

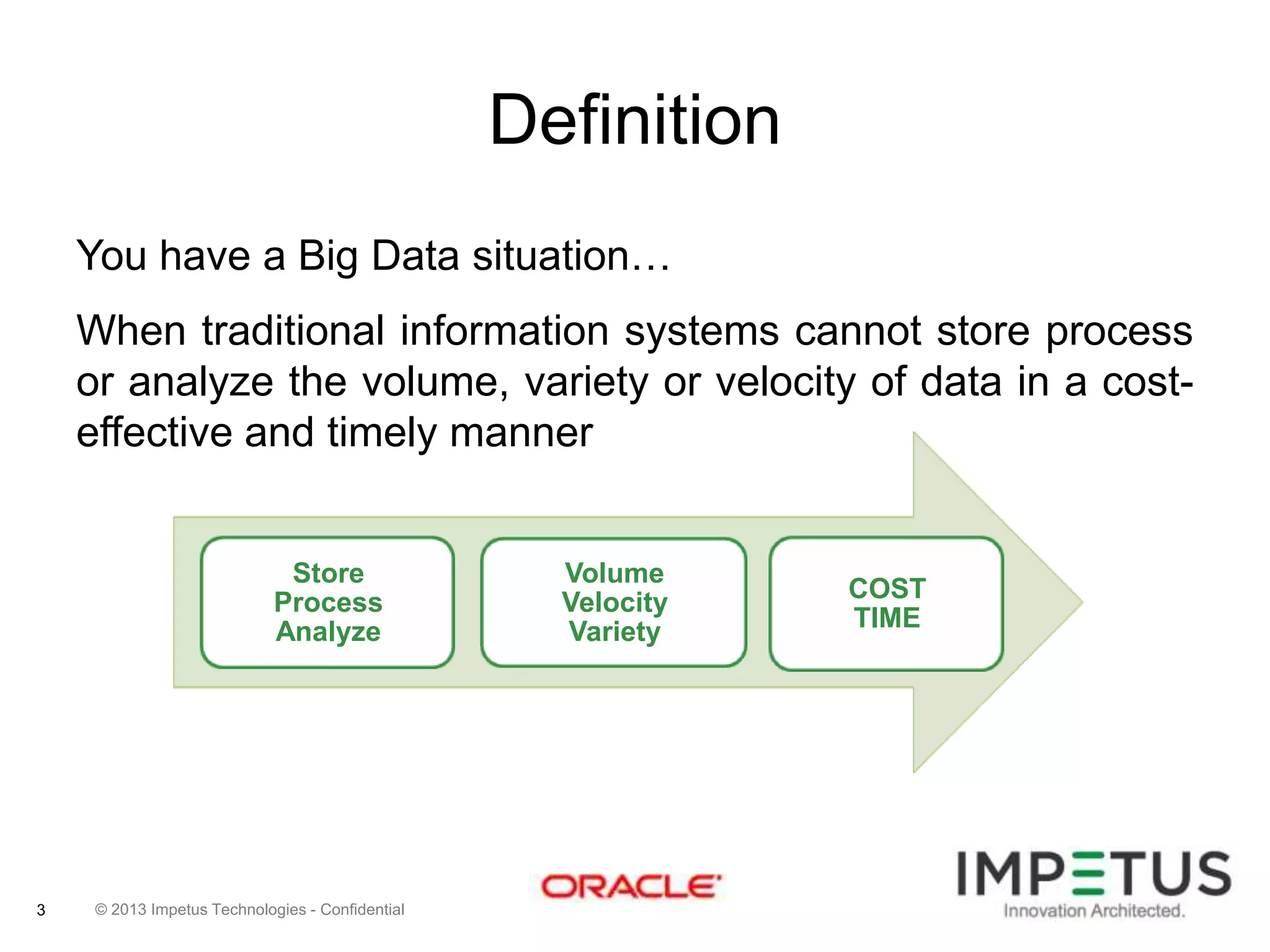








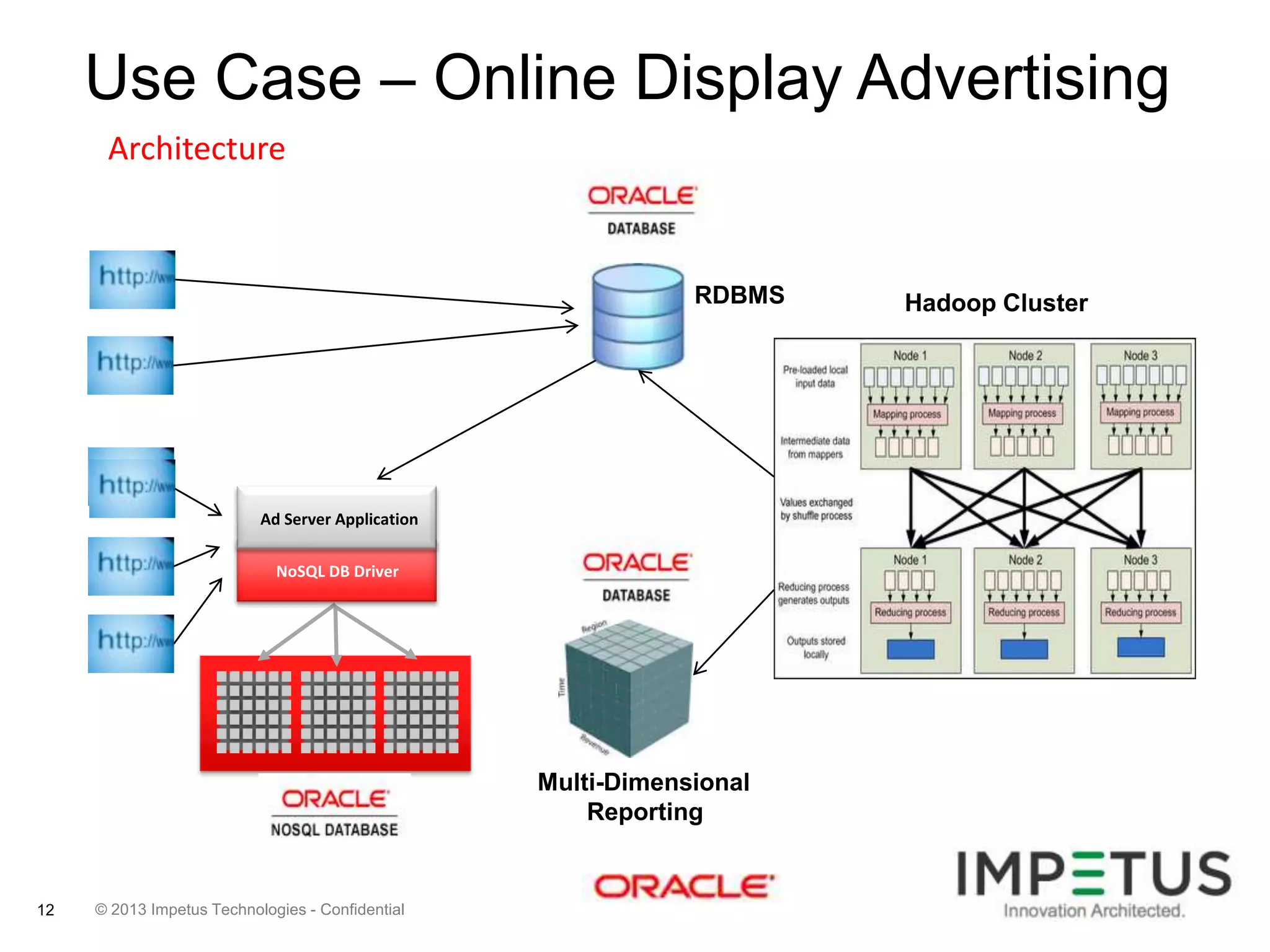
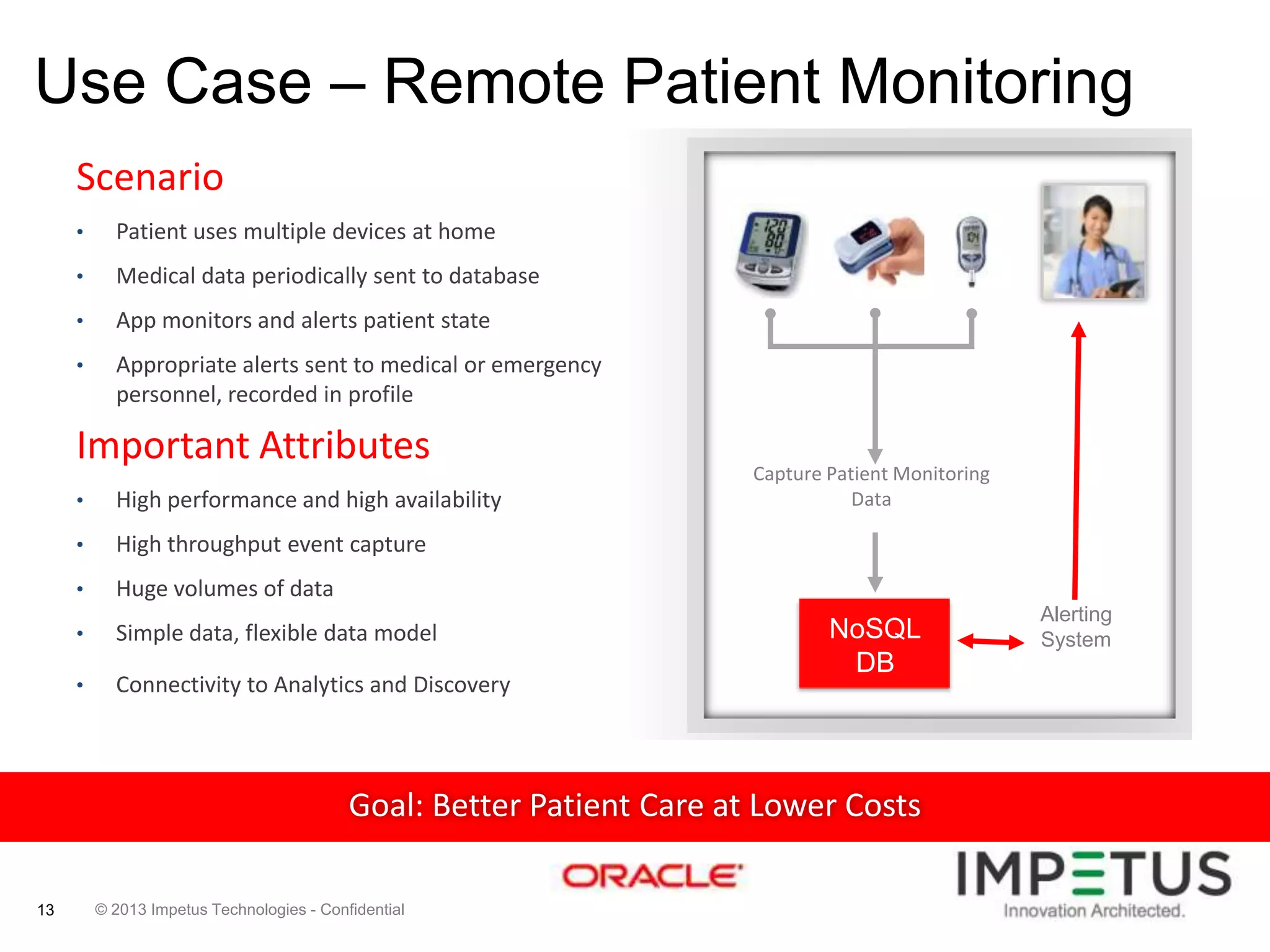

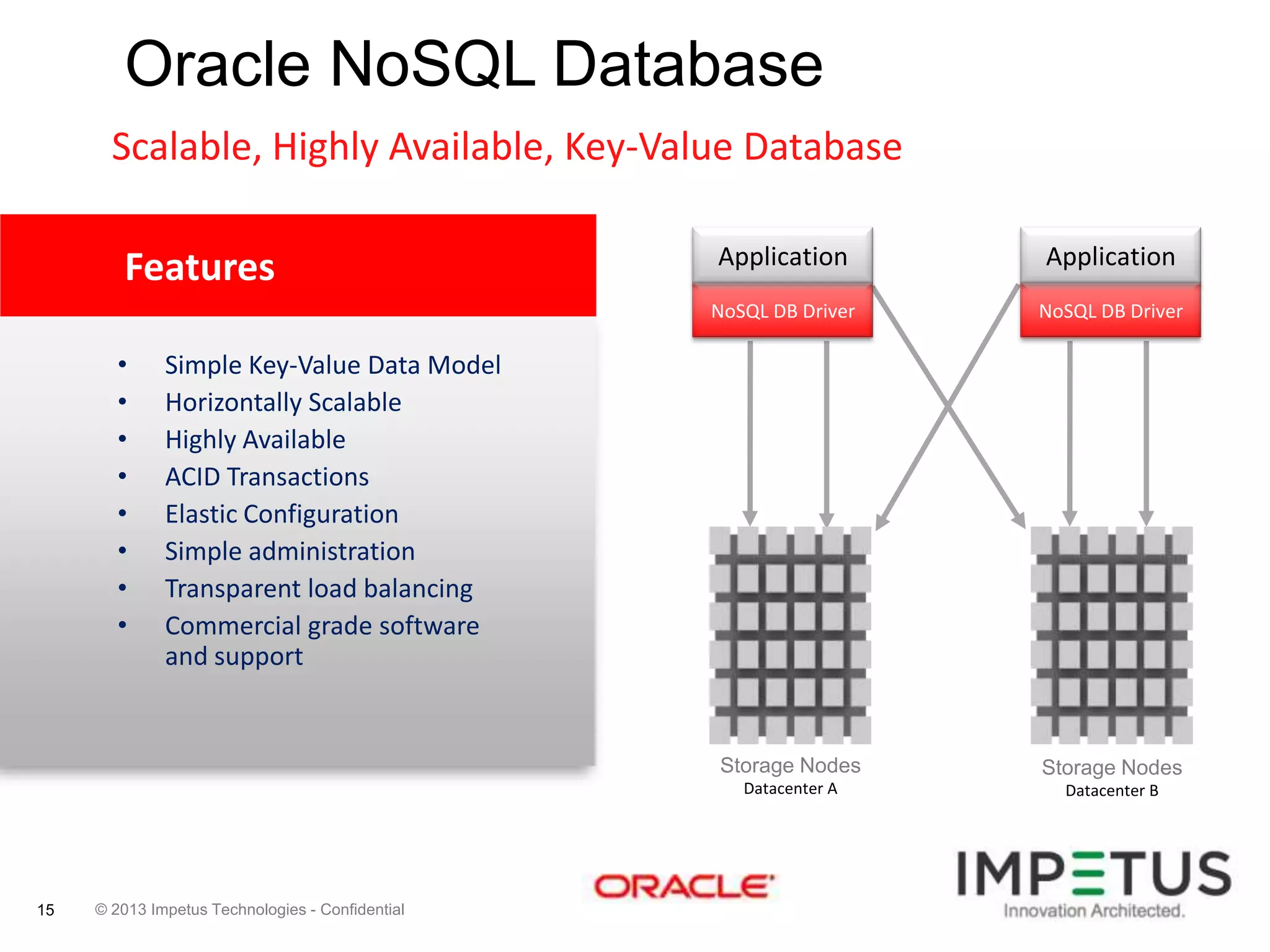
