Downloaded 10 times







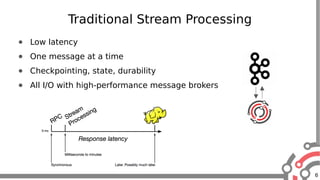
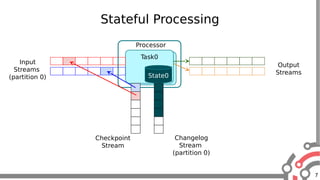
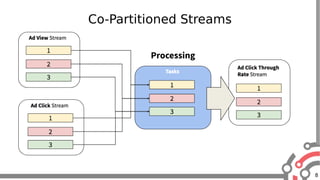
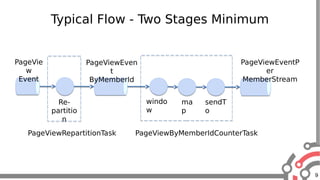

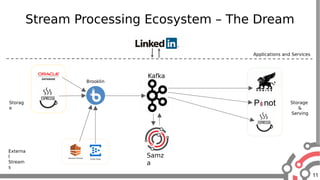
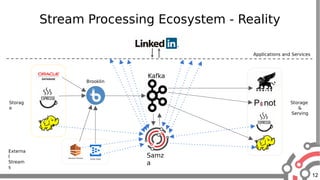
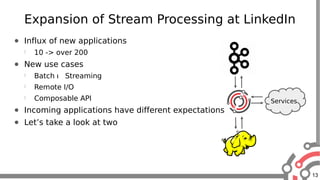

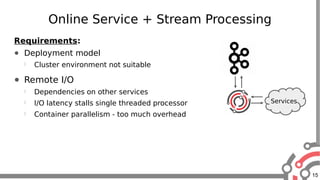
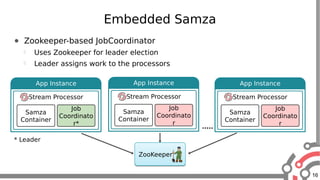
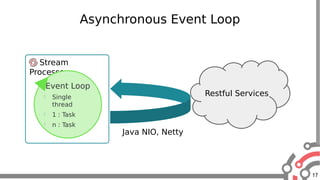
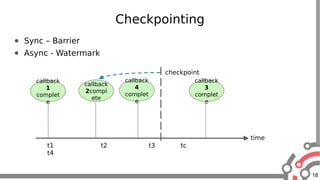
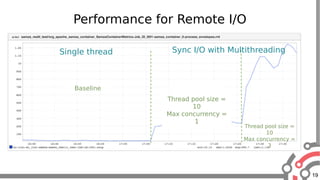
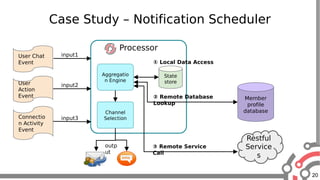




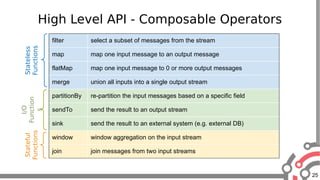

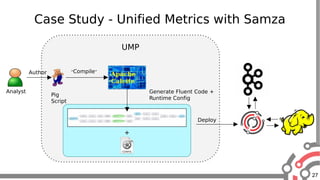
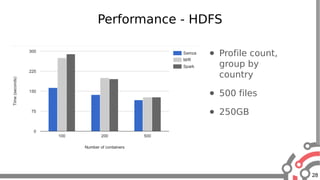




The document presents an overview of Apache Samza, a stream processing framework utilized at LinkedIn, highlighting its features such as scalability, low latency, and Kafka integration. It covers the stream processing ecosystem at LinkedIn, detailing use cases that integrate pre-existing services, batch and streaming processes, and future enhancements like SQL support and high-level API improvements. Additionally, it discusses performance considerations and architectural components within the context of stream processing applications.























































































