Download to read offline















![20
ü Helping to select the right tool for
preprocessing or analysis
ü Making use of humans’ abilities to
recognize patterns
Not always sure what we are looking for (until we find it)
Query expression [guidance ∣ automatic generation]3,2
• Multi-scale query processing for gradual exploration
• Query morphing to adjust for proximity results
• Queries as answers: query alternatives to cope with lack of providence
Results filtering, analysis, visualization2
• Result-set post processing for conveying meaningful data
Data exploration systems & environments1
• Data systems kernels are tailored for data exploration: no preparation easy-to-use fast database
cracking
• Auto-tuning database kernels : incremental, adaptive, partial indexing
1. Xi, S. L., Babarinsa, O., Wasay, A., Wei, X., Dayan, N., & Idreos, S. (2017, May). Data canopy: Accelerating exploratory statistical analysis. In Proceedings of the 2017 ACM International Conference on Management of Data (pp. 557-572). ACM.
2. Athanassoulis, M., & Idreos, S. (2015, May). Beyond the wall: Near-data processing for databases. In Proceedings of the 11th International Workshop on Data Management on New Hardware (p. 2). ACM.
3. Idreos, S., Dayan, M. A. N., Guo, D., Kester, M. S., Maas, L., & Zoumpatianos, K. Past and Future Steps for Adaptive Storage Data Systems: From Shallow to Deep Adaptivity.
KEY MOTIVATIONS
EXPLORING DATA COLLECTIONS](https://image.slidesharecdn.com/vargas-solar-final-181116144114/75/Moving-forward-data-centric-sciences-weaving-AI-Big-Data-HPC-18-2048.jpg)




