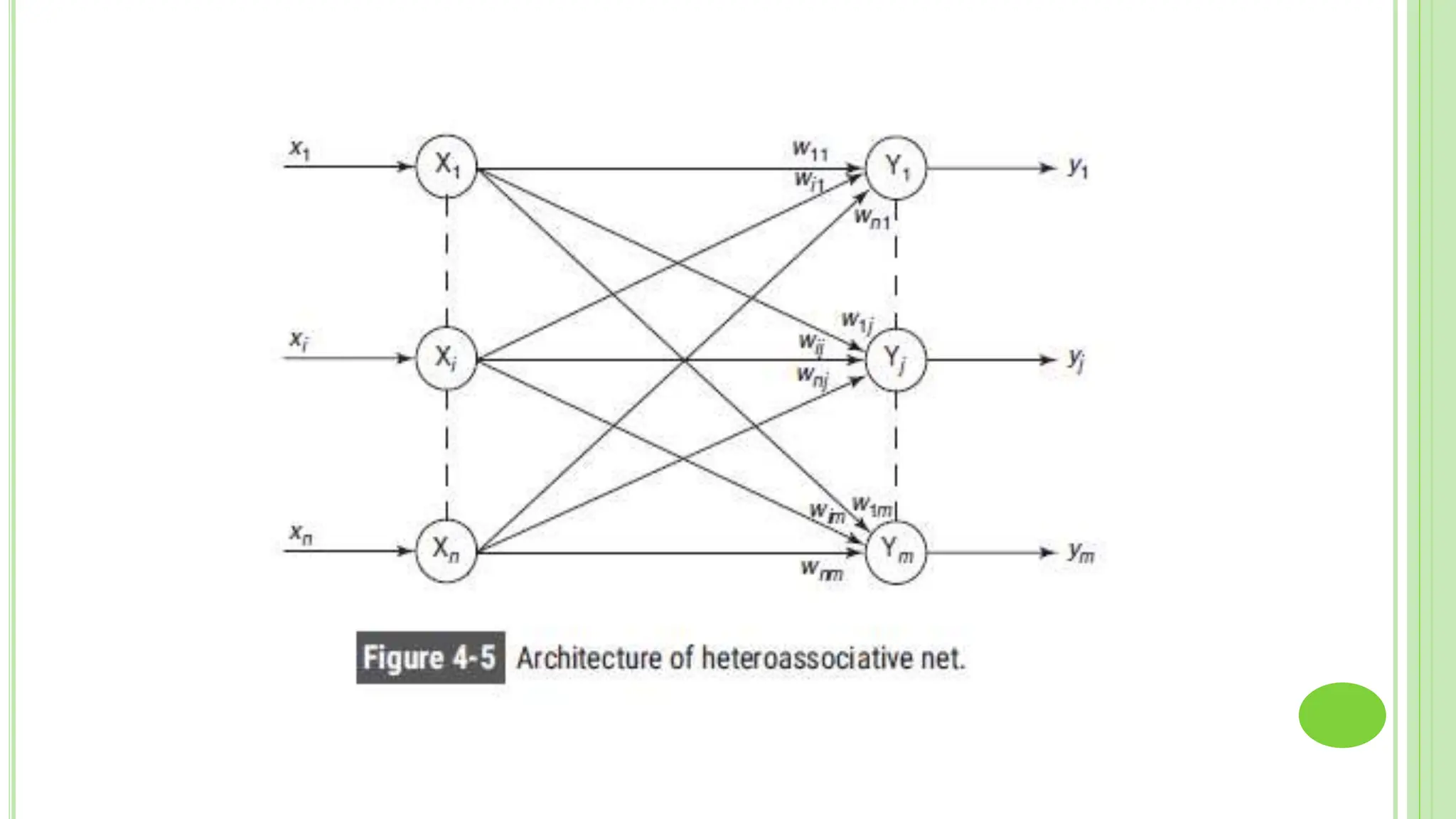
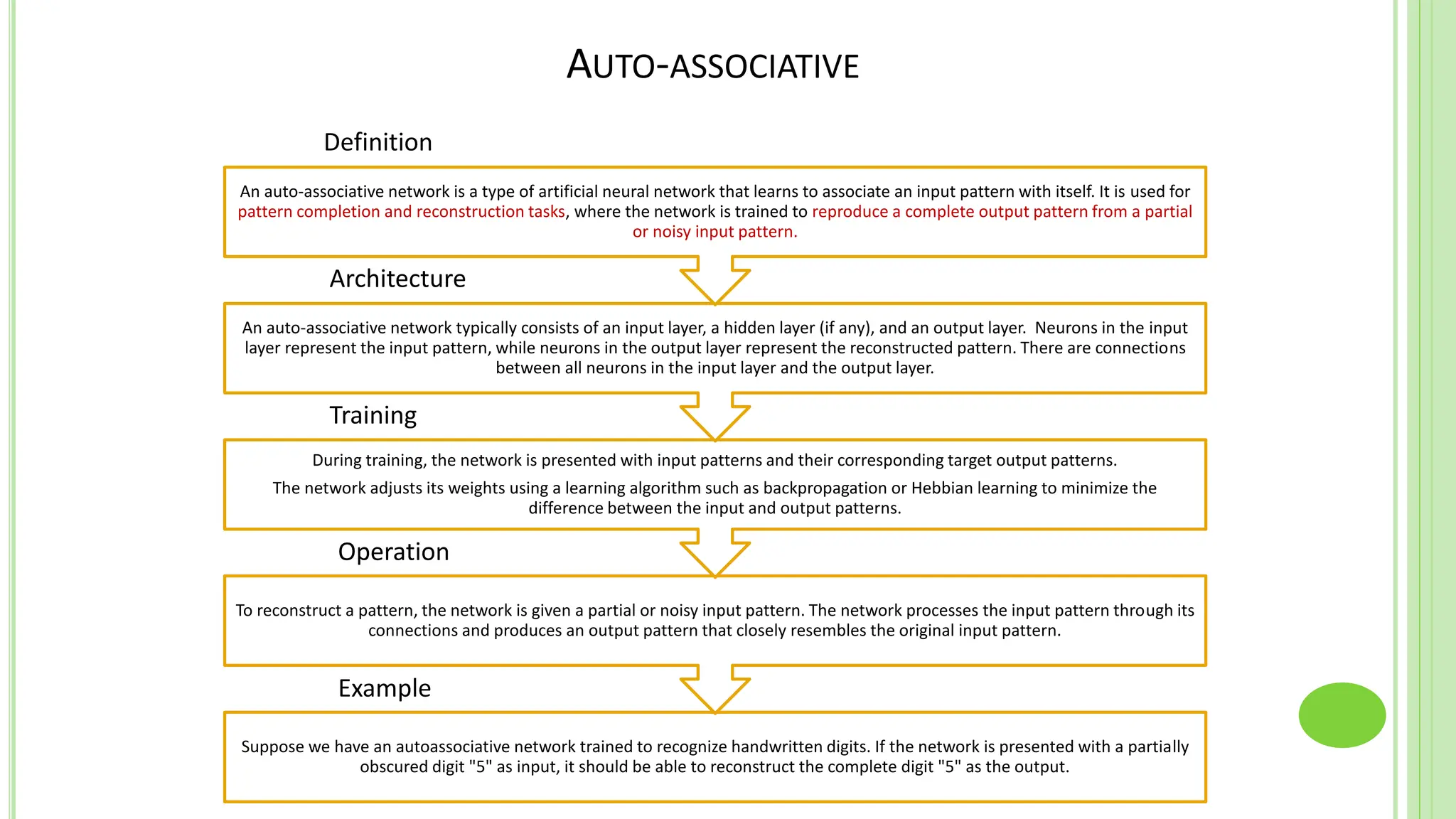
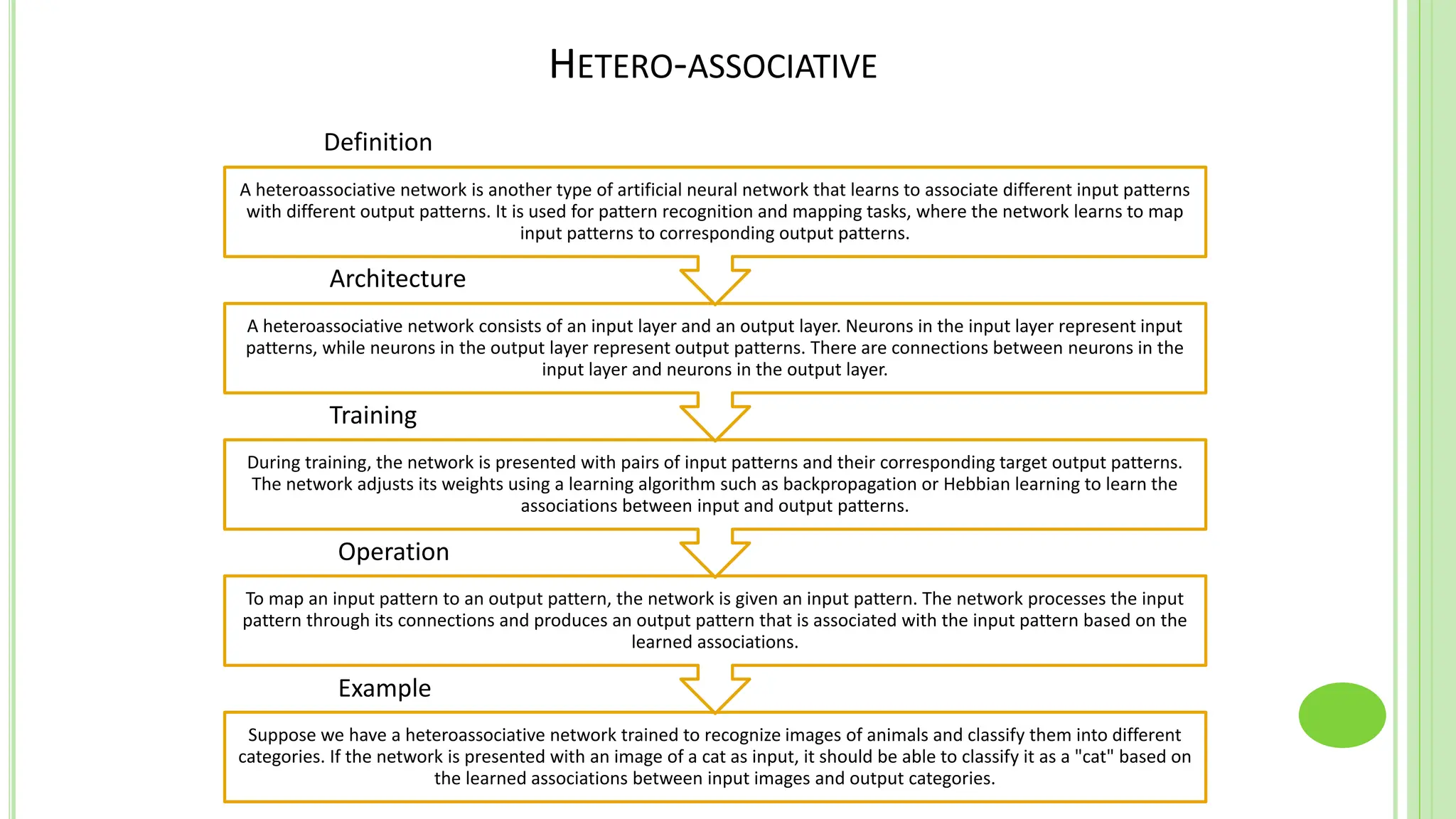
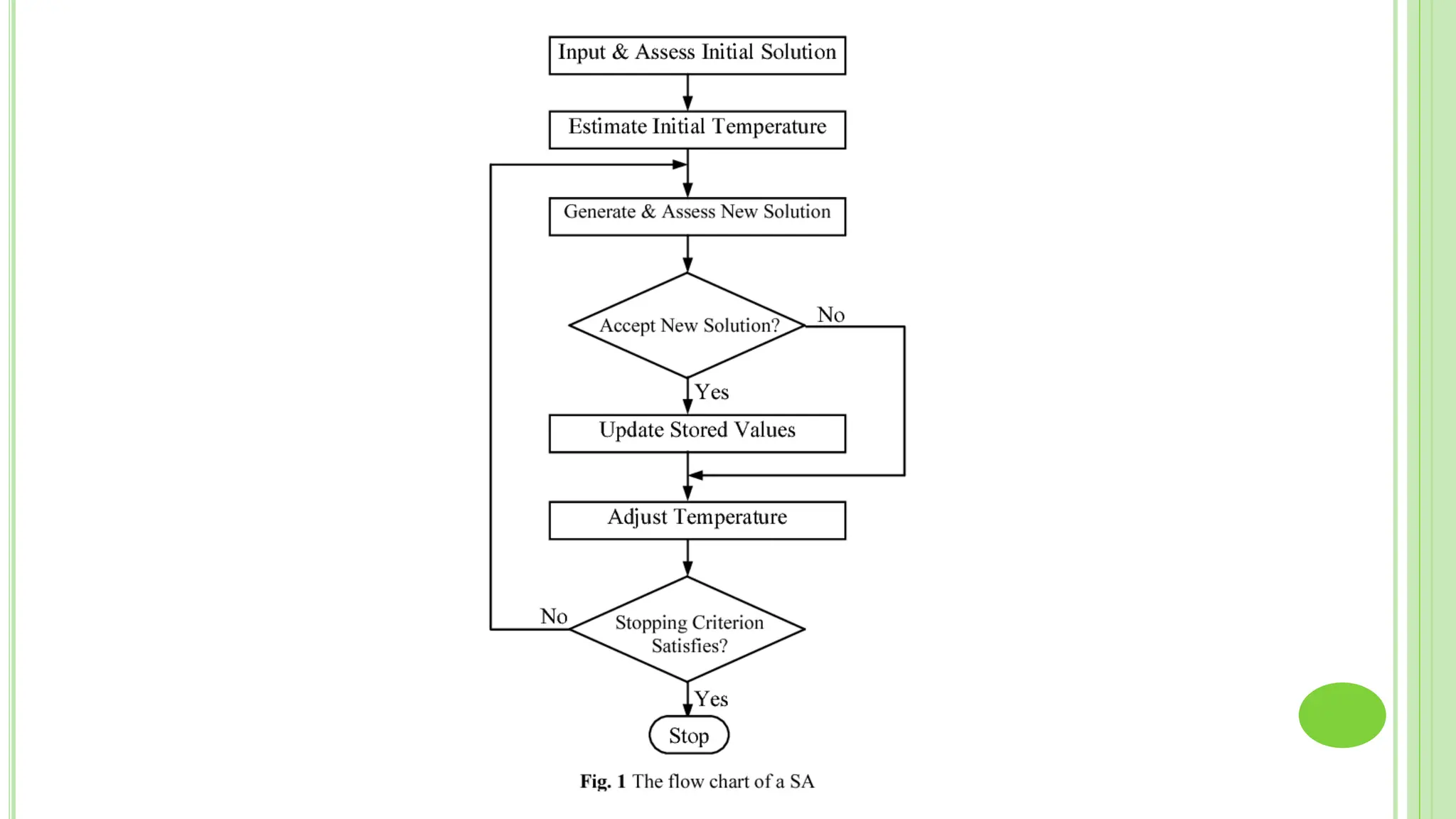
