Downloaded 43 times


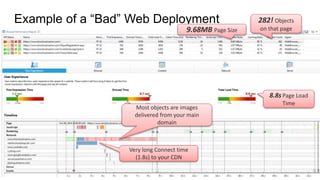


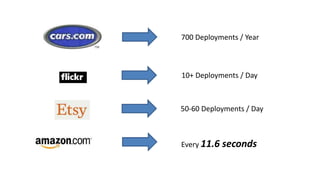




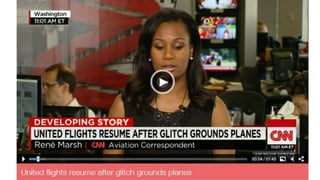
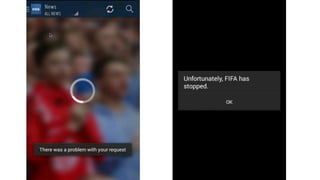

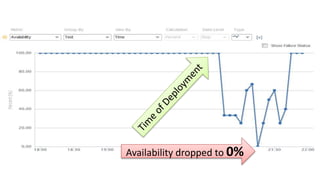
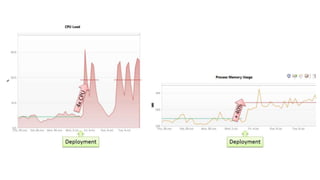
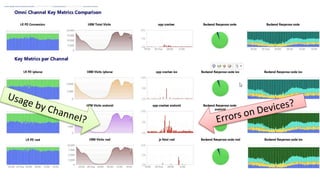


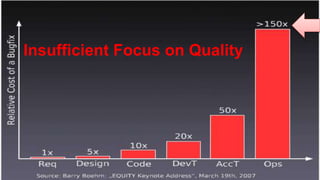











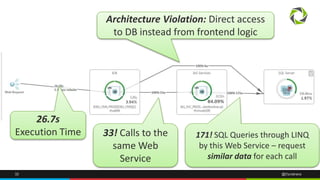



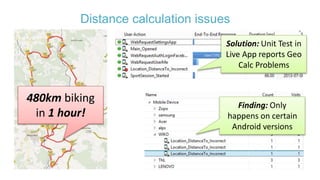
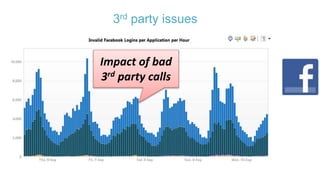



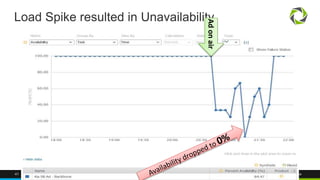
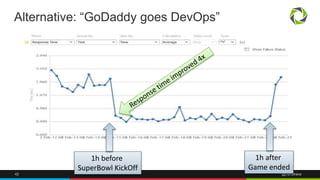






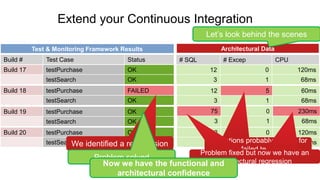
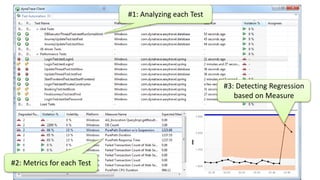
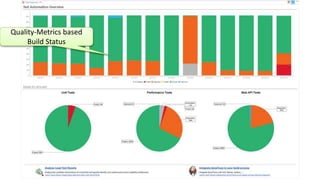
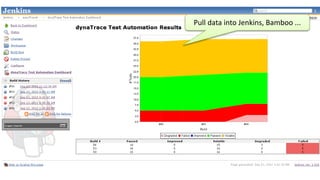

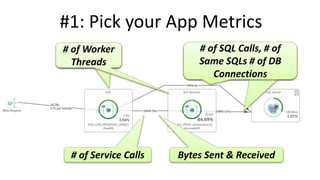







The document discusses best practices for application quality in software deployments, emphasizing the importance of metrics and learning from past mistakes. It provides examples of poor performance in web and Java deployments and outlines strategies to improve quality, such as avoiding blind automation and integrating comprehensive metrics into the CI/CD pipeline. Key takeaways include focusing on resource management, monitoring third-party calls, and addressing architectural issues to enhance application performance.





























































































![20260201 [FOSDEM] gomodjail - library sandboxing for Go modules.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/20260201fosdemgomodjail-librarysandboxingforgomodules-260201225659-76609ec4-thumbnail.jpg?width=640&height=640&fit=bounds)







