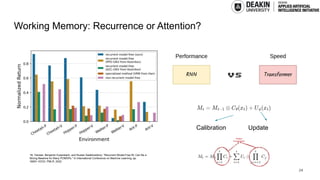
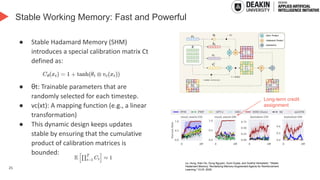
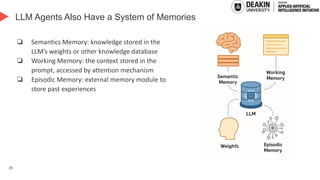
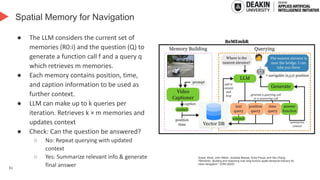
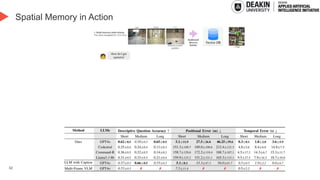
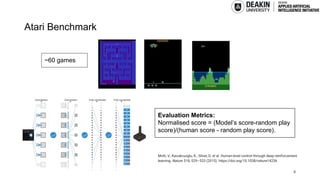
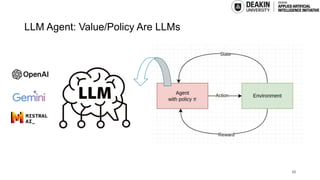
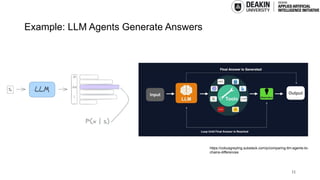
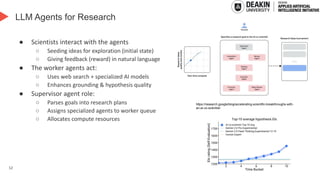
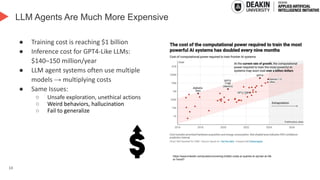
AI agents learn to make decisions by interacting with environments to achieve goals. Effective learning requires remembering and leveraging past experiences, yet many current AI agents lack efficient memory, leading to slow and resource-intensive training. This challenge is especially pronounced in complex or uncertain environments, where partial observability, noise, and long-term dependencies make learning and decision-making difficult. In this talk, we explore how memory mechanisms have evolved from classical reinforcement learning agents to modern large language model agents, enabling faster learning, richer context representation, and more strategic exploration. Understanding this progression provides valuable insights for designing more capable, adaptive, and sample-efficient AI agents that can better handle real-world challenges.











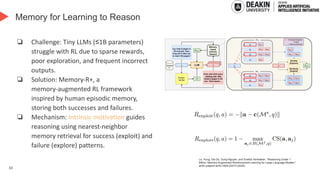
 (Do et al., ACL-Findings 2025)
Local steering
(episodic)
Global steering
(semantics)
Only need
10-100 samples!](https://image.slidesharecdn.com/memoryinautonomousagent-250829042513-d87addf1/85/Memory-in-Autonomous-Agents-From-Reinforcement-Learning-to-Large-Language-Models-21-320.jpg)