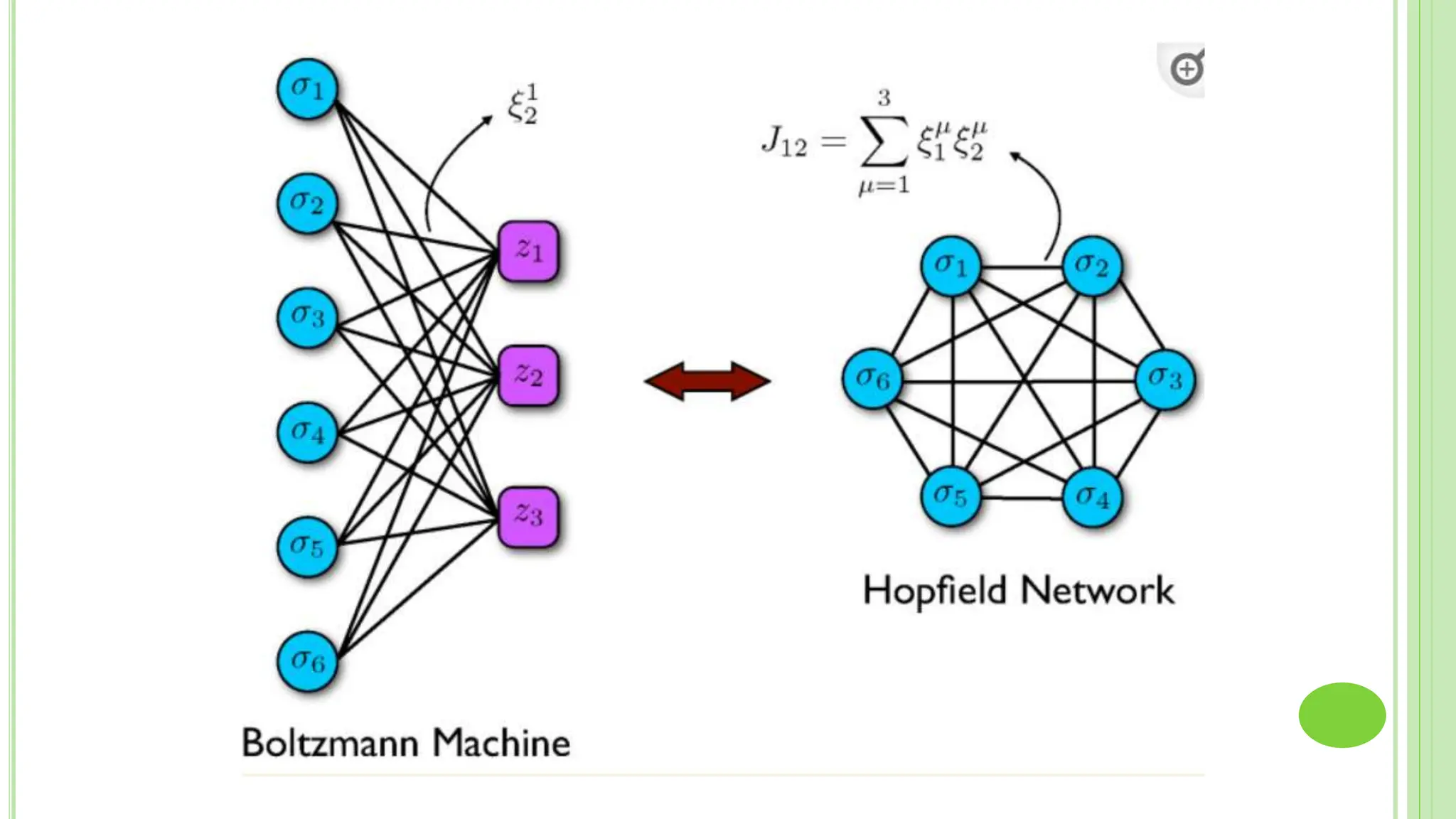
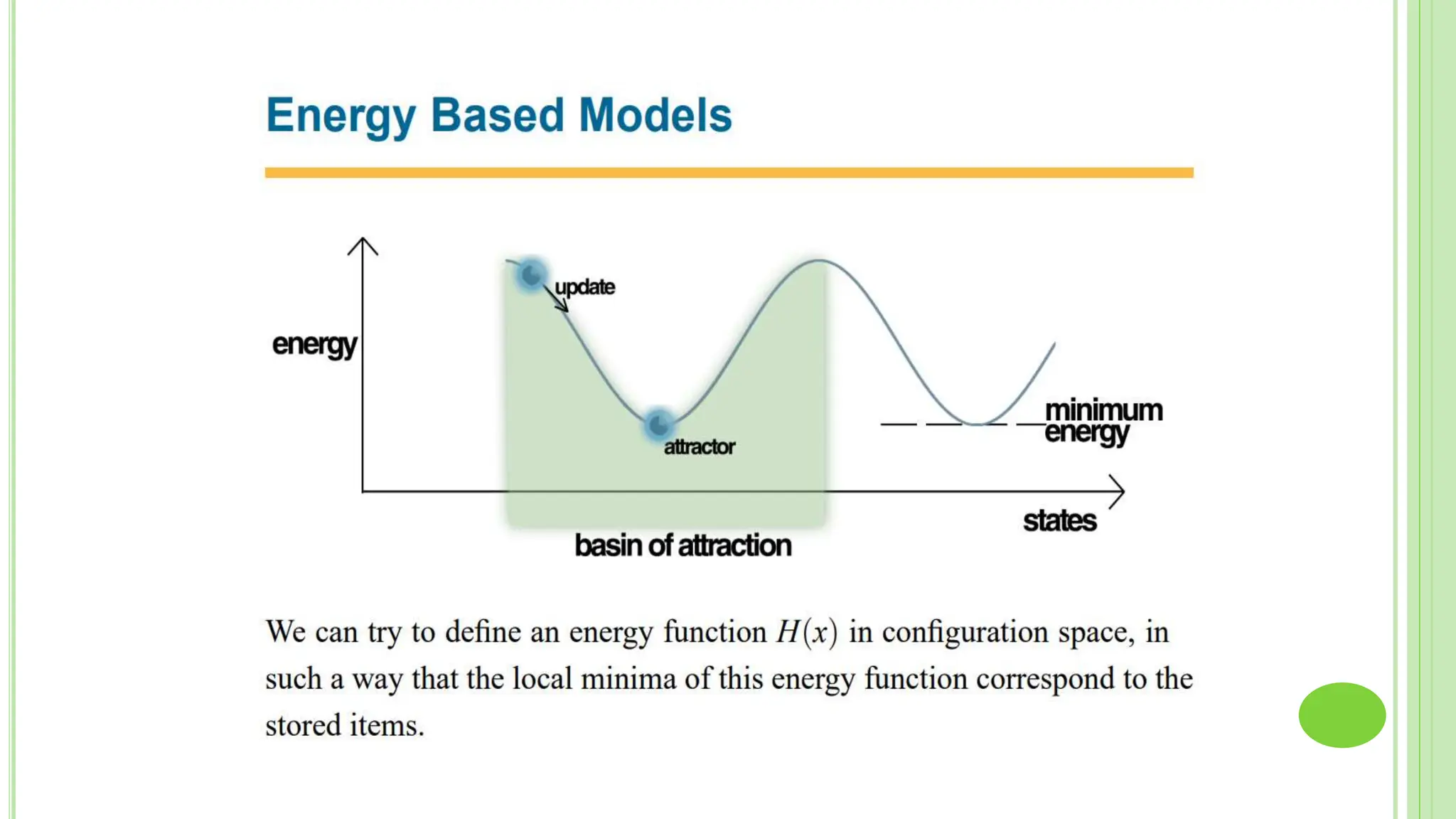
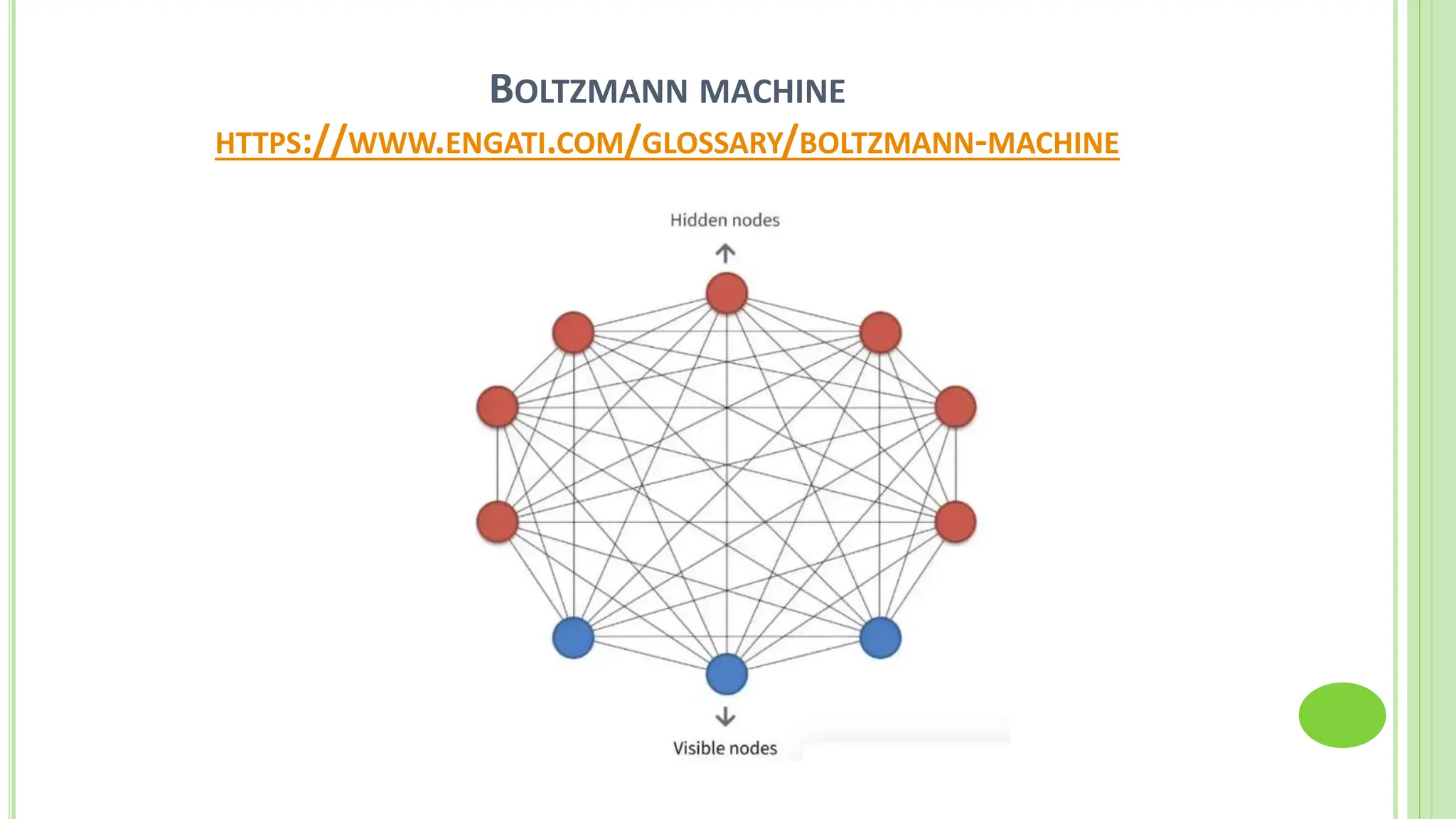
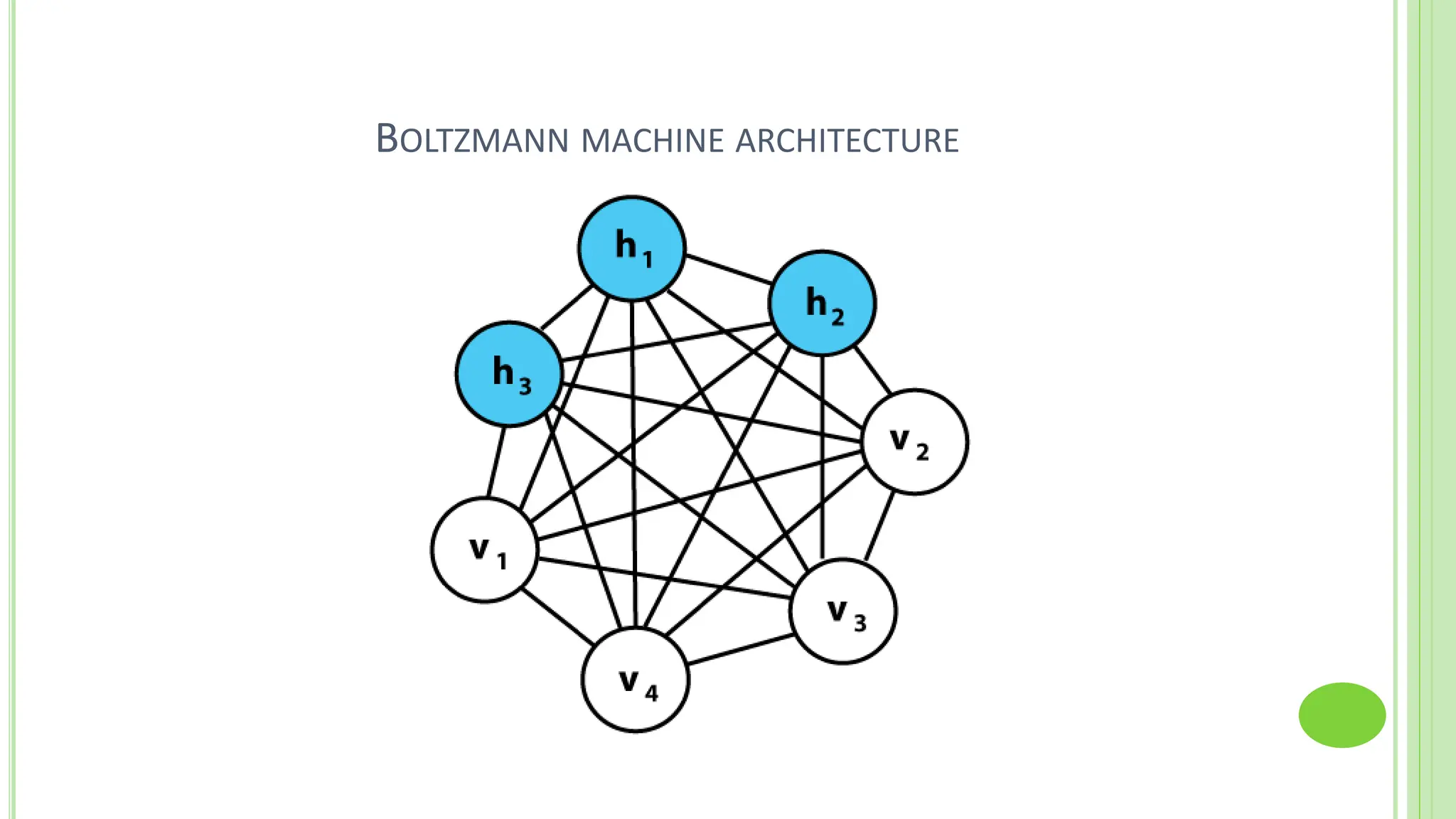
