Downloaded 171 times


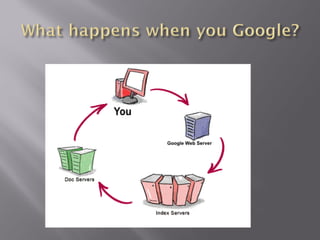
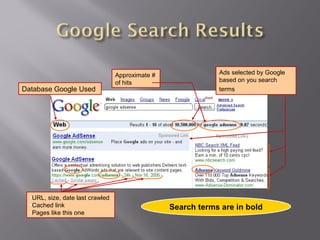
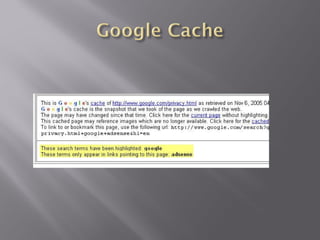





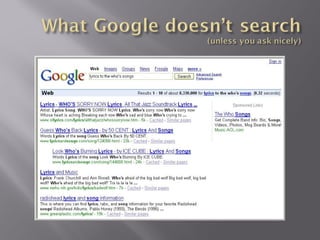













The document provides an in-depth overview of the Google search engine database, detailing metrics used in searches such as URL, size, cached links, and various search term techniques including stemming and the inclusion/exclusion of words. It also describes advanced search operators to enhance query effectiveness, like 'intitle:', 'site:', and filetype restrictions, along with tips for better search results. Additionally, it highlights resources for further information, like Google Guide and Google Librarian Center.
















































































