Downloaded 75 times















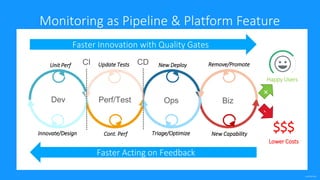


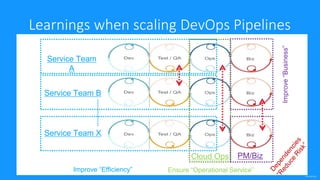


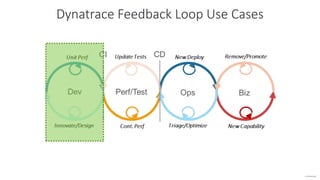

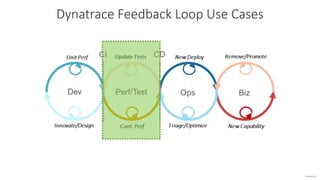

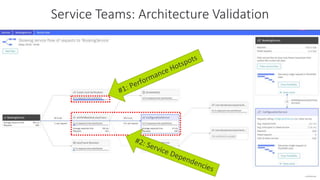


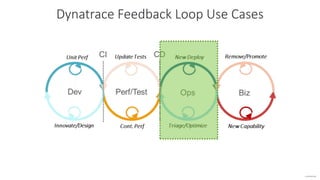

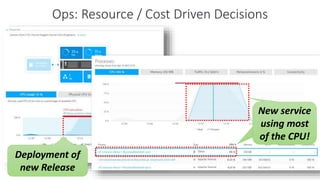

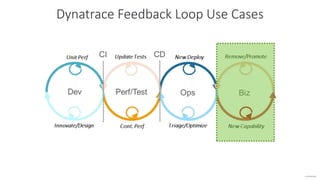
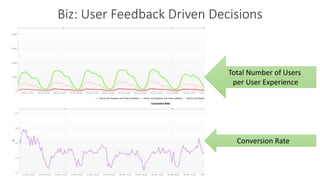
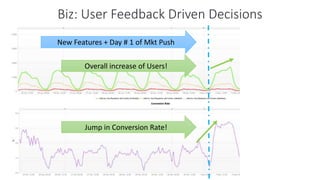
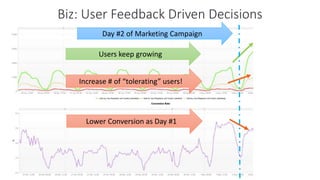
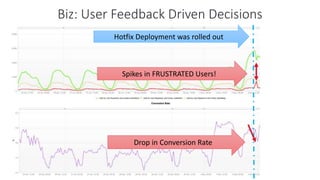
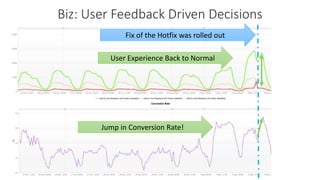
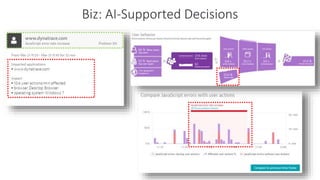

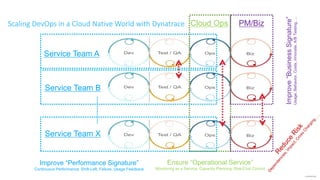



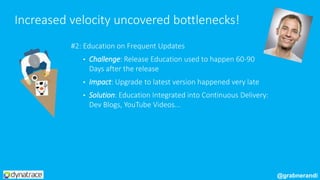


The document outlines Dynatrace's DevOps transformation journey, highlighting their transition from traditional software deployment methods to continuous innovation through automation and cultural shifts. Key achievements include significantly increased release frequency and deployment velocity, enhanced collaboration among teams, and improved product quality and stability. The document also discusses challenges faced, strategic solutions implemented, and the importance of integrating customer feedback into the development process.























































