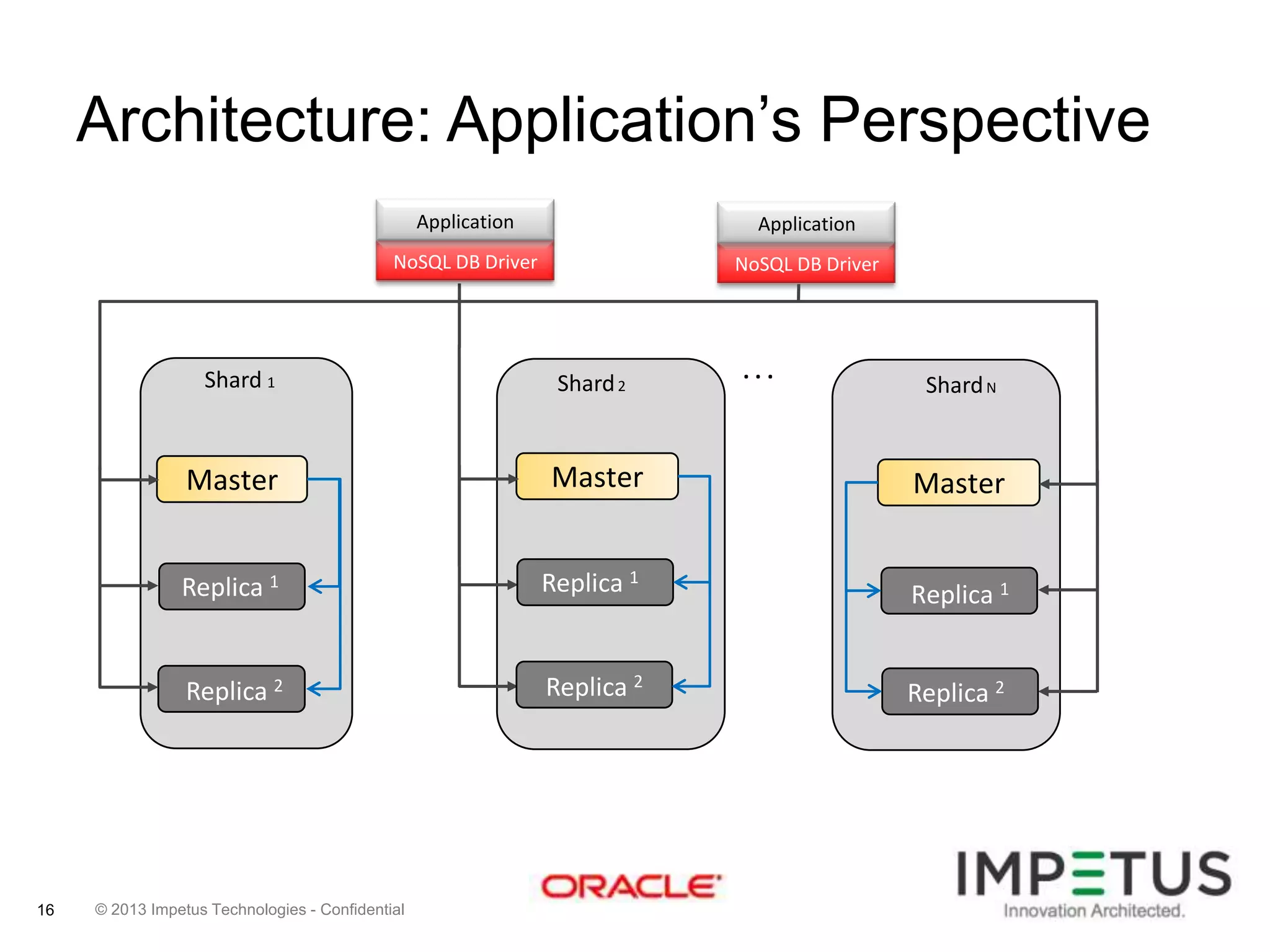
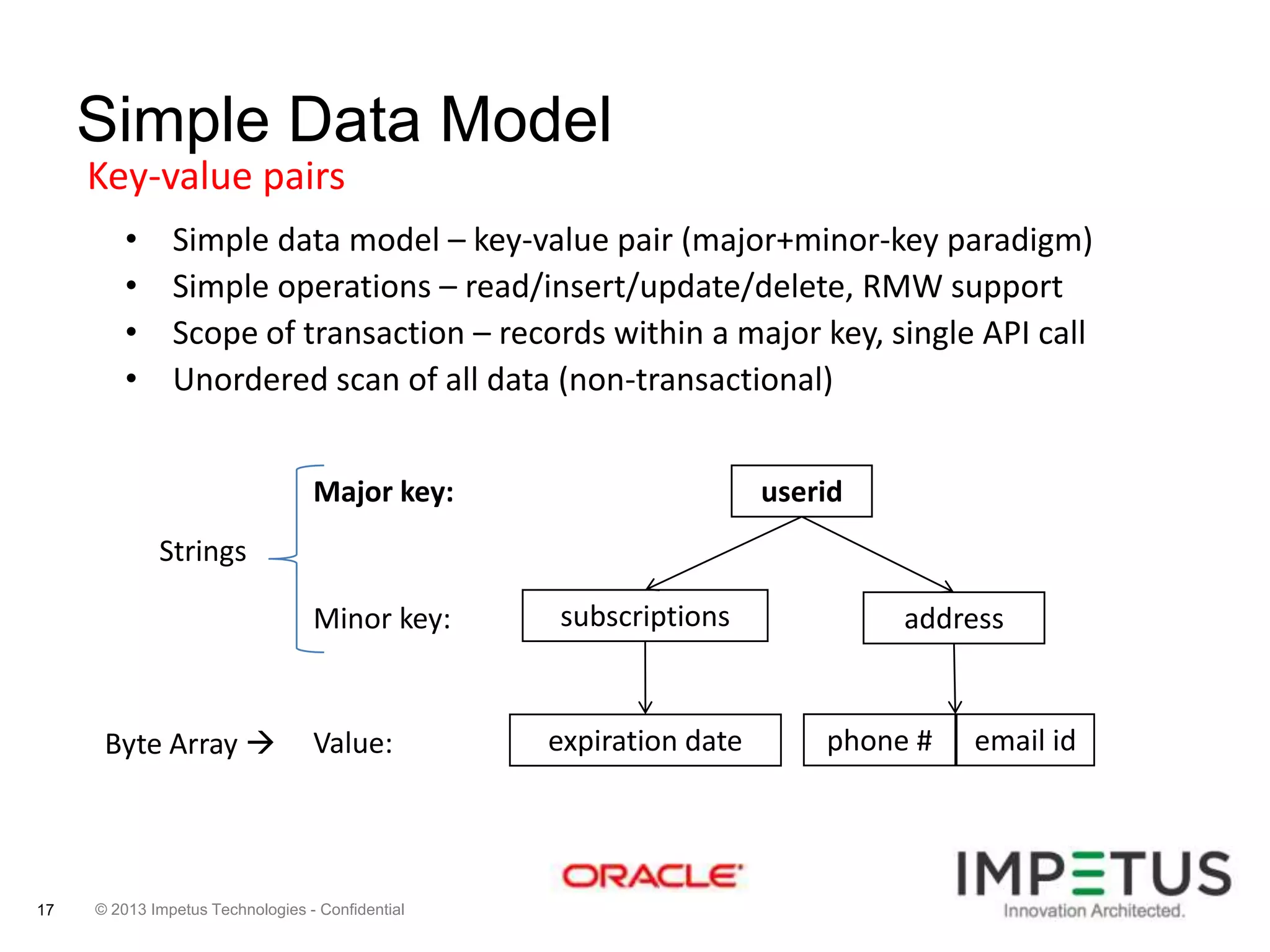
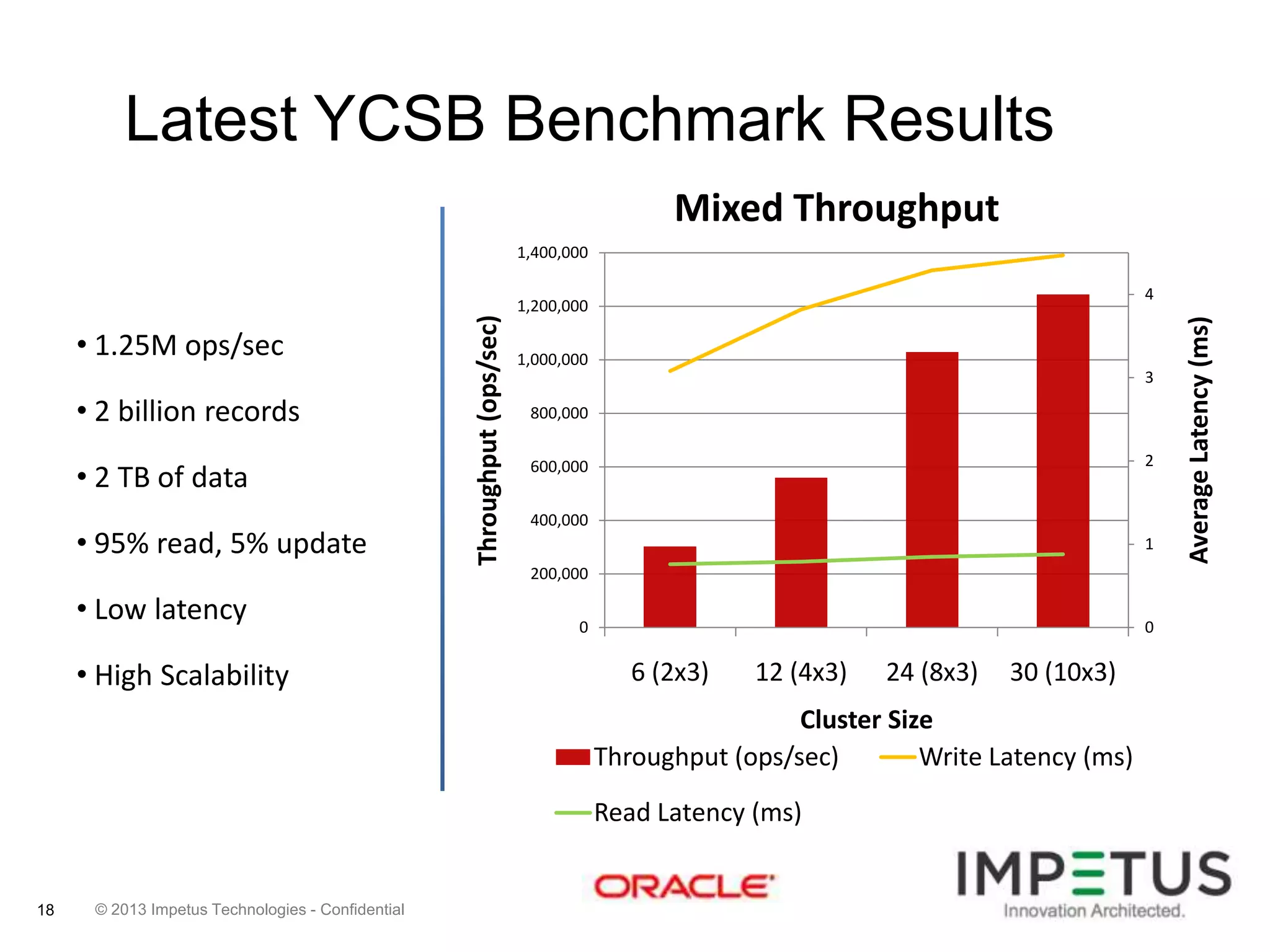








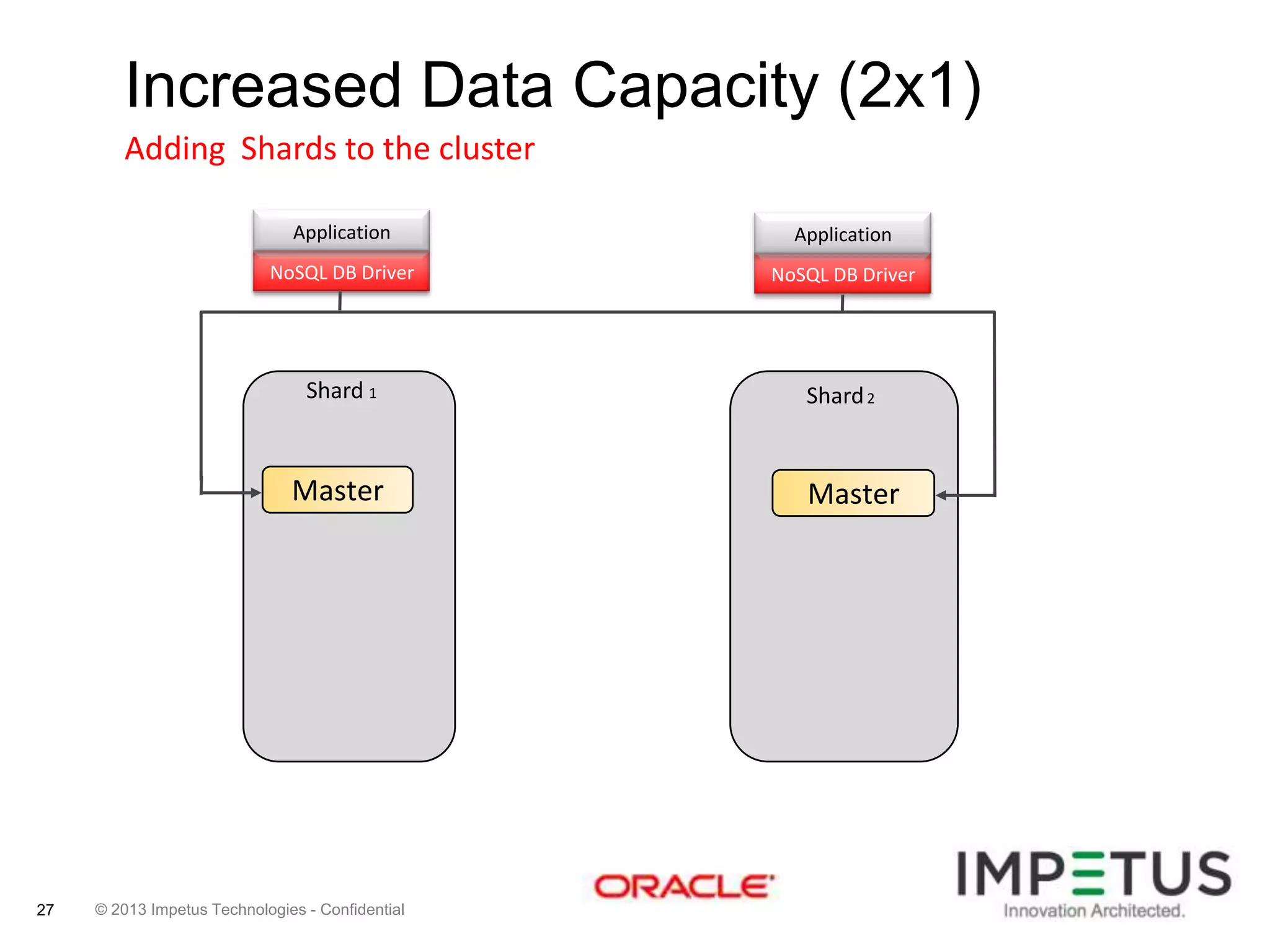
