Download as PDF, PPTX



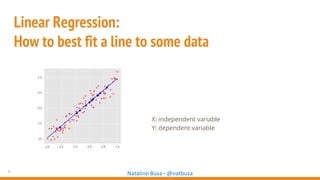


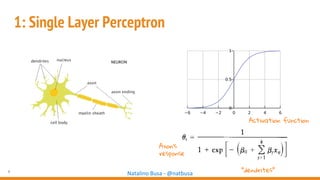

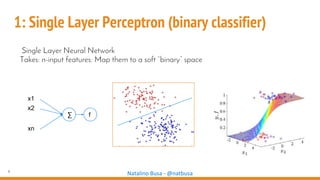


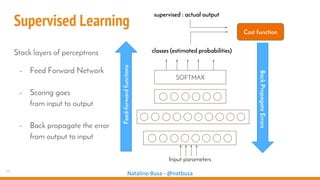



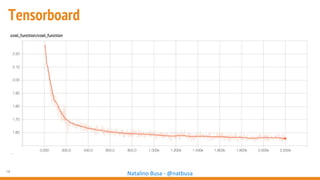



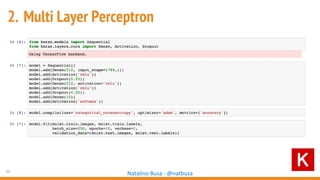
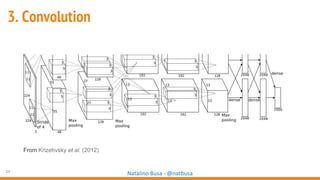
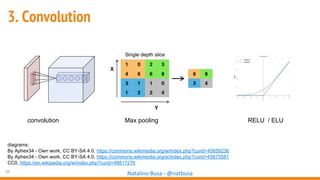

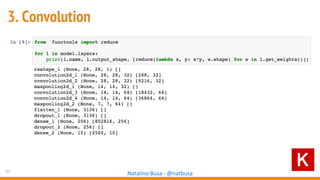



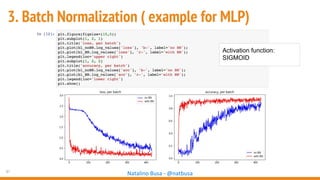
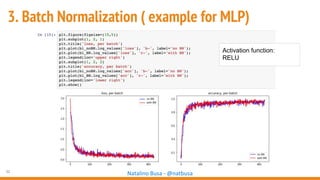

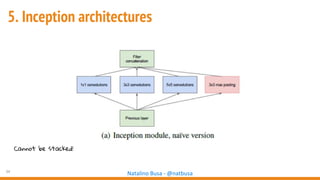

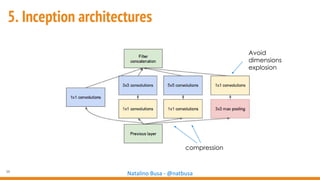


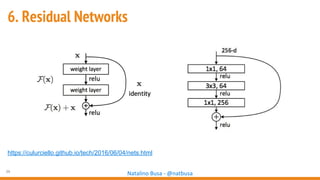

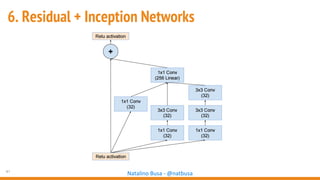
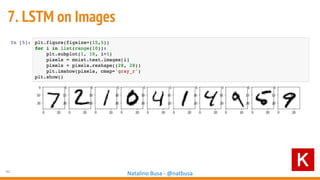
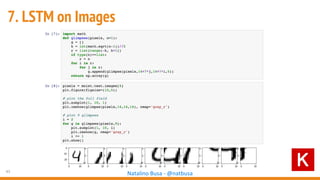
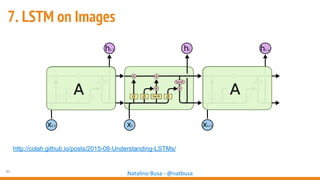
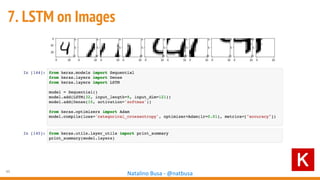
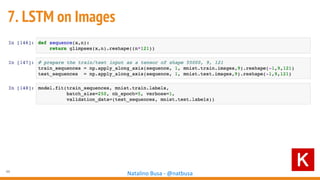



The document outlines seven essential steps for creating effective deep neural networks, beginning with the single layer perceptron and moving through multi-layer perceptrons, convolutional networks, and regularization techniques. It emphasizes the importance of batch normalization, inception architectures, and residual networks, culminating in the use of LSTM for image processing. Additionally, it provides various references and resources for further learning in neural network design and implementation.





























![[Ai in finance] AI in regulatory compliance, risk management, and auditing](https://cdn.slidesharecdn.com/ss_thumbnails/aiinfinanceaiinregulatorycomplianceriskmanagementandauditing1-161109114320-thumbnail.jpg?width=640&height=640&fit=bounds)































