Download as PDF, PPTX













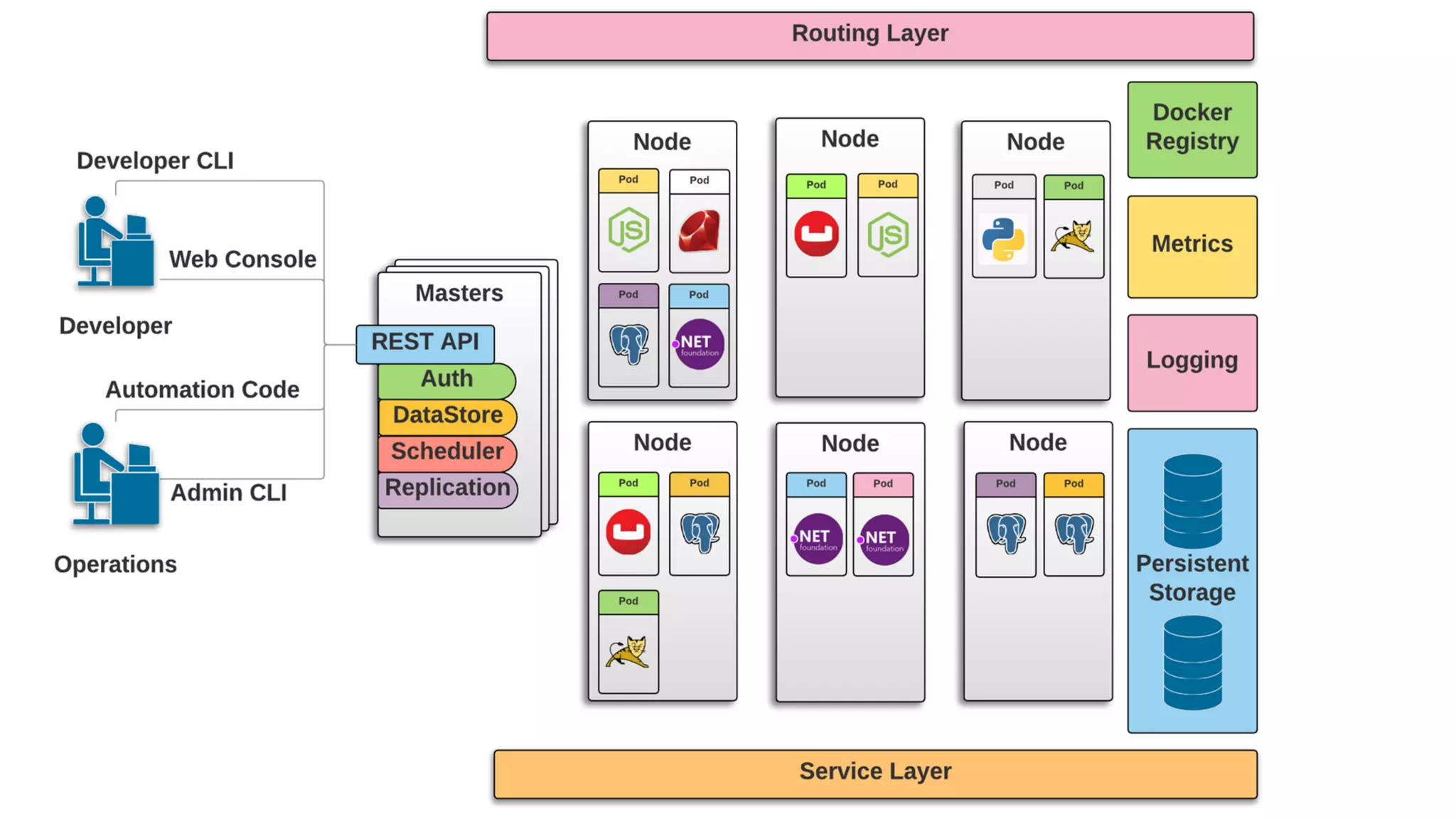




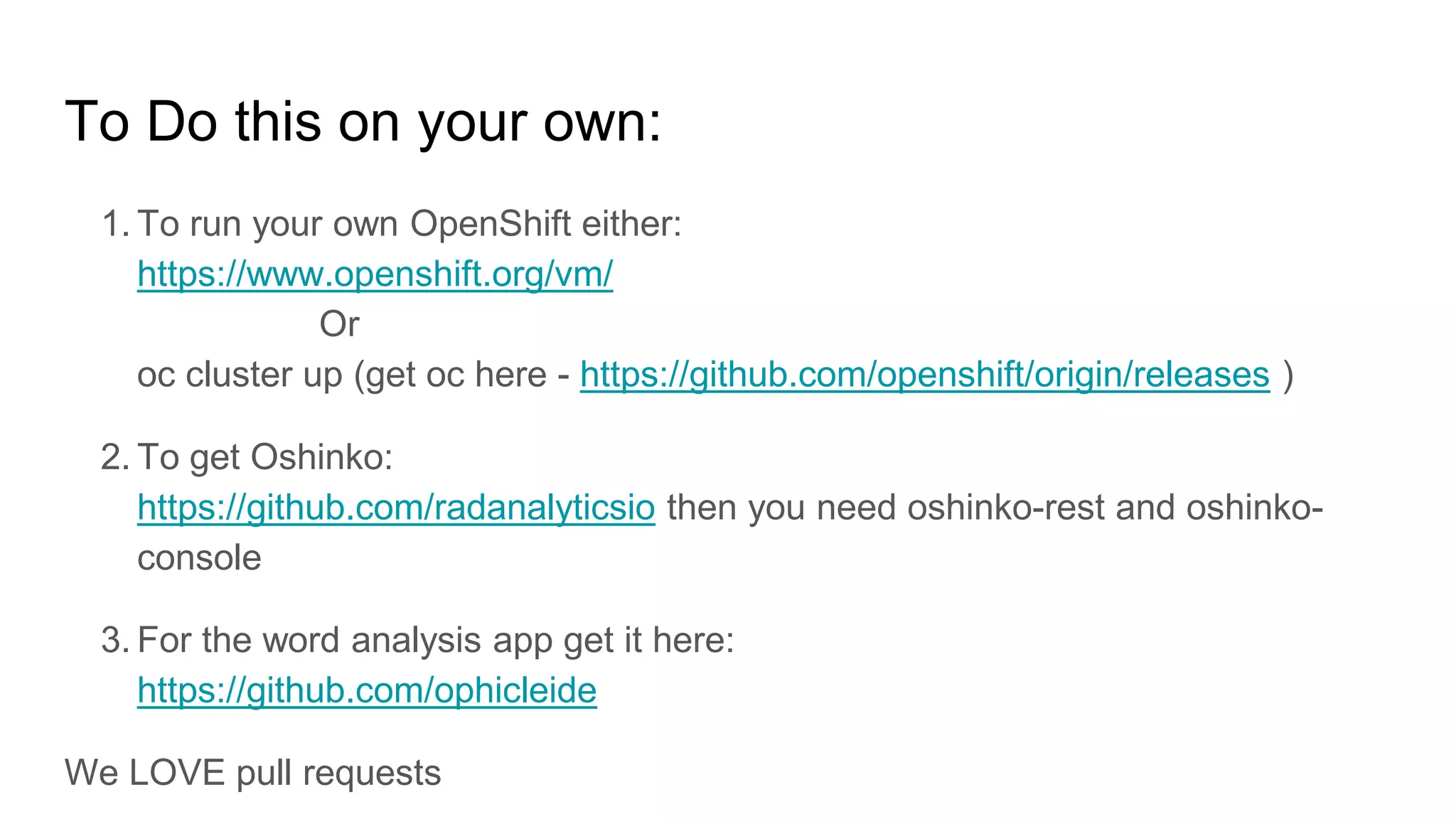


The document introduces the evolution of application infrastructure, highlighting advancements such as distributed software, easier programming languages, and improved statistical libraries. It emphasizes the integration of big data, APIs, and machine learning with web applications using tools like Docker, Kubernetes, and OpenShift. The document provides resources for setting up OpenShift and related tools for analysis and encourages contributions through pull requests.


























































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)







![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)