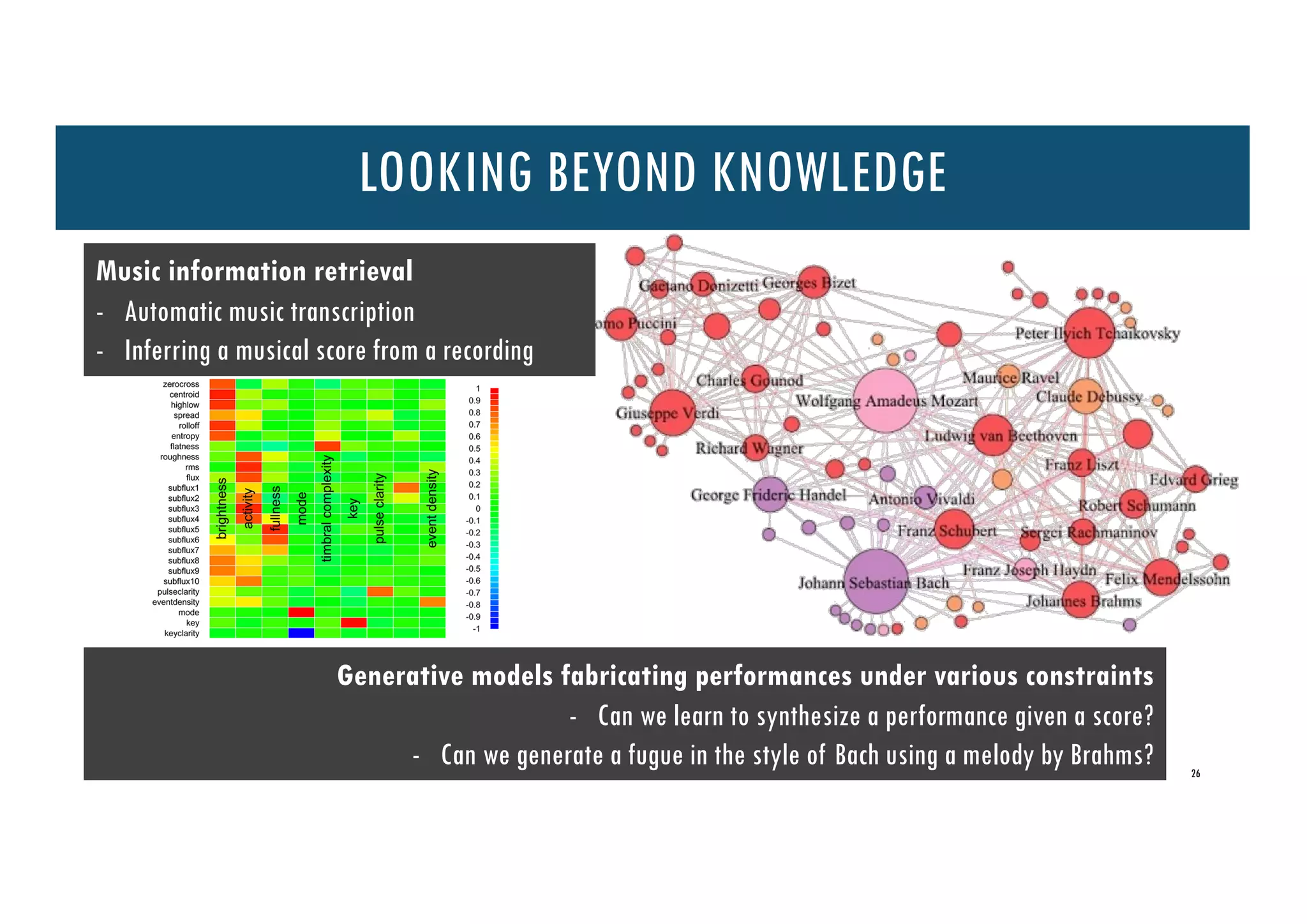













The document discusses the interplay between data-centric sciences, artificial intelligence, and high-performance computing (HPC), emphasizing the role of big data in transforming reality and enhancing decision-making. It covers methodologies for data analysis, the importance of computational frameworks, and the exploration of music information retrieval through various techniques like automatic music transcription. Furthermore, it highlights the need for efficient data management and processing to address complex scientific problems and support evidence-based conclusions.









































![[IJCT-V3I2P32] Authors: Amarbir Singh, Palwinder Singh](https://cdn.slidesharecdn.com/ss_thumbnails/ijct-v3i2p32-160609071950-thumbnail.jpg?width=640&height=640&fit=bounds)

















![[DSC Europe 25] Miodrag Pesovic & Vladislav Radonjic - Federated Data Archite...](https://cdn.slidesharecdn.com/ss_thumbnails/gsbe3y5it5uhndi4e08e-1-251212103249-f1008e0c-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Ivan Peric - Intelligence Swarm Logic and Techno-Functional M...](https://cdn.slidesharecdn.com/ss_thumbnails/7my7c97fsduiccadgavw-2-251212103249-5a03f7c6-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Bassam Maharmeh - Artificial Intelligence: Opportunities and ...](https://cdn.slidesharecdn.com/ss_thumbnails/thhfmr2fqpawzj7hsjpg-5-251211083048-2c23204f-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Debmalya Biswas - Agentification: the art of transforming man...](https://cdn.slidesharecdn.com/ss_thumbnails/r5azlggvtqiaiiusrqdr-4-251212103249-5a12c89b-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Marija Vlajkovic & Andrea Radonjanin - Integration of AI tool...](https://cdn.slidesharecdn.com/ss_thumbnails/qf1jrglttoc3bm8s3aop-final-integration-of-ai-tools-251208151905-394f3a6a-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Kaja Kandare - LLM as a judge.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/arxyccaxsdsd1ba99wjw-7-251212104007-2b4e3f64-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Dragana Ilic - AI for Big Data in Astronomy.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/8palya86qaatvjhva1ms-2-dragana-ilic-ai-ilic-251208151906-652b819c-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Jon Dajci - Bridging TradFi and DeFi: Building the Future of ...](https://cdn.slidesharecdn.com/ss_thumbnails/fqmhfvlbqhkihjvqvhmu-7-251211083849-6af7e325-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Hans Kleinsman - The Compliance Gearbox: How Tax Tech Mediate...](https://cdn.slidesharecdn.com/ss_thumbnails/dxdytie1toel0hr90bjs-2-251212103250-174fdbe7-thumbnail.jpg?width=640&height=640&fit=bounds)
