Download as PDF, PPTX
![NSCC High
Performance
Computing Cluster
Introduction
[19-Feb-2016]](https://image.slidesharecdn.com/nscctrainingintroductoryclass-160220025421/85/NSCC-Training-Introductory-Class-1-320.jpg)








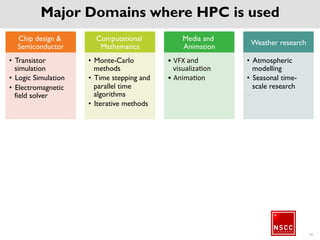



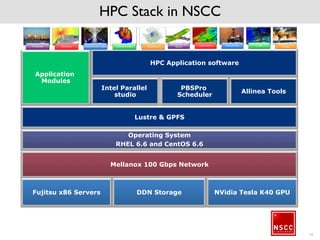
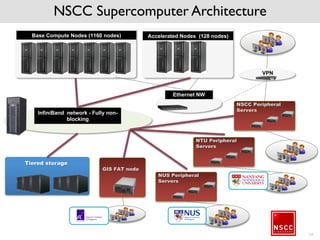
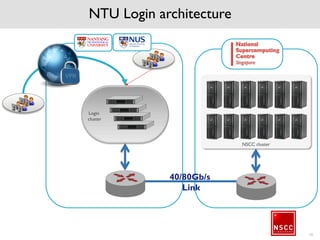

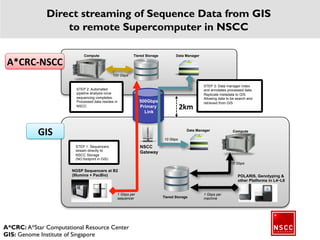

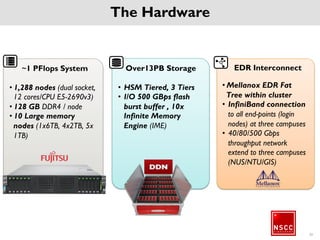



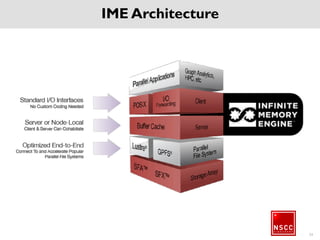
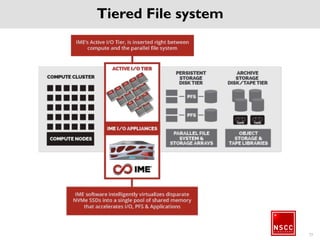
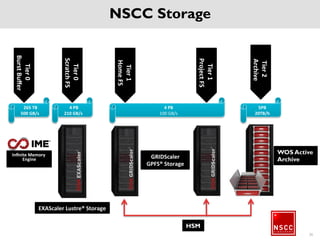
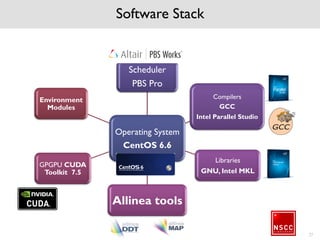



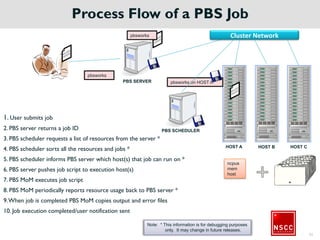
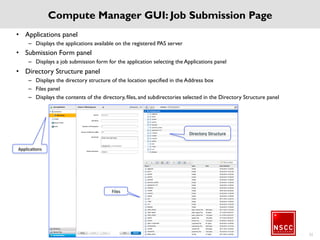
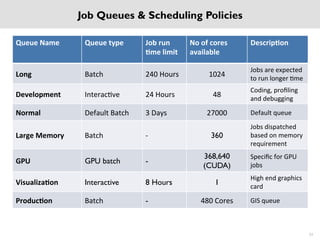
























The National Supercomputing Centre (NSCC) provides a high performance computing cluster to support national research and development initiatives, attract industrial research collaborations, and enhance Singapore's research capabilities. The NSCC computing cluster includes over 1,288 nodes with a total of approximately 1 petaflop of processing power, over 13 petabytes of storage, and specialized nodes with GPUs and large memory. Users can access the cluster resources through a scheduler called PBS Pro which manages job queues, scheduling, and resource allocation.



















![[Hadoop Meetup] Yarn at Microsoft - The challenges of scale](https://cdn.slidesharecdn.com/ss_thumbnails/yarnatmicrosoft-171222065628-thumbnail.jpg?width=640&height=640&fit=bounds)








































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)











