Downloaded 44 times








![Broadcast Stream
Task-
0
Task-
1
Task-
2
Task-
3
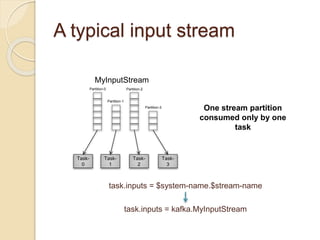
MyInputStream
Partition-0
Partition-1
Partition-2
Partition-3
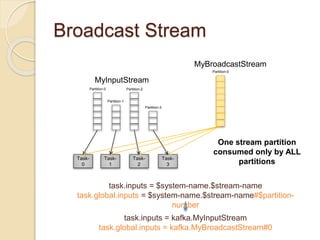
MyBroadcastStream
Partition-0 Partition-1 Partition-2
task.inputs = $system-name.$stream-name
task.global.inputs = $system-name.$stream-name#[$partition-
range]
task.inputs = kafka.MyInputStream
task.global.inputs = kafka.MyBroadcastStream#[0-1]](https://image.slidesharecdn.com/apachesamzameetupoct2015-151014203219-lva1-app6892/85/Apache-Samza-New-features-in-the-upcoming-Samza-release-0-10-0-14-320.jpg)

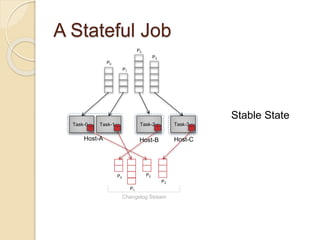

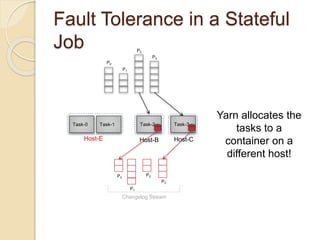
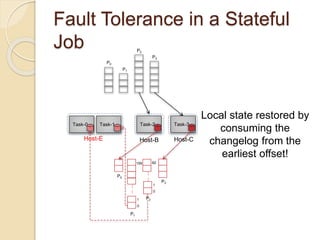

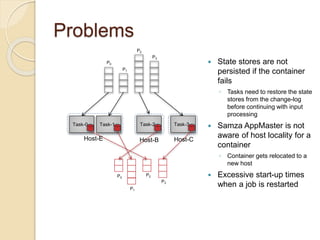


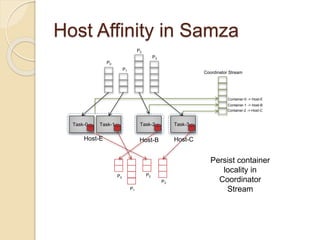
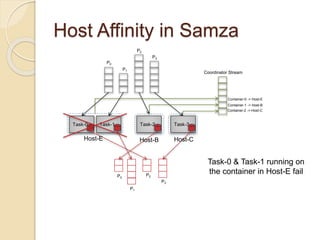
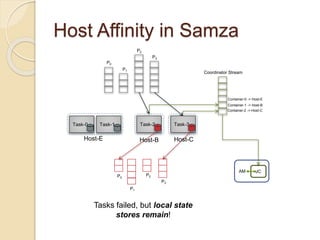
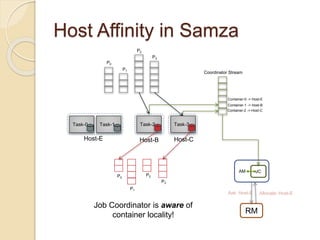
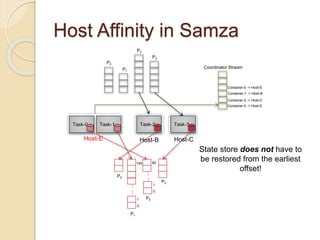
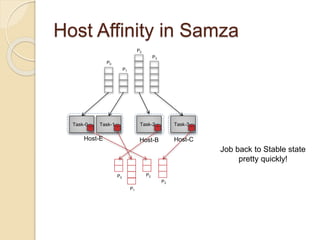







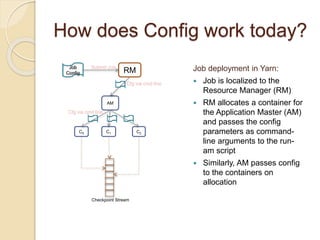
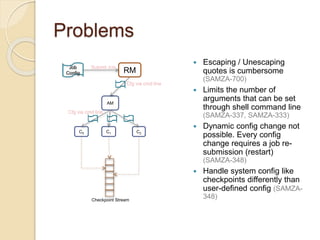
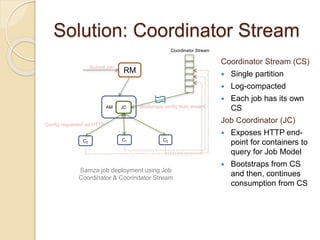
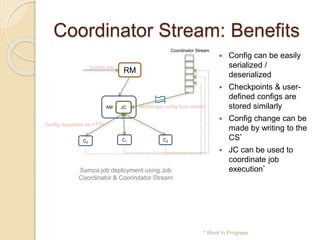
The document summarizes new features in the upcoming Samza 0.10.0 release, including dynamic configuration and control using a coordinator stream and broadcast stream, host affinity to improve fault tolerance in stateful jobs, new Kinesis consumer and Kinesis/HDFS/ElasticSearch producers, and an upgraded RocksDB with TTL support.


























































