Downloaded 95 times







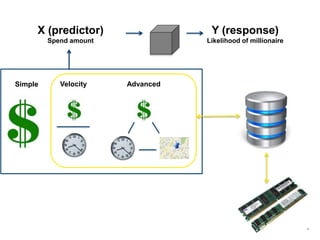






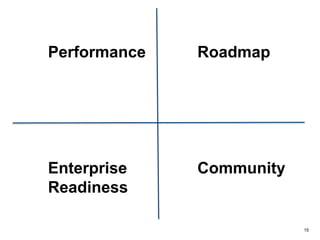

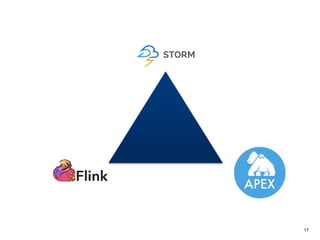




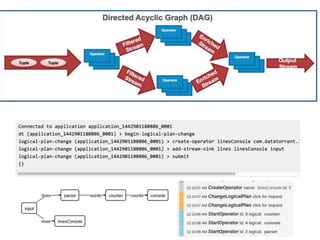
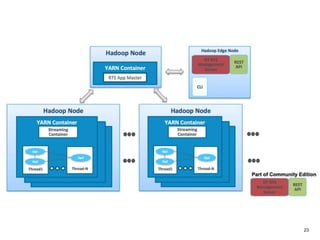
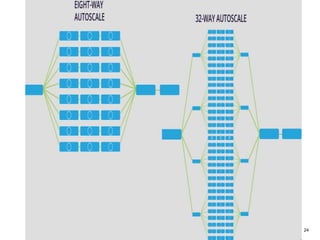
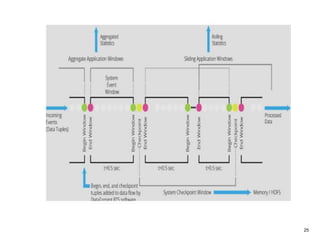










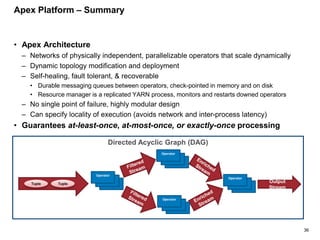
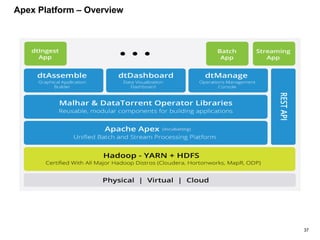
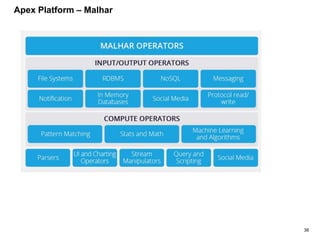
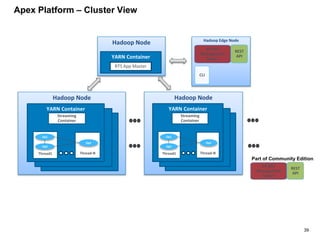
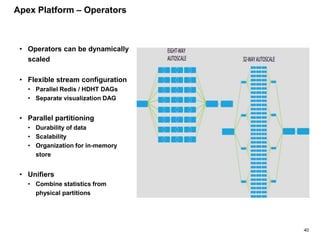
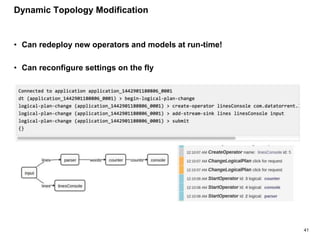

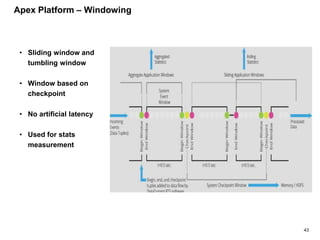












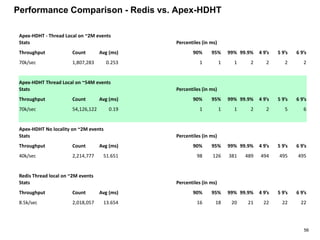

The document outlines a next-generation decision-making system that achieves sub-2ms latency and 99.999% uptime through a highly scalable and fault-tolerant architecture. It evaluates several streaming technologies, concluding that Apache Apex is the most suitable solution due to its maturity, performance, and enterprise readiness. The system incorporates advanced capabilities such as dynamic scalability, live model refresh, and A/B model testing to enhance decision-making efficiency.



































