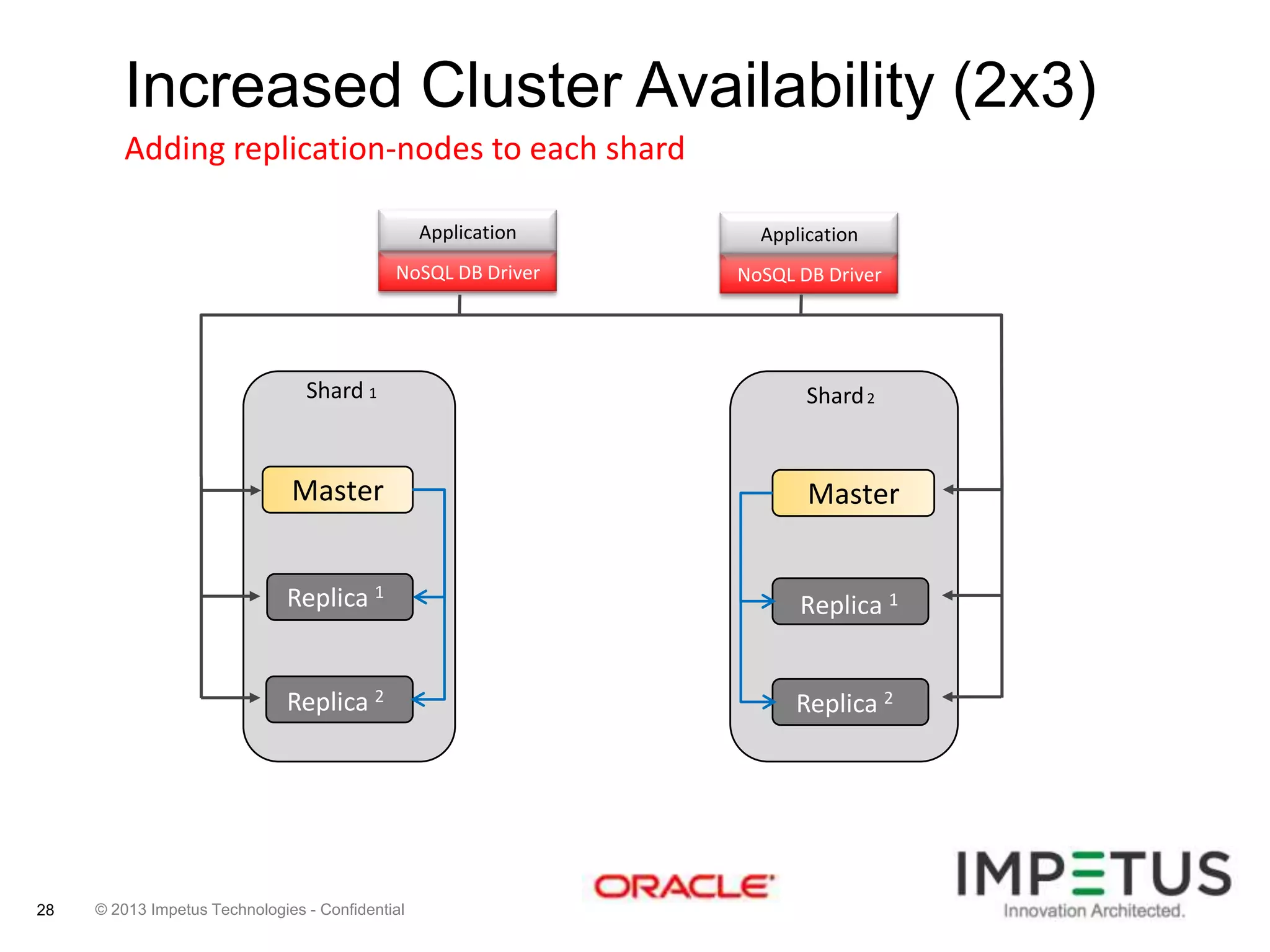



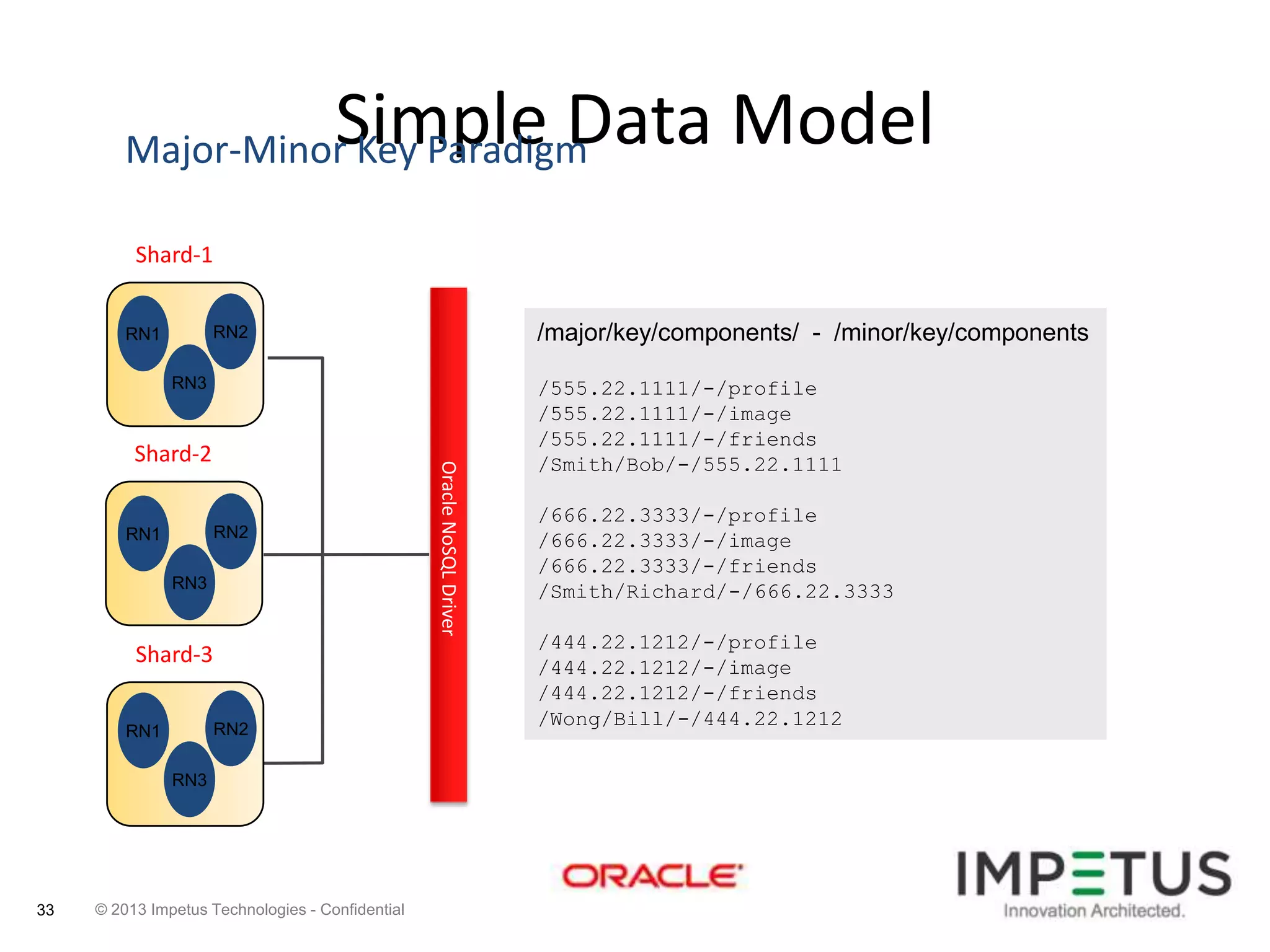
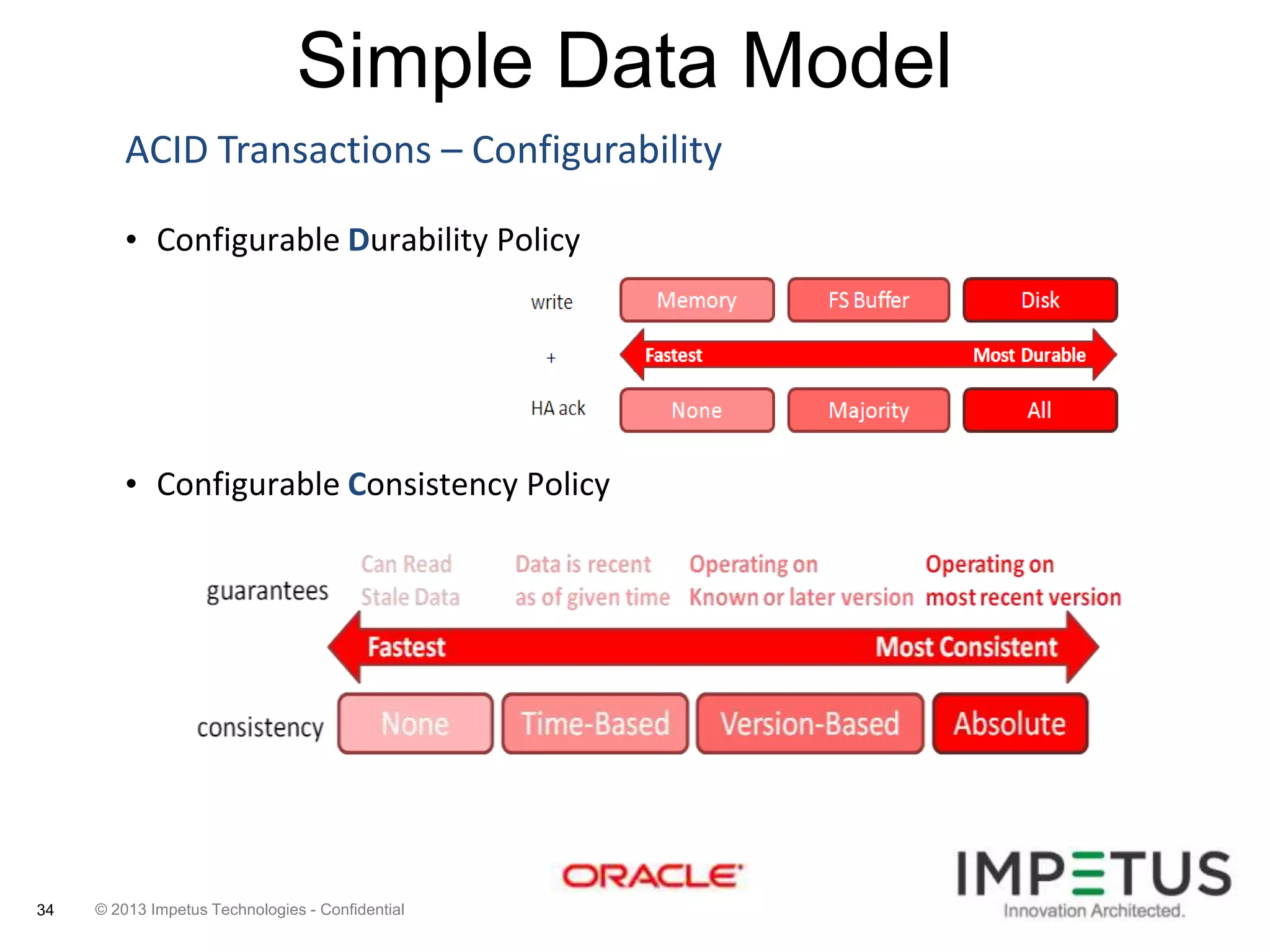