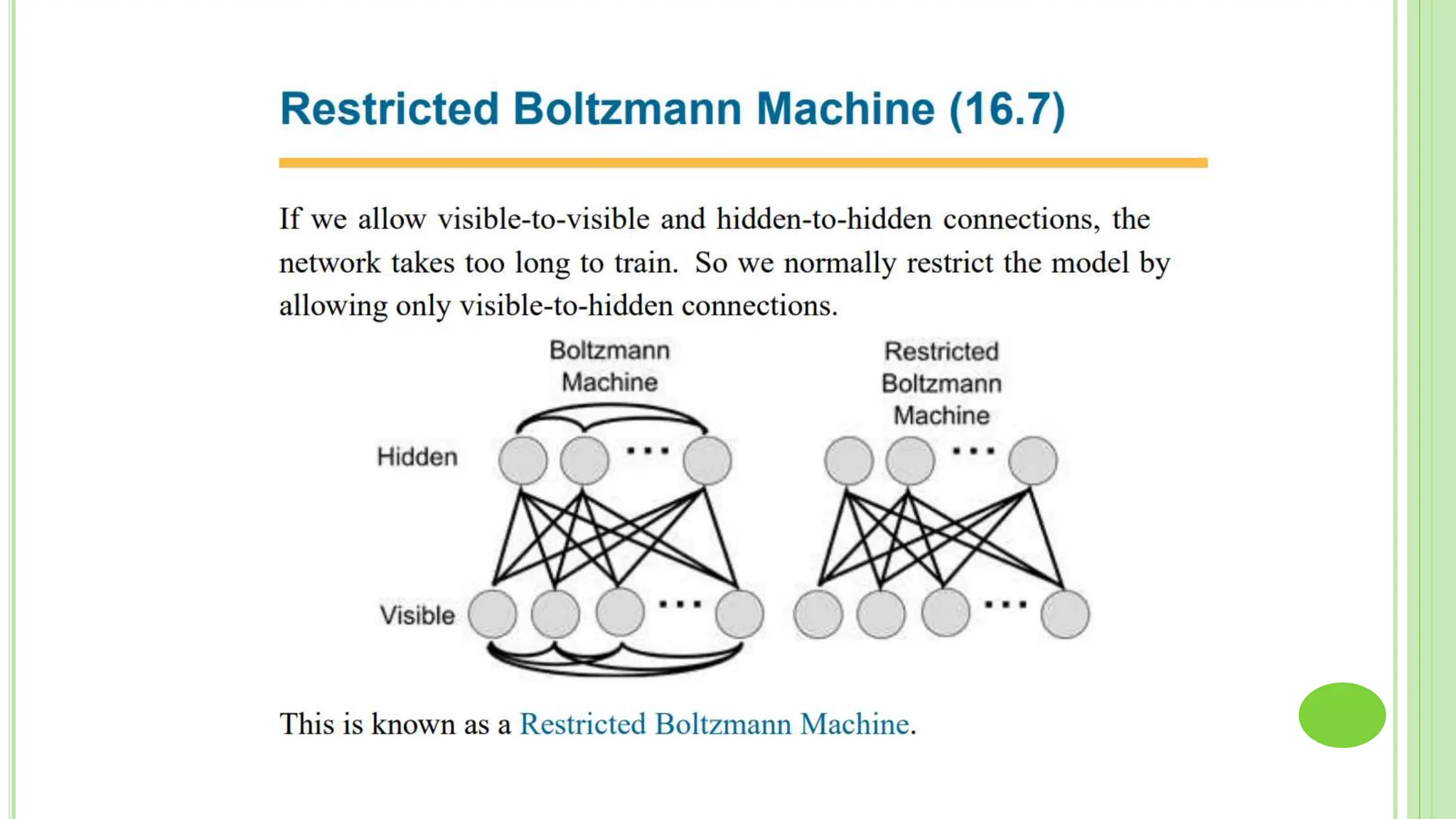
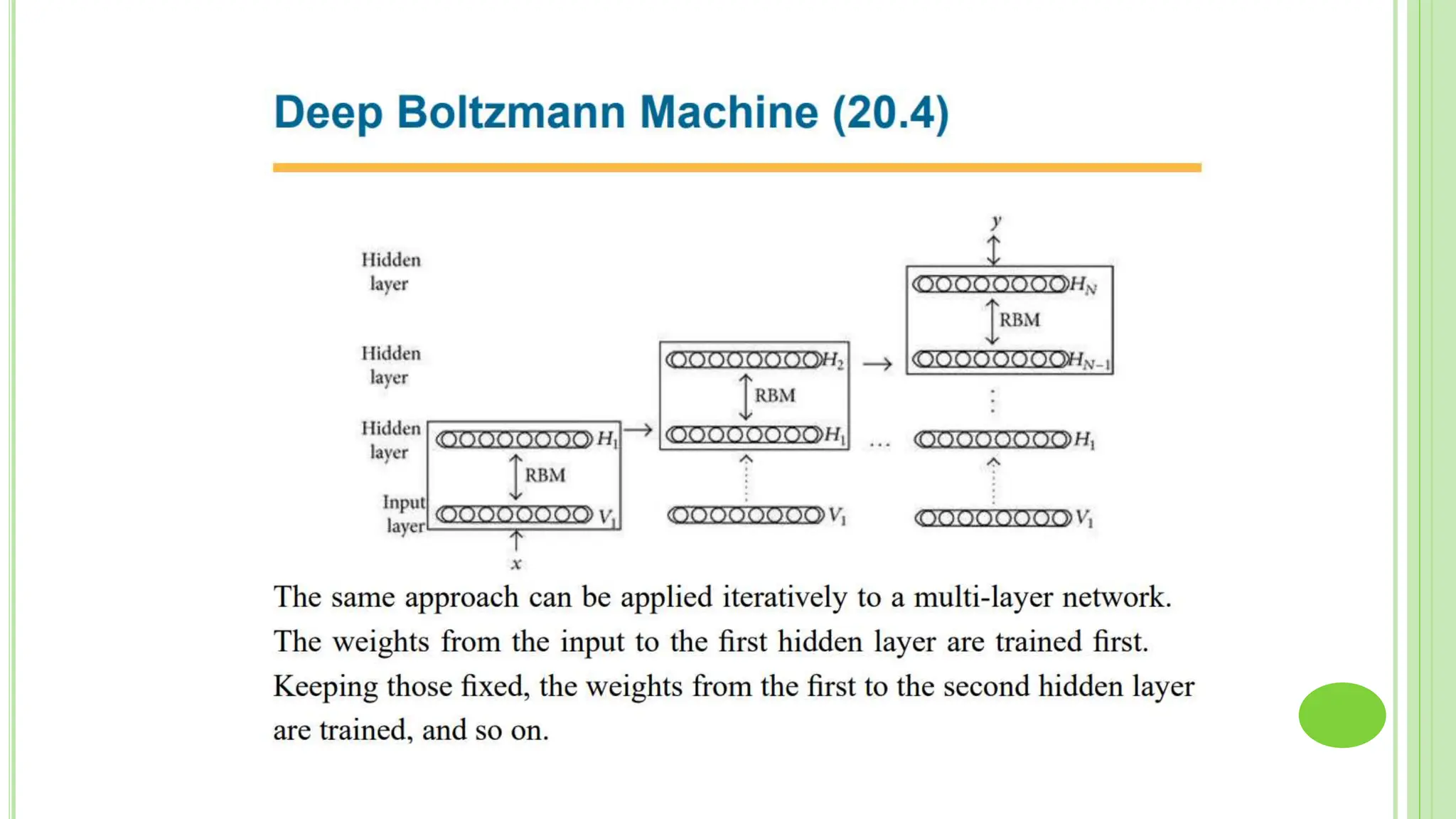
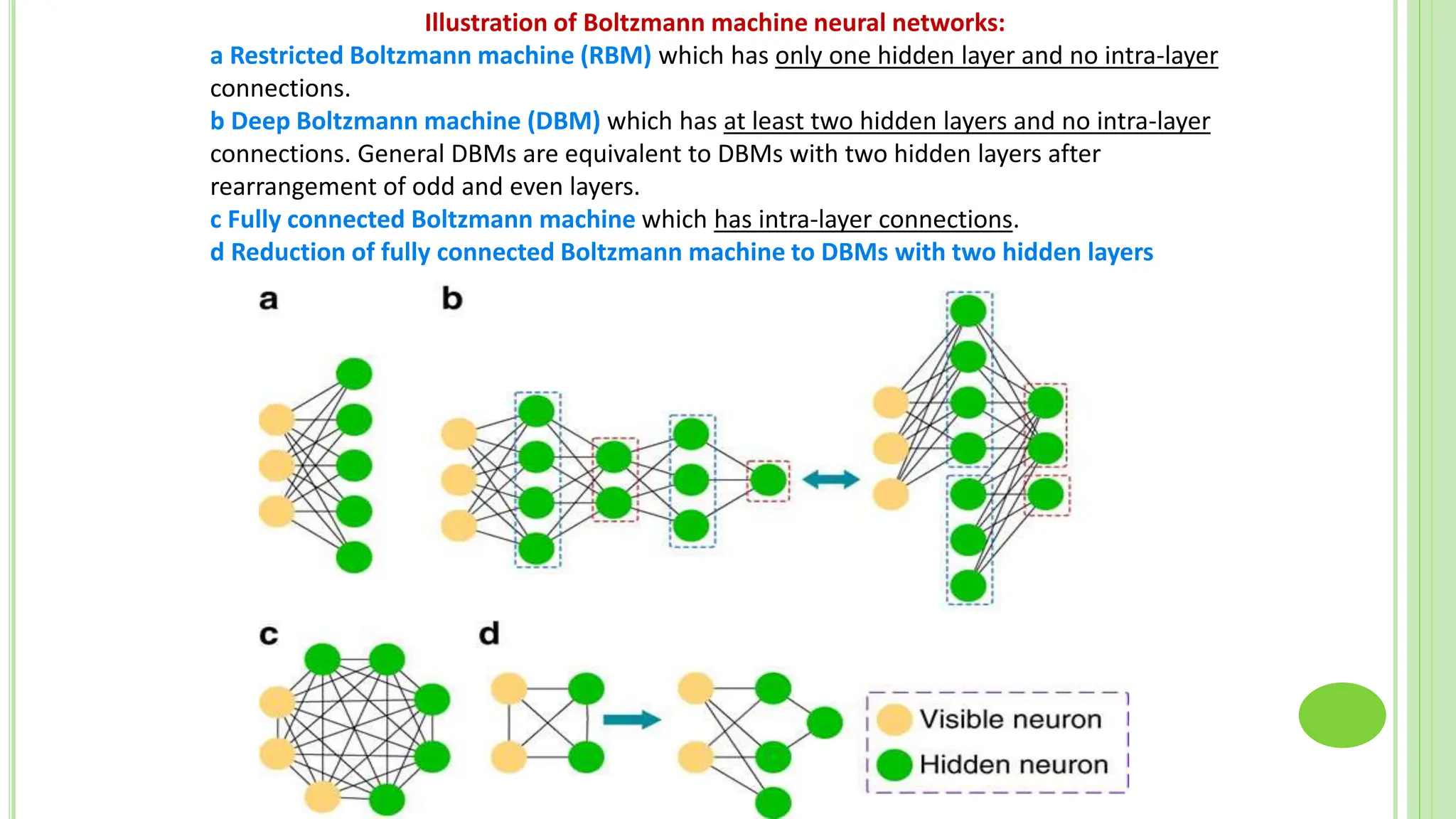
The document discusses associative learning and its applications in artificial neural networks, focusing on concepts like Hopfield networks, Boltzmann machines, and their training algorithms. It outlines key course objectives, outcomes, and features of different types of associative memories, including auto-associative and hetero-associative networks, while emphasizing their noise-resistance and pattern recognition capabilities. Additionally, the text elaborates on optimization techniques such as simulated annealing and the role of temperature in Boltzmann machines.











































































































































![ANPARA THERMAL POWER STATION[1] sangam.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/anparathermalpowerstation1sangam-251121115219-9261cde4-thumbnail.jpg?width=640&height=640&fit=bounds)