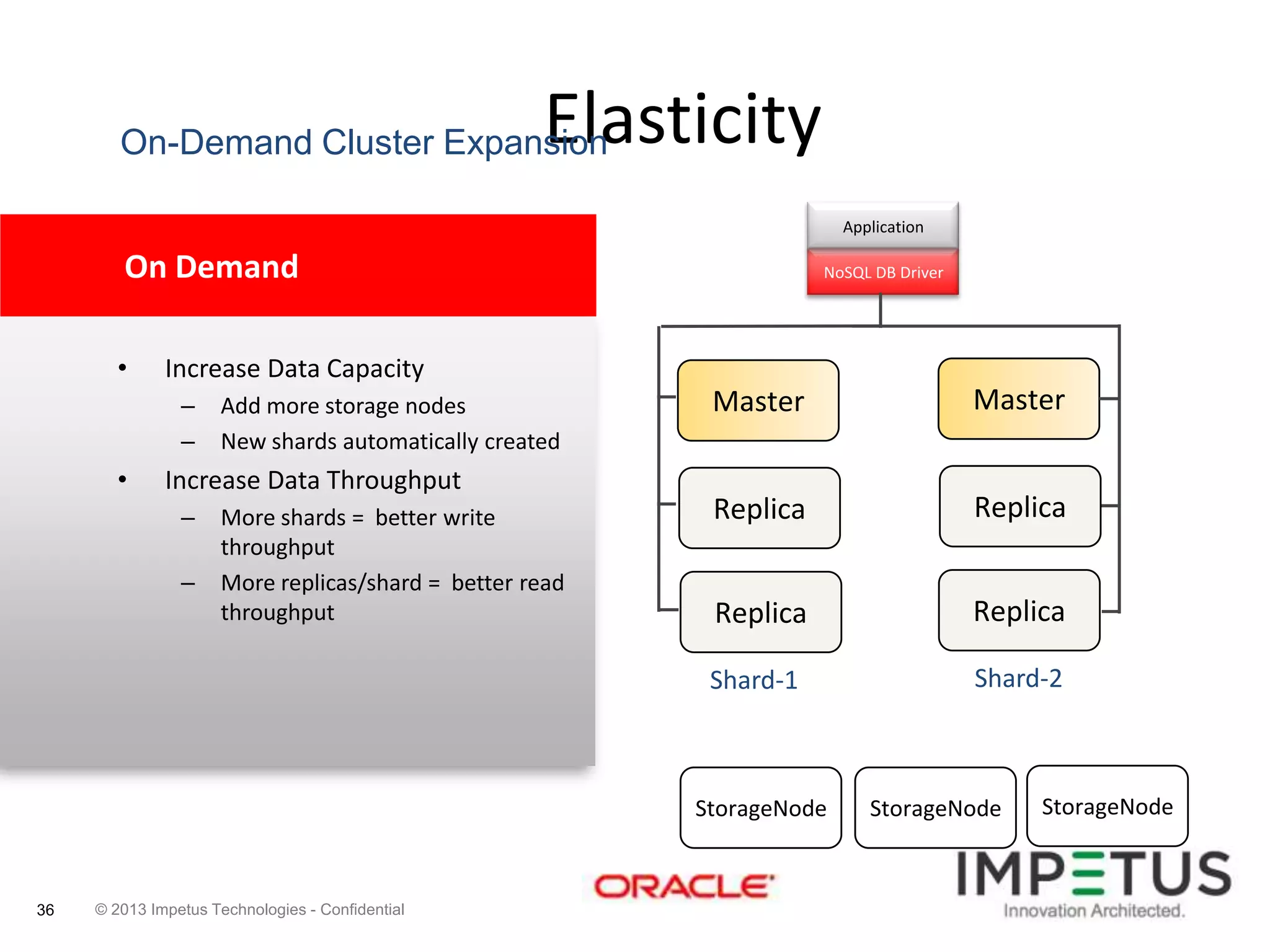
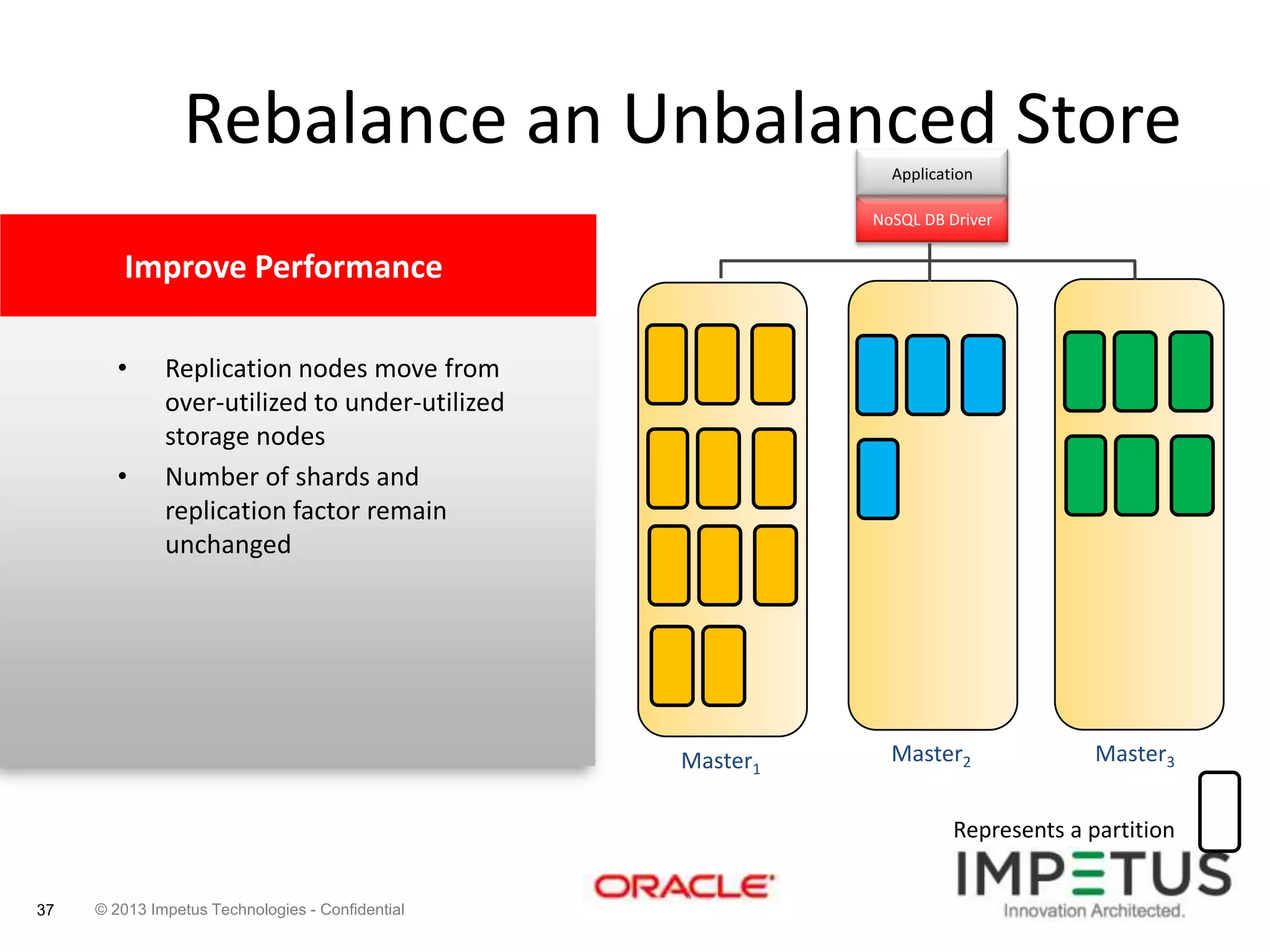



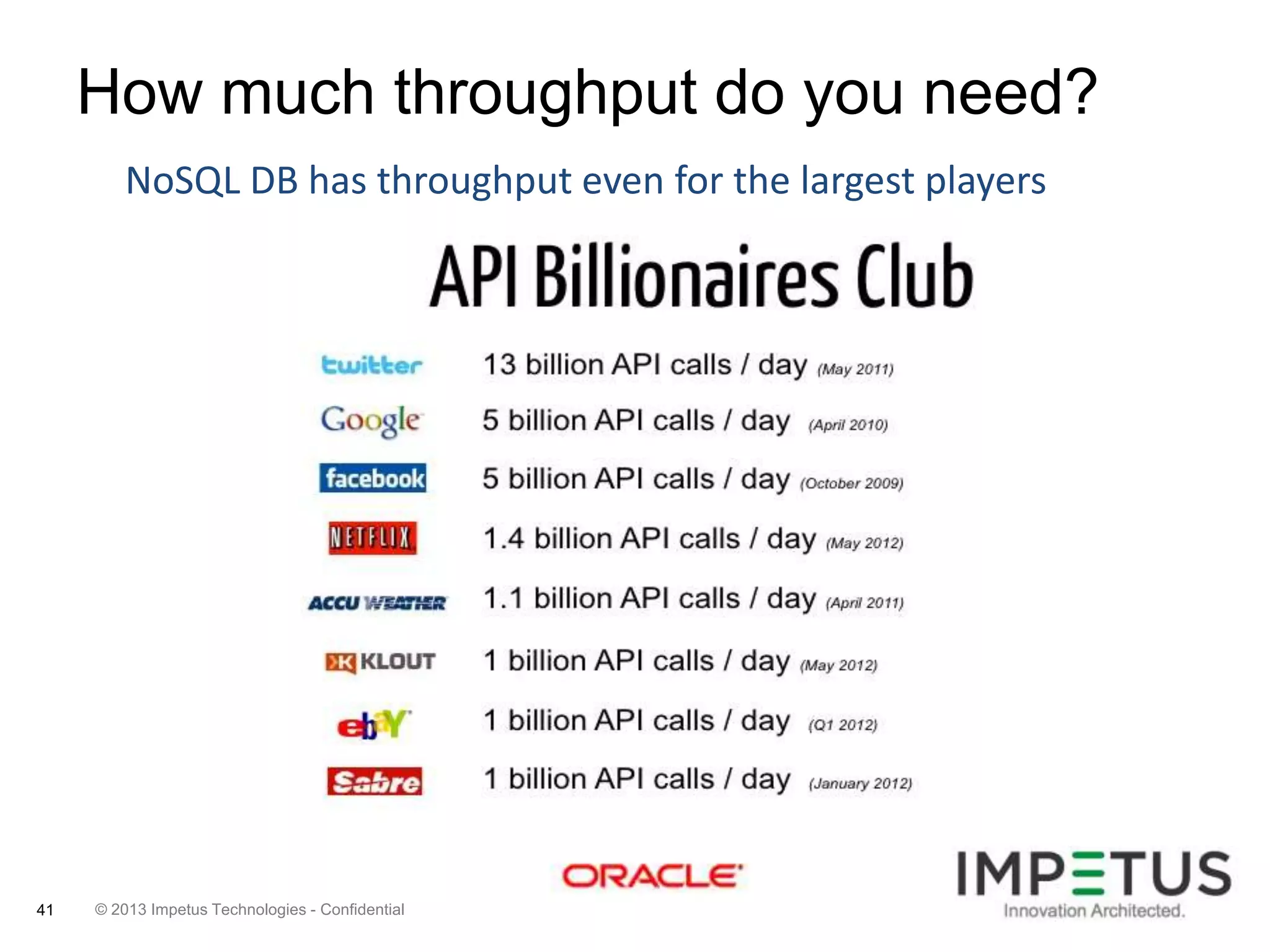
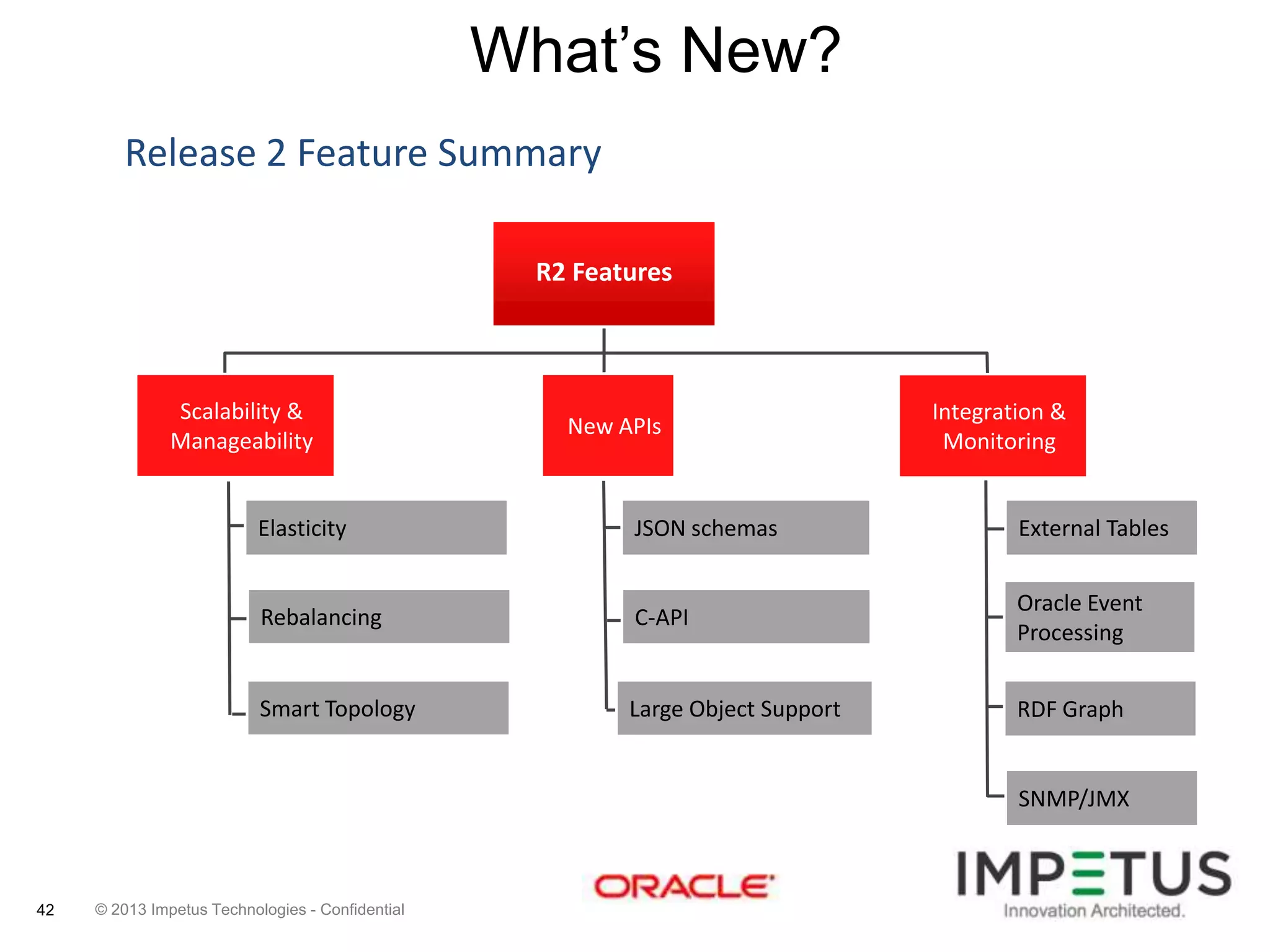


The document provides an overview of deploying and managing the Oracle NoSQL database and Hadoop clusters, highlighting the significance of big data and NoSQL in addressing challenges related to data volume, velocity, and variety. It outlines various use cases across different industries, the capabilities of Oracle NoSQL, and presents the Ankush tool for big data cluster management. The NoSQL database is characterized by high availability, scalability, and a simple key-value data model, integrating with other Oracle products for enhanced functionality.











































































































